 強化學習泡沫之后,人工智能的終極答案是什么?
強化學習泡沫之后,人工智能的終極答案是什么?
一、深度強化學習的泡沫
2015 年,DeepMind 的 Volodymyr Mnih 等研究員在《自然》雜志上發表論文 Human-level control through deep reinforcement learning[1],該論文提出了一個結合深度學習(DL)技術和強化學習(RL)思想的模型 Deep Q-Network(DQN),在 Atari 游戲平臺上展示出超越人類水平的表現。自此以后,結合 DL 與 RL 的深度強化學習(Deep Reinforcement Learning, DRL)迅速成為人工智能界的焦點。
過去三年間,DRL 算法在不同領域大顯神通:在視頻游戲 [1]、棋類游戲上打敗人類頂尖高手 [2,3];控制復雜的機械進行操作 [4];調配網絡資源 [5];為數據中心大幅節能 [6];甚至對機器學習算法自動調參 [7]。各大高校和企業紛紛參與其中,提出了眼花繚亂的 DRL 算法和應用。可以說,過去三年是 DRL 的爆紅期。DeepMind 負責 AlphaGo 項目的研究員 David Silver 喊出“AI = RL + DL”,認為結合了 DL 的表示能力與 RL 的推理能力的 DRL 將會是人工智能的終極答案。
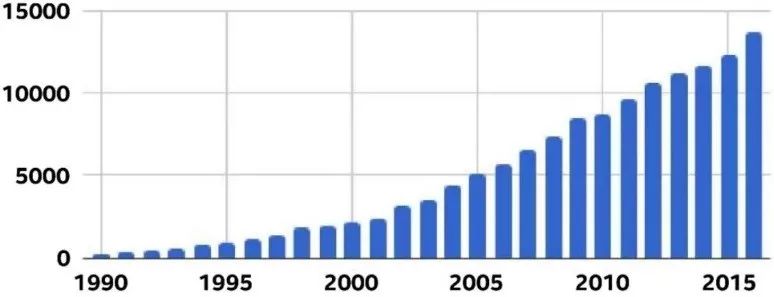
RL 論文數量迅速增長 [8]
1.1 DRL 的可復現性危機
然而,研究人員在最近半年開始了對 DRL 的反思。由于發表的文獻中往往不提供重要參數設置和工程解決方案的細節,很多算法都難以復現。2017 年 9 月,著名 RL 專家 Doina Precup 和 Joelle Pineau 所領導的的研究組發表了論文 Deep Reinforcement Learning that Matters[8],直指當前 DRL 領域論文數量多卻水分大、實驗難以復現等問題。該文在學術界和工業界引發熱烈反響。很多人對此表示認同,并對 DRL 的實際能力產生強烈懷疑。
其實,這并非 Precup& Pineau 研究組第一次對 DRL 發難。早在 2 個月前,該研究組就通過充足的實驗對造成 DRL 算法難以復現的多個要素加以研究,并將研究成果撰寫成文 Reproducibility of Benchmarked Deep Reinforcement Learning Tasks for Continuous Control[9]。同年 8 月,他們在 ICML 2017 上作了題為“Reproducibility of Policy Gradient Methods for Continuous Control”的報告 [10],通過實例詳細展示了在復現多個基于策略梯度的算法的過程中,由于種種不確定性因素導致的復現困難。12 月,在萬眾矚目的 NIPS 2017 DRL 專題研討會上,Joelle Pineau 受邀作了題為“Reproducibility of DRL and Beyond”的報告 [11]。報告中,Pineau 先介紹了當前科研領域的“可復現性危機” :在《自然》雜志的一項調查中,90% 的被訪者認為“可復現性”問題是科研領域存在的危機,其中,52% 的被訪者認為這個問題很嚴重。在另一項調查中,不同領域的研究者幾乎都有很高的比例無法復現他人甚至自己過去的實驗。可見“可復現性危機”有多么嚴峻!Pineau 針對機器學習領域發起的一項調研顯示,同樣有 90% 的研究者認識到了這個危機。
機器學習領域存在嚴重的“可復現性危機”[11]
隨后,針對 DRL 領域,Pineau 展示了該研究組對當前不同 DRL 算法的大量可復現性實驗。實驗結果表明,不同 DRL 算法在不同任務、不同超參數、不同隨機種子下的效果大相徑庭。在報告后半段,Pineau 呼吁學界關注“可復現性危機”這一問題,并根據她的調研結果,提出了 12 條檢驗算法“可復現性”的準則,宣布計劃在 ICLR 2018 開始舉辦“可復現實驗挑戰賽”(“可復現危機”在其他機器學習領域也受到了關注,ICML 2017 已經舉辦了 Reproducibility in Machine Learning Workshop,并將在今年繼續舉辦第二屆),旨在鼓勵研究者做出真正扎實的工作,抑制機器學習領域的泡沫。Pineau & Precup 研究組的這一系列研究獲得了廣泛關注。
Pineau 基于大量調查提出的檢驗算法“可復現性”準則 [11]
