") 一種新穎而高效的增強(qiáng)校準(zhǔn)度量方法用于二值前景圖的評(píng)估
一種新穎而高效的增強(qiáng)校準(zhǔn)度量方法用于二值前景圖的評(píng)估
圖像分割是以人眼識(shí)別為基礎(chǔ),而人眼識(shí)別是從整體到局部的分割方式。本文首次提出了一種模擬人眼判別的新指標(biāo),結(jié)果遠(yuǎn)優(yōu)于現(xiàn)有方法,并證明其與人眼判別結(jié)果更加一致。
圖像分割往往是以人眼識(shí)別為基礎(chǔ)的,而人眼識(shí)別是從整體到局部的分割方式。本文從整體和局部?jī)蓚€(gè)方向出發(fā),提出了一種新穎而高效的增強(qiáng)校準(zhǔn)度量方法(E-measure)用于二值前景圖的評(píng)估, 通過簡(jiǎn)單地結(jié)合局部信息與全局信息得到了非常可靠的評(píng)價(jià)結(jié)果。
對(duì)于GT(GroundTruth,真值圖)與分割算法預(yù)測(cè)的FM (ForegroundMap,前景圖),圖像評(píng)價(jià)指標(biāo)的意義即為計(jì)算FM與GT的相似度,為介于0-1之間的值(可以看作概率),1表示完全一樣,而0則根據(jù)不同的算法有不同的結(jié)果,認(rèn)為是完全不一樣(或者與GT正好相反)。GT往往是研究人員手工標(biāo)注的,
一般認(rèn)為GT代表的是人眼分割的結(jié)果。而評(píng)價(jià)指標(biāo)算法的目標(biāo),就是取得跟人眼進(jìn)行圖像分類一樣的結(jié)果。而目前廣泛使用的IOU是基于局部信息的誤差度量(像素級(jí)別),而忽略了圖像的全局信息,從而導(dǎo)致其評(píng)估不準(zhǔn)確。
E-measure是基于局部像素信息差別與全局均值信息的評(píng)估方法,我們?cè)?個(gè)基準(zhǔn)數(shù)據(jù)集上采用5個(gè)元度量證明了E-measure遠(yuǎn)遠(yuǎn)優(yōu)于已有的度量方法,并且在我們提出的人眼排序數(shù)據(jù)集上取得了最好的結(jié)果,證明其與和人的主觀評(píng)價(jià)具有高度一致性。
問題引出:管中窺豹,只可見一斑
評(píng)價(jià)指標(biāo)的合理與否對(duì)一個(gè)領(lǐng)域中模型的發(fā)展起到?jīng)Q定性的作用,現(xiàn)有的前景圖檢測(cè)中應(yīng)用最廣泛的評(píng)價(jià)指標(biāo)為IOU(Intersection-Over-Union,交并集),如圖1, IOU的公式可表示為公式1。
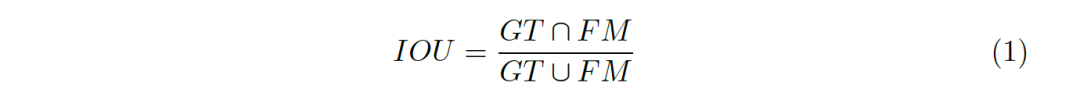
圖1:IOU的形象化表示
不難看出IOU是基于局部像素差異的評(píng)估方法,缺失了全局信息。如圖2所示,(d)中所示不過是噪聲圖,很明顯(c)中的圖與(b) 中GT更相似,而(d)實(shí)際上可能只與全白或者全黑的前景圖結(jié)果差不多,而對(duì)于全白或全黑圖,我們可以認(rèn)為是不相似的(但是并非相似度值為0,事實(shí)上為0一般表示完全相反)。而在通過IOU算法的結(jié)果卻告訴我們,(d)比(c)更好!這顯然是不合理的。
圖2:不同類型前景圖FM的評(píng)價(jià)對(duì)比
只基于局部像素差異對(duì)計(jì)算機(jī)來說或許是有效的,但是不符合人眼分割圖像的機(jī)制。我們來實(shí)驗(yàn)分析一個(gè)簡(jiǎn)單的例子,如圖3,藍(lán)色范圍為GT,紅色為FM。可以看出,(a)和(b)的FM形狀差別很大,但是其與GT的交卻完全一樣,導(dǎo)致得到完全一樣的結(jié)果。
圖3:IOU簡(jiǎn)單分析,藍(lán)色范圍為GT,紅色為檢FM,(a)與(b)中交集面積一樣