1.2 DRL 研究存在多少坑?
同樣在 12 月,Reddit 論壇上也開展了關于機器學習不正之風的熱烈討論 [12]。有人點名指出,某些 DRL 代表性算法之所以在模擬器中取得了優秀卻難以復現的表現,是因為作者們涉嫌在實驗中修改模擬器的物理模型,卻在論文中對此避而不談。
對現有 DRL 算法的批判浪潮仍舊不斷涌來。2018 年的情人節當天,曾經就讀于伯克利人工智能研究實驗室(Berkeley Artificial Intelligence Research Lab, BAIR)的 Alexirpan 通過一篇博文 Deep Reinforcement Learning Doesn't Work Yet[13] 給 DRL 圈送來了一份苦澀的禮物。他在文中通過多個例子,從實驗角度總結了 DRL 算法存在的幾大問題:
樣本利用率非常低;
最終表現不夠好,經常比不過基于模型的方法;
好的獎勵函數難以設計;
難以平衡“探索”和“利用”, 以致算法陷入局部極小;
對環境的過擬合;
災難性的不穩定性…
雖然作者在文章結尾試著提出 DRL 下一步應該解決的一系列問題,很多人還是把這篇文章看做 DRL 的“勸退文”。幾天后,GIT 的博士生 Himanshu Sahni 發表博文 Reinforcement Learning never worked, and 'deep' only helped a bit 與之呼應 [14],在贊同 Alexirpan 的觀點同時,指出好的獎勵函數難以設計和難以平衡“探索”和“利用”以致算法陷入局部極小是 RL 的固有缺陷。
另一位 DRL 研究者 Matthew Rahtz 則通過講述自己試圖復現一個 DRL 算法的坎坷歷程來回應 Alexirpan,讓大家深刻體會了復現 DRL 算法有多么難 [15]。半年前,Rahtz 出于研究興趣,選擇對 OpenAI 的論文 Deep Reinforcement Learning from Human Preferences 進行復現。在復現的過程中,幾乎踩了 Alexirpan 總結的所有的坑。他認為復現 DRL 算法與其是一個工程問題,更不如說像一個數學問題。“它更像是你在解決一個謎題,沒有規律可循,唯一的方法是不斷嘗試,直到靈感出現徹底搞明白。……很多看上去無關緊要的小細節成了唯一的線索……做好每次卡住好幾周的準備。”Rahtz 在復現的過程中積累了很多寶貴的工程經驗,但整個過程的難度還是讓他花費了大量的金錢以及時間。他充分調動不同的計算資源,包括學校的機房資源、Google 云計算引擎和 FloydHub,總共花費高達 850 美元。可就算這樣,原定于 3 個月完成的項目,最終用了 8 個月,其中大量時間用在調試上。
復現 DRL 算法的實際時間遠多于預計時間 [15]
Rahtz 最終實現了復現論文的目標。他的博文除了給讀者詳細總結了一路走來的各種寶貴工程經驗,更讓大家從一個具體事例感受到了 DRL 研究實際上存在多大的泡沫、有多少的坑。有人評論到,“DRL 的成功可能不是因為其真的有效,而是因為人們花了大力氣。”
很多著名學者也紛紛加入討論。目前普遍的觀點是,DRL 可能有 AI 領域最大的泡沫。機器學習專家 Jacob Andreas 發了一條意味深長的 tweet 說:
Jacob Andreas 對 DRL 的吐槽
DRL 的成功歸因于它是機器學習界中唯一一種允許在測試集上訓練的方法。
從 Pineau & Precup 打響第一槍到現在的 1 年多時間里,DRL 被錘得千瘡百孔,從萬眾矚目到被普遍看衰。就在筆者準備投稿這篇文章的時候,Pineau 又受邀在 ICLR 2018 上作了一個題為 Reproducibility, Reusability, and Robustness in DRL 的報告 [16],并且正式開始舉辦“可復現實驗挑戰賽”。看來學界對 DRL 的吐槽將會持續,負面評論還將持續發酵。那么, DRL 的問題根結在哪里?前景真的如此黯淡嗎?如果不與深度學習結合,RL 的出路又在哪里?
在大家紛紛吐槽 DRL 的時候,著名的優化專家 Ben Recht,從另一個角度給出一番分析。
二、免模型強化學習的本質缺陷
RL 算法可以分為基于模型的方法(Model-based)與免模型的方法(Model-free)。前者主要發展自最優控制領域。通常先通過高斯過程(GP)或貝葉斯網絡(BN)等工具針對具體問題建立模型,然后再通過機器學習的方法或最優控制的方法,如模型預測控制(MPC)、線性二次調節器(LQR)、線性二次高斯(LQG)、迭代學習控制(ICL)等進行求解。而后者更多地發展自機器學習領域,屬于數據驅動的方法。算法通過大量采樣,估計代理的狀態、動作的值函數或回報函數,從而優化動作策略。
基于模型 vs. 免模型 [17]
從年初至今,Ben Recht 連發了 13 篇博文,從控制與優化的視角,重點探討了 RL 中的免模型方法 [18]。Recht 指出免模型方法自身存在以下幾大缺陷:
免模型方法無法從不帶反饋信號的樣本中學習,而反饋本身就是稀疏的,因此免模型方向樣本利用率很低,而數據驅動的方法則需要大量采樣。比如在 Atari 平臺上的《Space Invader》和《Seaquest》游戲中,智能體所獲得的分數會隨訓練數據增加而增加。利用免模型 DRL 方法可能需要 2 億幀畫面才能學到比較好的效果。AlphaGo 最早在 Nature 公布的版本也需要 3000 萬個盤面進行訓練。而但凡與機械控制相關的問題,訓練數據遠不如視頻圖像這樣的數據容易獲取,因此只能在模擬器中進行訓練。而模擬器與現實世界間的 Reality Gap,直接限制了訓練自其中算法的泛化性能。另外,數據的稀缺性也影響了其與 DL 技術的結合。
免模型方法不對具體問題進行建模,而是嘗試用一個通用的算法解決所有問題。而基于模型的方法則通過針對特定問題建立模型,充分利用了問題固有的信息。免模型方法在追求通用性的同時放棄這些富有價值的信息。
基于模型的方法針對問題建立動力學模型,這個模型具有解釋性。而免模型方法因為沒有模型,解釋性不強,調試困難。
相比基于模型的方法,尤其是基于簡單線性模型的方法,免模型方法不夠穩定,在訓練中極易發散。
為了證實以上觀點,Recht 將一個簡單的基于 LQR 的隨機搜索方法與最好的免模型方法在 MuJoCo 實驗環境上進行了實驗對比。在采樣率相近的情況下,基于模型的隨機搜索算法的計算效率至少比免模型方法高 15 倍 [19]。

基于模型的隨機搜索方法 ARS 吊打一眾免模型方法 [19]
通過 Recht 的分析,我們似乎找到了 DRL 問題的根結。近三年在機器學習領域大火的 DRL 算法,多將免模型方法與 DL 結合,而免模型算法的天然缺陷,恰好與 Alexirpan 總結的 DRL 幾大問題相對應(見上文)。
看來,DRL 的病根多半在采用了免模型方法上。為什么多數 DRL 的工作都是基于免模型方法呢?筆者認為有幾個原因。第一,免模型的方法相對簡單直觀,開源實現豐富,比較容易上手,從而吸引了更多的學者進行研究,有更大可能做出突破性的工作,如 DQN 和 AlphaGo 系列。第二,當前 RL 的發展還處于初級階段,學界的研究重點還是集中在環境是確定的、靜態的,狀態主要是離散的、靜態的、完全可觀察的,反饋也是確定的問題(如 Atari 游戲)上。針對這種相對“簡單”、基礎、通用的問題,免模型方法本身很合適。最后,在“AI = RL + DL”這一觀點的鼓動下,學界高估了 DRL 的能力。DQN 展示出的令人興奮的能力使得很多人圍繞著 DQN 進行拓展,創造出了一系列同樣屬于免模型的工作。
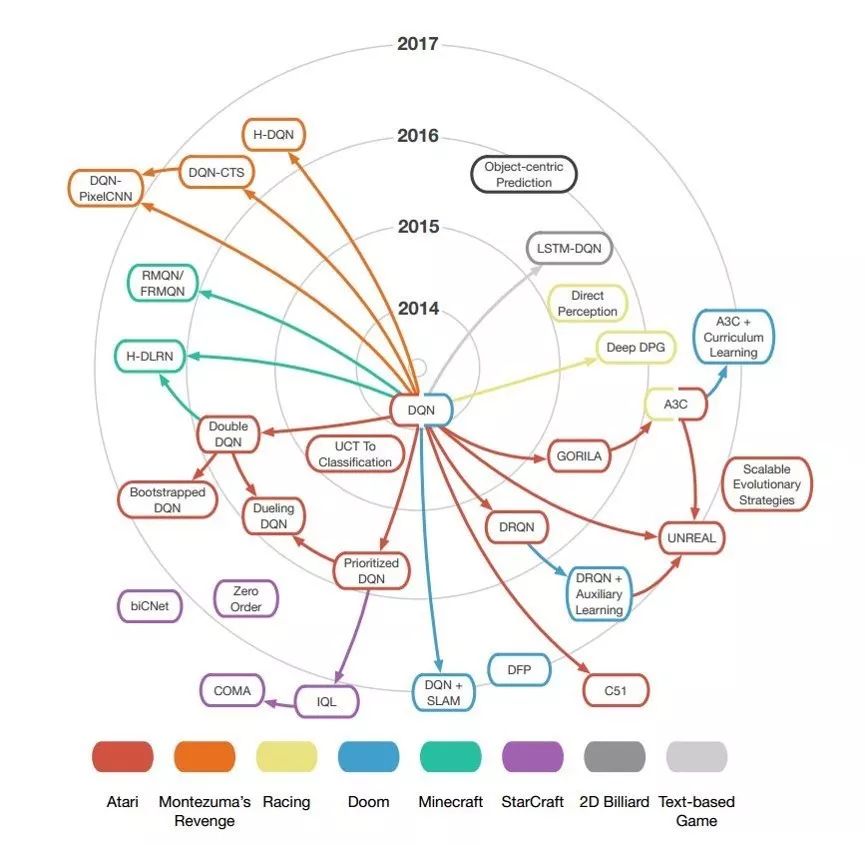
絕大多數 DRL 方法是對 DQN 的擴展,屬于免模型方法 [20]
那么,DRL 是不是應該拋棄免模型方法,擁抱基于模型的方法呢?
三、基于模型或免模型,問題沒那么簡單
3.1 基于模型的方法,未來潛力巨大