因?yàn)镮OU只基于局部像素差異進(jìn)行評(píng)估,導(dǎo)致其只能得到一個(gè)局部最優(yōu)結(jié)果,而很難得到全面的評(píng)估結(jié)果。我們需要一個(gè)全面的,符合人眼視覺的評(píng)價(jià)指標(biāo)。
解決方案:眼觀六路,耳聽八方
由于當(dāng)前的評(píng)價(jià)指標(biāo)都是考慮單個(gè)像素點(diǎn)的誤差,缺少全局信息的考量,從而導(dǎo)致評(píng)估不準(zhǔn)確。為此,我們考慮將局部信息與全局信息結(jié)合進(jìn)行度量。
圖4:(b)是原始圖像(a)的分割結(jié)果,Map1(c)和Map2(d)分別為兩個(gè)算法分割的結(jié)果
我們先來看一個(gè)例子,從圖4中兩個(gè)分割算法檢測(cè)的結(jié)果Map1和Map2中,我們判斷其結(jié)果與GT的相似度會(huì)考慮到全局的相似度,如整個(gè)鹿的身體部分。通過這一判斷,感知兩者的相似度差異較小。進(jìn)而進(jìn)行局部的細(xì)節(jié)判斷(見圖 5})。我們發(fā)現(xiàn)與Map1相比,Map2分割結(jié)果包含了更多細(xì)節(jié)(腳),從而,如圖 6所示,我們會(huì)認(rèn)為Map2的的分割結(jié)果優(yōu)于Map1。
圖5:(b)是原始圖像(a)的分割結(jié)果,Map1(c)和Map2(d)分別為兩個(gè)算法分割的結(jié)果
圖6:(b)是原始圖像(a)的分割結(jié)果,Map1(c)和Map2(d)分別為兩個(gè)算法分割的結(jié)果
1、結(jié)合全局信息與局部信息
我們考慮將圖像級(jí)的統(tǒng)計(jì)信息納入考量范圍,選擇全局的像素均值μ作為圖像級(jí)的統(tǒng)計(jì)信息,因?yàn)槿志的艽韴D像全局的信息而且計(jì)算簡(jiǎn)單。如圖7中(c)(d)所示,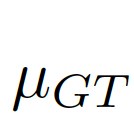
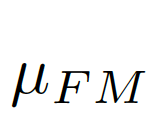
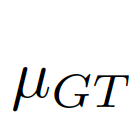 ,
,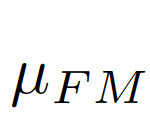 之差作為結(jié)合全局信息的偏差矩陣
之差作為結(jié)合全局信息的偏差矩陣
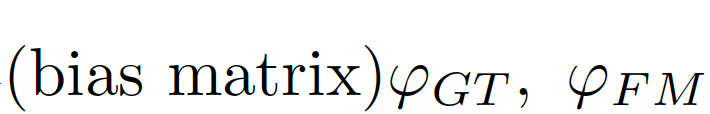
。
2、誤差估計(jì)
計(jì)算偏差矩陣(bias matrix)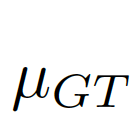
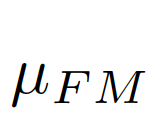
偏差矩陣為[0-1]之間的連續(xù)值,我們使用對(duì)齊矩陣(alignment matrix)ξ來評(píng)價(jià)偏差矩陣間的誤差:
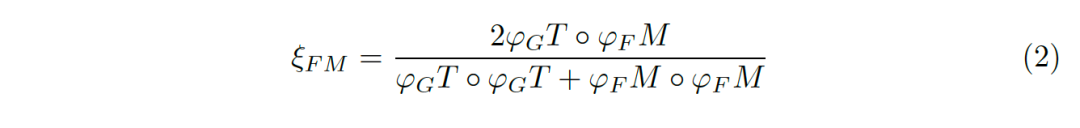
圖片7:結(jié)合全局信息與局部信息。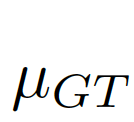
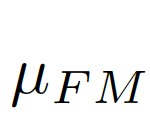
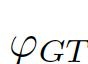 ,
,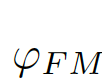 為結(jié)合全局信息與局部信息的偏差矩陣(bias matrix)
為結(jié)合全局信息與局部信息的偏差矩陣(bias matrix)
其中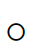 為哈達(dá)瑪乘,分子
為哈達(dá)瑪乘,分子