基于模型的方法一般先從數據中學習模型,然后基于學到的模型對策略進行優化。學習模型的過程和控制論中的系統參數辨識類似。因為模型的存在,基于模型的方法可以充分利用每一個樣本來逼近模型,數據利用率極大提高。基于模型的方法則在一些控制問題中,相比于免模型方法,通常有 10^2 級的采樣率提升。此外,學到的模型往往對環境的變化魯棒, 當遇到新環境時,算法可以依靠已學到的模型做推理,具有很好的泛化性能。
基于模型的方法具有更高采樣率 [22]
此外,基于模型的方法還與潛力巨大的預測學習(Predictive Learning)緊密相關。由于建立了模型,本身就可以通過模型預測未來,這與 Predictive Learning 的需求不謀而合。其實,Yann LeCun 在廣受關注的 NIPS 2016 主題報告上介紹 Predictive Learning 時,也是以基于模型的方法作為例子的 [21]。筆者認為,基于模型的 RL 方法可能是實現 Predictive Learning 的重要技術之一。
這樣看來,基于模型的方法似乎更有前途。但天下沒有免費的午餐,模型的存在也帶來了若干問題。
3.2 免模型方法,依舊是第一選擇
基于模型的 DRL 方法相對而言不那么簡單直觀,RL 與 DL 的結合方式相對更復雜,設計難度更高。目前基于模型的 DRL 方法通常用高斯過程、貝葉斯網絡或概率神經網絡(PNN)來構建模型,典型的如 David Silver 在 2016 年提出的 Predictron 模型 [23]。另外一些工作,如 Probabilistic Inference for Learning COntrol (PILCO)[24],本身不基于神經網絡,不過有與 BN 結合的擴展版本。而 Guided Policy Search (GPS) 雖然在最優控制器的優化中使用了神經網絡,但模型并不依賴神經網絡 [25]。此外還有一些模型將神經網絡與模型耦合在一起 [26]。這些工作不像免模型 DRL 方法那樣直觀且自然,DL 所起的作用也各有不同。
除此之外,基于模型的方法也還存在若干自身缺陷:
針對無法建模的問題束手無策。有些領域,比如 NLP,存在大量難以歸納成模型的任務。在這種場景下,只能通過諸如 R-max 算法這樣的方法先與環境交互,計算出一個模型為后續使用。但是這種方法的復雜度一般很高。近期有一些工作結合預測學習建立模型,部分地解決了建模難的問題,這一思路逐漸成為了研究熱點。
建模會帶來誤差,而且誤差往往隨著算法與環境的迭代交互越來越大,使得算法難以保證收斂到最優解。
模型缺乏通用性,每次換一個問題,就要重新建模。
針對以上幾點,免模型方法都有相對優勢:對現實中非常多的無法建模的問題以及模仿學習問題,免模型算法仍是最好的選擇。并且,免模型方法在理論上具備漸近收斂性,經過無數次與環境的交互可以保證得到最優解,這是基于模型的方法很難獲得的結果。最后,免模型最大的優勢就是具備非常好的通用性。事實上,在處理真正困難的問題時,免模型方法的效果通常更好。Recht 也在博文中指出,控制領域很有效的 MPC 算法其實與 Q-Learning 這樣的免模型方法非常相關 [18]。
基于模型的方法與免模型的方法的區別其實也可以看做基于知識的方法與基于統計的方法的區別。總體來講,兩種方法各有千秋,很難說其中一種方法優于另一種。在 RL 領域中,免模型算法只占很少一部分,但基于歷史原因,當前免模型的 DRL 方法發展迅速數量龐大,而基于模型的 DRL 方法則相對較少。筆者認為,我們可以考慮多做一些基于模型的 DRL 方面的工作,克服當前 DRL 存在的諸多問題。此外,還可以多研究結合基于模型方法與免模型方法的半模型方法,兼具兩種方法的優勢。這方面經典的工作有 RL 泰斗 Rich Sutton 提出的 Dyna 框架 [27] 和其弟子 David Silver 提出的 Dyna-2 框架 [28]。
通過以上討論,我們似乎對 DRL 目前的困境找到了出路。但其實,造成當前 DRL 困境的原因遠不止這些。
3.3 不僅僅是模型與否的問題
上文提到 Recht 使用基于隨機搜索的方法吊打了免模型方法,似乎宣判了免模型方法的死刑。但其實這個對比并不公平。
2017 年 3 月,機器學習專家 Sham Kakade 的研究組發表文章 Towards Generalization and Simplicity in Continuous Control,試圖探尋針對連續控制問題的簡單通用的解法 [29] 。他們發現當前的模擬器存在非常大的問題,經過調試的線性策略就已經可以取得非常好的效果——這樣的模擬器實在過于粗糙,難怪基于隨機搜索的方法可以在同樣的模擬器上戰勝免模型方法!
可見目前 RL 領域的實驗平臺還非常不成熟,在這樣的測試環境中的實驗實驗結果沒有足夠的說服力。很多研究結論都未必可信,因為好性能的取得或許僅僅是因為利用了模擬器的 bugs。此外,一些學者指出當前 RL 算法的性能評判準則也不科學。Ben Recht 和 Sham Kakade 都對 RL 的發展提出了多項具體建議,包括測試環境、基準算法、衡量標準等 [18,29]。可見 RL 領域還有太多需要改進和規范化。
那么,RL 接下來該如何突破呢?
四、重新審視強化學習
對 DRL 和免模型 RL 的質疑與討論,讓我們可以重新審視 RL,這對 RL 今后的發展大有裨益。
4.1 重新審視 DRL 的研究與應用
DQN 和 AlphaGo 系列工作給人留下深刻印象,但是這兩種任務本質上其實相對“簡單”。因為這些任務的環境是確定的、靜態的,狀態主要是離散的、靜態的、完全可觀察的,反饋是確定的,代理也是單一的。目前 DRL 在解決部分可見狀態任務(如 StarCraft),狀態連續的任務(如機械控制任務),動態反饋任務和多代理任務中還沒取得令人驚嘆的突破。
DRL 取得成功的任務本質上相對簡單 [30]
當前大量的 DRL 研究,尤其是應用于計算機視覺領域任務的研究中,很多都是將計算機視覺的某一個基于 DL 的任務強行構造成 RL 問題進行求解,其結果往往不如傳統方法好。這樣的研究方式造成 DRL 領域論文數量暴增、水分巨大。作為 DRL 的研究者,我們不應該找一個 DL 任務強行將其 RL 化,而是應該針對一些天然適合 RL 處理的任務,嘗試通過引入 DL 來提升現有方法在目標識別環節或函數逼近環節上的能力。
在計算機視覺任務中,通過結合 DL 獲得良好的特征表達或函數逼近是非常自然的思路。但在有些領域,DL 未必能發揮強大的特征提取作用,也未必被用于函數逼近。比如 DL 至今在機器人領域最多起到感知作用,而無法取代基于力學分析的方法。雖然有一些將 DRL 應用于物體抓取等現實世界的機械控制任務上并取得成功的案例,如 QT-Opt[70],但往往需要大量的調試和訓練時間。我們應該清晰地認識 DRL 算法的應用特點:因為其輸出的隨機性,當前的 DRL 算法更多地被用在模擬器而非真實環境中。而當前具有實用價值且只需運行于模擬器中的任務主要有三類,即視頻游戲、棋類游戲和自動機器學習(AutoML,比如谷歌的 AutoML Vision)。
這并不是說 DRL 的應用被困在模擬器中——如果能針對某一具體問題,解決模擬器與真實世界間的差異,則可以發揮 DRL 的強大威力。最近 Google 的研究員就針對四足機器人運動問題,通過大力改進模擬器,使得在模擬器中訓練的運動策略可以完美遷移到真實世界中,取得了令人驚艷的效果 [71]。不過,考慮到 RL 算法的不穩定性,在實際應用中不應盲目追求端到端的解決方案,而可以考慮將特征提取(DL)與決策(RL)分開,從而獲得更好的解釋性與穩定性。此外,模塊化 RL(將 RL 算法封裝成一個模塊)以及將 RL 與其他模型融合,將在實際應用中有廣闊前景。而如何通過 DL 學習一個合適于作為 RL 模塊輸入的表示,也值得研究。
4.2 重新審視 RL 的研究