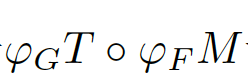
價(jià)誤差,而
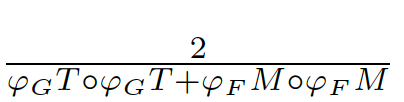
將評(píng)估結(jié)果縮放到[-1,1]之間,其中-1表示完全相反,而1表示完全相同。即對(duì)于每個(gè)包含全局信息的局部值誤差,我們可以計(jì)算出一個(gè)[-1,1]之間的誤差估計(jì)。
3、非線性變換
我們需要一個(gè)[0,1]之間的評(píng)價(jià)指標(biāo),因此需要將[-1,1]的值域縮放到[0,1]之間。對(duì)于一個(gè)隨機(jī)分類器輸出的二分類結(jié)果,即隨機(jī)生成的FM,其與GT的誤差應(yīng)該是均勻的,即其誤差應(yīng)該均勻地分布在[-1.1] 之間,這樣我們可以直接使用線性的變換將其值域縮放到[0,1](例如采用
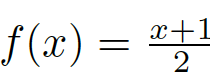
)。
但是事實(shí)上,所有的分類器應(yīng)該都要比隨機(jī)分類器要好得多,也就是說許多方法的輸出FM都是與GT相似而極少相反,即評(píng)價(jià)得分絕大部分集中于[0,1]之間而只有極少部分出現(xiàn)在[-1,0],在此情況下繼續(xù)采用線性函數(shù)進(jìn)行值域縮放就不再合適,因?yàn)檫@會(huì)導(dǎo)致絕大部分的結(jié)果集中到0.5以上的結(jié)果而導(dǎo)致缺乏區(qū)分度。其次,人眼評(píng)估的結(jié)果是評(píng)估FM與GT的相似度的,而非不相似度(或者負(fù)相似度),這也說明再使用線性縮放是不合適的。而簡(jiǎn)單地將所有[-1,0]之間的值置為0(如神經(jīng)網(wǎng)絡(luò)中非常著名的relu激活函數(shù))會(huì)丟失一些評(píng)估結(jié)果,因此不可取。
基于上述分析,我們提出非線性的變換函數(shù):
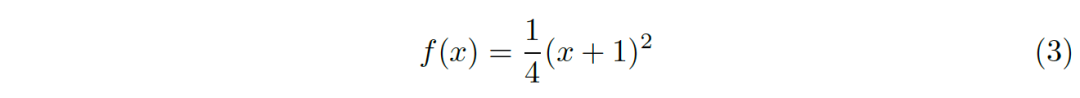
該函數(shù)其實(shí)只是對(duì)上述函數(shù)
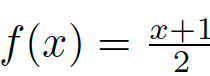
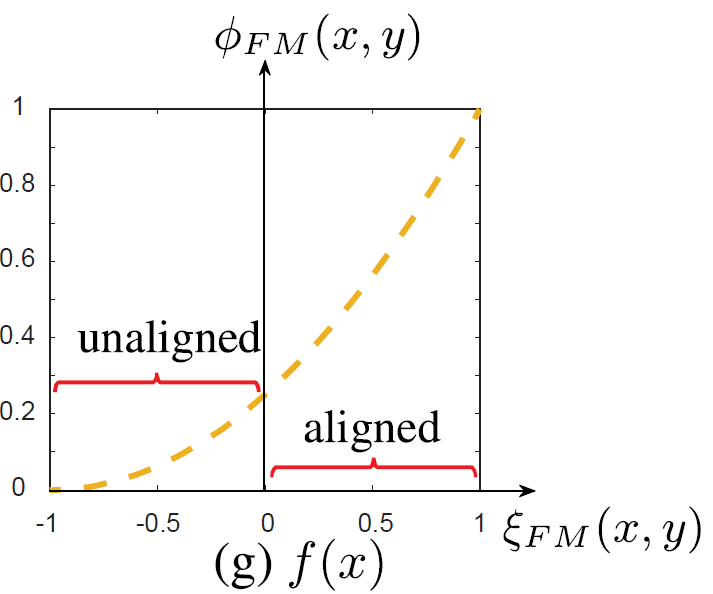
圖8:非線性變換函數(shù),其將[-1,0]之間的值縮放到一個(gè)較小的范圍,而將[0,1]之間的值縮放到較大的范圍
4、綜合估計(jì)
我們將所有的誤差縮放到[0,1]之間,便得到符合范圍的誤差結(jié)果(4):
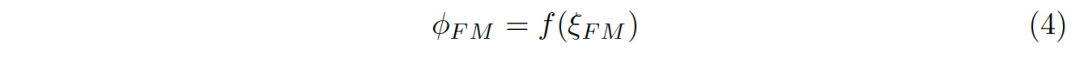
E-measure定義為所有位置誤差結(jié)果的綜合:
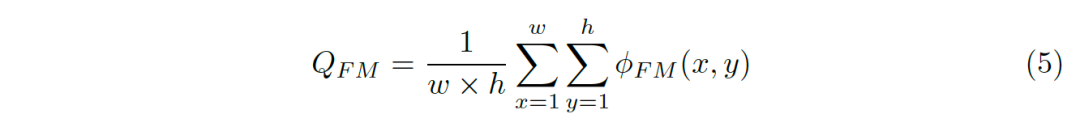
元度量實(shí)驗(yàn)證明有效性
為了證明指標(biāo)的有效性和可靠性,研究人員采用元度量的方法來進(jìn)行實(shí)驗(yàn)。通過提出一系列合理的假設(shè),然后驗(yàn)證指標(biāo)符合這些假設(shè)的程度就可以得到指標(biāo)的性能。簡(jiǎn)而言之,元度量就是一種評(píng)測(cè)指標(biāo)的指標(biāo)。實(shí)驗(yàn)采用了5個(gè)元度量:
元度量1:應(yīng)用排序
推動(dòng)模型發(fā)展的一個(gè)重要原因就是應(yīng)用需求,因此一個(gè)指標(biāo)的排序結(jié)果應(yīng)該和應(yīng)用的排序結(jié)果具有高度的一致性。即,將一系列前景圖輸入到應(yīng)用程序中,由應(yīng)用程序得到其標(biāo)準(zhǔn)前景圖的排序結(jié)果,一個(gè)優(yōu)秀的評(píng)價(jià)指標(biāo)得到的評(píng)價(jià)結(jié)果應(yīng)該與其應(yīng)用程序標(biāo)準(zhǔn)前景圖的排序結(jié)果具有高度一致性。如下圖9所示。