機器學習是個跨學科的研究領域,而 RL 則是其中跨學科性質非常顯著的一個分支。RL 理論的發展受到生理學、神經科學和最優控制等領域的啟發,現在依舊在很多相關領域被研究。在控制理論、機器人學、運籌學、經濟學等領域內部,依舊有很多的學者投身 RL 的研究,類似的概念或算法往往在不同的領域被重新發明,起了不同的名字。
RL 的發展受到多個學科的影響 [31]
Princeton 大學著名的運籌學專家 Warren Powell 曾經寫了一篇題為 AI, OR and Control Theory: A Rosetta Stone for Stochastic Optimization 的文章,整理了 RL 中同一個概念、算法在 AI、OR(運籌學)和 Control Theory(控制理論)中各自對應的名稱,打通了不同領域間的隔閡 [32] 。由于各種學科各自的特點,不同領域的 RL 研究又獨具特色,這使得 RL 的研究可以充分借鑒不同領域的思想精華。
在這里,筆者根據自身對 RL 的理解,試著總結一些值得研究的方向:
基于模型的方法。如上文所述,基于模型的方法不僅能大幅降低采樣需求,還可以通過學習任務的動力學模型,為預測學習打下基礎。
提高免模型方法的數據利用率和擴展性。這是免模型學習的兩處硬傷,也是 Rich Sutton 的終極研究目標。這個領域很艱難,但是任何有意義的突破也將帶來極大價值。
更高效的探索策略(Exploration Strategies)。平衡“探索”與“利用”是 RL 的本質問題,這需要我們設計更加高效的探索策略。除了若干經典的算法如 Softmax、?-Greedy[1]、UCB[72] 和 Thompson Sampling[73] 等,近期學界陸續提出了大批新算法,如 Intrinsic Motivation [74]、Curiosity-driven Exploration[75]、Count-based Exploration [76] 等。其實這些“新”算法的思想不少早在 80 年代就已出現 [77],而與 DL 的有機結合使它們重新得到重視。此外,OpenAI 與 DeepMind 先后提出通過在策略參數 [78] 和神經網絡權重 [79] 上引入噪聲來提升探索策略, 開辟了一個新方向。
與模仿學習(Imitation Learning, IL)結合。機器學習與自動駕駛領域最早的成功案例 ALVINN[33] 就是基于 IL;當前 RL 領域最頂級的學者 Pieter Abbeel 在跟隨 Andrew Ng 讀博士時候, 設計的通過 IL 控制直升機的算法 [34] 成為 IL 領域的代表性工作。2016 年,英偉達提出的端到端自動駕駛系統也是通過 IL 進行學習 [68]。而 AlphaGo 的學習方式也是 IL。IL 介于 RL 與監督學習之間,兼具兩者的優勢,既能更快地得到反饋、更快地收斂,又有推理能力,很有研究價值。關于 IL 的介紹,可以參見 [35] 這篇綜述。
獎賞塑形(Reward Shaping)。獎賞即反饋,其對 RL 算法性能的影響是巨大的。Alexirpan 的博文中已經展示了沒有精心設計的反饋信號會讓 RL 算法產生多么差的結果。設計好的反饋信號一直是 RL 領域的研究熱點。近年來涌現出很多基于“好奇心”的 RL 算法和層級 RL 算法,這兩類算法的思路都是在模型訓練的過程中插入反饋信號,從而部分地克服了反饋過于稀疏的問題。另一種思路是學習反饋函數,這是逆強化學習(Inverse RL, IRL)的主要方式之一。近些年大火的 GAN 也是基于這個思路來解決生成建模問題, GAN 的提出者 Ian Goodfellow 也認為 GAN 就是 RL 的一種方式 [36]。而將 GAN 于傳統 IRL 結合的 GAIL[37] 已經吸引了很多學者的注意。
RL 中的遷移學習與多任務學習。當前 RL 的采樣效率極低,而且學到的知識不通用。遷移學習與多任務學習可以有效解決這些問題。通過將從原任務中學習的策略遷移至新任務中,避免了針對新任務從頭開始學習,這樣可以大大降低數據需求,同時也提升了算法的自適應能力。在真實環境中使用 RL 的一大困難在于 RL 的不穩定性,一個自然的思路是通過遷移學習將在模擬器中訓練好的穩定策略遷移到真實環境中,策略在新環境中僅通過少量探索即可滿足要求。然而,這一研究領域面臨的一大問題就是現實鴻溝(Reality Gap),即模擬器的仿真環境與真實環境差異過大。好的模擬器不僅可以有效填補現實鴻溝,還同時滿足 RL 算法大量采樣的需求,因此可以極大促進 RL 的研究與開發,如上文提到的 Sim-to-Real[71]。同時,這也是 RL 與 VR 技術的一個結合點。近期學術界和工業界紛紛在這一領域發力。在自動駕駛領域,Gazebo、EuroTruck Simulator、TORCS、Unity、Apollo、Prescan、Panosim 和 Carsim 等模擬器各具特色,而英特爾研究院開發的 CARLA 模擬器 [38] 逐漸成為業界研究的標準。其他領域的模擬器開發也呈現百花齊放之勢:在家庭環境模擬領域, MIT 和多倫多大學合力開發了功能豐富的 VirturalHome 模擬器;在無人機模擬訓練領域,MIT 也開發了 Flight Goggles 模擬器。
提升 RL 的的泛化能力。機器學習最重要的目標就是泛化能力, 而現有的 RL 方法大多在這一指標上表現糟糕 [8],無怪乎 Jacob Andreas 會批評 RL 的成功是來自“train on the test set”。這一問題已經引起了學界的廣泛重視,研究者們試圖通過學習環境的動力學模型 [80]、降低模型復雜度 [29] 或模型無關學習 [81] 來提升泛化能力,這也促進了基于模型的方法與元學習(Meta-Learning)方法的發展。BAIR 提出的著名的 Dex-Net 項目主要目標就是構建具有良好魯棒性、泛化能力的機器人抓取模型 [82],而 OpenAI 也于 2018 年 4 月組織了 OpenAI Retro Contest ,鼓勵參與者開發具有良好泛化能力的 RL 算法 [83]。
層級 RL(Hierarchical RL, HRL)。周志華教授總結 DL 成功的三個條件為:有逐層處理、有特征的內部變化和有足夠的模型復雜度 [39]。而 HRL 不僅滿足這三個條件,而且具備更強的推理能力,是一個非常潛力的研究領域。目前 HRL 已經在一些需要復雜推理的任務(如 Atari 平臺上的《Montezuma's Revenge》游戲)中展示了強大的學習能力 [40]。
與序列預測(Sequence Prediction)結合。Sequence Prediction 與 RL、IL 解決的問題相似又不相同。三者間有很多思想可以互相借鑒。當前已有一些基于 RL 和 IL 的方法在 Sequence Prediction 任務上取得了很好的結果 [41,42,43]。這一方向的突破對 Video Prediction 和 NLP 中的很多任務都會產生廣泛影響。
(免模型)方法探索行為的安全性(Safe RL)。相比于基于模型的方法,免模型方法缺乏預測能力,這使得其探索行為帶有更多不穩定性。一種研究思路是結合貝葉斯方法為 RL 代理行為的不確定性建模,從而避免過于危險的探索行為。此外,為了安全地將 RL 應用于現實環境中,可以在模擬器中借助混合現實技術劃定危險區域,通過限制代理的活動空間約束代理的行為。
關系 RL。近期學習客體間關系從而進行推理與預測的“關系學習”受到了學界的廣泛關注。關系學習往往在訓練中構建的狀態鏈,而中間狀態與最終的反饋是脫節的。RL 可以將最終的反饋回傳給中間狀態,實現有效學習,因而成為實現關系學習的最佳方式。2017 年 DeepMind 提出的 VIN[44] 和 Pridictron[23] 均是這方面的代表作。2018 年 6 月,DeepMind 又接連發表了多篇關系學習方向的工作如關系歸納偏置 [45]、關系 RL[46]、關系 RNN[47]、圖網絡 [48] 和已經在《科學》雜志發表的生成查詢網絡(Generative Query Network,GQN)[49]。這一系列引人注目的工作將引領關系 RL 的熱潮。