圖9
元度量2:最新水平 vs.通用結(jié)果
一個(gè)指標(biāo)的評(píng)價(jià)原則應(yīng)該傾向于選擇那些采用最先進(jìn)算法得到的檢測(cè)結(jié)果而不是那些沒有考慮圖像內(nèi)容的通用結(jié)果(例如中心高斯圖)。如下圖10所示。
圖10
元度量3:最新水平 vs.隨機(jī)結(jié)果
一個(gè)指標(biāo)的評(píng)價(jià)原則應(yīng)該傾向于選擇那些采用最先進(jìn)算法得到的檢測(cè)結(jié)果而不是那些沒有考慮圖像內(nèi)容的隨機(jī)結(jié)果(例如高斯噪聲圖)。如圖2所示。
元度量4:人工排序
人作為高級(jí)靈長(zhǎng)類動(dòng)物,擅長(zhǎng)捕捉對(duì)象的結(jié)構(gòu),因此前景圖檢測(cè)的評(píng)價(jià)指標(biāo)的排序結(jié)果,應(yīng)該和人的主觀排序具有高度一致性。我們通過從所有數(shù)據(jù)集中按比例,通過人隨機(jī)選擇符合人眼排序的前景圖組,組成人工排序數(shù)據(jù)集FMDatabase。如下圖11所示。
圖11
元度量5:參考GT隨機(jī)替換
原來指標(biāo)認(rèn)定為檢測(cè)結(jié)果較好的模型,在參考的Ground-truth替換為錯(cuò)誤的Ground-truth時(shí),分?jǐn)?shù)應(yīng)該降低。如圖12所示。
圖12
實(shí)驗(yàn)結(jié)果
本文在5個(gè)具有不同特點(diǎn)的、具有挑戰(zhàn)性數(shù)據(jù)集上進(jìn)行了廣泛的測(cè)試,以驗(yàn)證指標(biāo)的穩(wěn)定性、魯棒性。

圖13
實(shí)驗(yàn)結(jié)果表明:我們的指標(biāo)分別在PASCAL, ECSSD, SOD 和HKU-IS數(shù)據(jù)集上具有更強(qiáng)的魯棒性和穩(wěn)定性。同時(shí)在FMDatabase(MM4)上,我們的指標(biāo)也具有最好的結(jié)果。
-
圖像分割
+關(guān)注
關(guān)注
4文章
182瀏覽量
18025 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24764
原文標(biāo)題:【圖像分割里程碑】南開提出首個(gè)人眼模擬分割指標(biāo),性能當(dāng)前最優(yōu)
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
實(shí)例分析:分享一種新穎實(shí)用的異常信號(hào)捕獲方法
基于助聽器開發(fā)的一種高效的語音增強(qiáng)神經(jīng)網(wǎng)絡(luò)
一種基于高效采樣算法的時(shí)序圖神經(jīng)網(wǎng)絡(luò)系統(tǒng)介紹
一種基于圖聚類的安全態(tài)勢(shì)評(píng)估方法
一種有效的文本圖像二值化方法
一種改進(jìn)的子空間語音增強(qiáng)方法
一種新穎的自適應(yīng)PWM逆變電源
一種新穎的開關(guān)電源設(shè)計(jì)方法
一種新穎的精密陀螺電源

一種新穎的鍵盤掃描方法與仿真實(shí)現(xiàn)
一種新穎的并聯(lián)有源電力濾波器死區(qū)補(bǔ)償方法_劉威葳
一種新穎、高效且易于計(jì)算的結(jié)構(gòu)性度量來評(píng)估非二進(jìn)制前景圖

介紹一種基于中位數(shù)的離群值檢測(cè)方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論