對抗樣本 RL。RL 被廣泛應用于機械控制等領域,這些領域相比于圖像識別語音識別等等,對魯棒性和安全性的要求更高。因此針對 RL 的對抗攻擊是一個非常重要的問題。近期有研究表明,會被對抗樣本操控,很多經典模型如 DQN 等算法都經不住對抗攻擊的擾動 [50,51]。
處理其他模態的輸入。在 NLP 領域,學界已經將 RL 應用于處理很多模態的數據上,如句子、篇章、知識庫等等。但是在計算機視覺領域,RL 算法主要還是通過神經網絡提取圖像和視頻的特征,對其他模態的數據很少涉及。我們可以探索將 RL 應用于其他模態的數據的方法,比如處理 RGB-D 數據和激光雷達數據等。一旦某一種數據的特征提取難度大大降低,將其與 RL 有機結合后都可能取得 AlphaGo 級別的突破。英特爾研究院已經基于 CARLA 模擬器在這方面開展了一系列的工作。
4.3 重新審視 RL 的應用
當前的一種觀點是“RL 只能打游戲、下棋,其他的都做了”。而筆者認為,我們不應對 RL 過于悲觀。其實能在視頻游戲與棋類游戲中超越人類,已經證明了 RL 推理能力的強大。通過合理改進后,有希望得到廣泛應用。往往,從研究到應用的轉化并不直觀。比如,IBM Watson? 系統以其對自然語言的理解能力和應答能力聞名世界,曾在 2011 年擊敗人類選手獲得 Jeopardy! 冠軍。而其背后的支撐技術之一竟然是當年 Gerald Tesauro 開發 TD-Gammon 程序 [52] 時使用的 RL 技術 [53]。當年那個“只能用于”下棋的技術,已經在最好的問答系統中發揮不可或缺的作用了。今天的 RL 發展水平遠高于當年,我們怎么能沒有信心呢?
強大的 IBM Watson?背后也有 RL 發揮核心作用
通過調查,我們可以發現 RL 算法已經在各個領域被廣泛使用:
控制領域。這是 RL 思想的發源地之一,也是 RL 技術應用最成熟的領域。控制領域和機器學習領域各自發展了相似的思想、概念與技術,可以互相借鑒。比如當前被廣泛應用的 MPC 算法就是一種特殊的 RL。在機器人領域,相比于 DL 只能用于感知,RL 相比傳統的法有自己的優勢:傳統方法如 LQR 等一般基于圖搜索或概率搜索學習到一個軌跡層次的策略,復雜度較高,不適合用于做重規劃;而 RL 方法學習到的則是狀態 - 動作空間中的策略,具有更好的適應性。
自動駕駛領域。駕駛就是一個序列決策過程,因此天然適合用 RL 來處理。從 80 年代的 ALVINN、TORCS 到如今的 CARLA,業界一直在嘗試用 RL 解決單車輛的自動駕駛問題以及多車輛的交通調度問題。類似的思想也廣泛地應用在各種飛行器、水下無人機領域。
NLP 領域。相比于計算機視覺領域的任務,NLP 領域的很多任務是多輪的,即需通過多次迭代交互來尋求最優解(如對話系統);而且任務的反饋信號往往需要在一系列決策后才能獲得(如機器寫作)。這樣的問題的特性自然適合用 RL 來解決,因而近年來 RL 被應用于 NLP 領域中的諸多任務中,如文本生成、文本摘要、序列標注、對話機器人(文字 / 語音)、機器翻譯、關系抽取和知識圖譜推理等等。成功的應用案例也有很多,如對話機器人領域中 Yoshua Bengio 研究組開發的 MILABOT 的模型 [54]、Facebook 聊天機器人 [55] 等;機器翻譯領域 Microsoft Translator [56] 等。此外,在一系列跨越 NLP 與計算機視覺兩種模態的任務如 VQA、Image/Video Caption、Image Grounding、Video Summarization 等中,RL 技術也都大顯身手。
推薦系統與檢索系統領域。RL 中的 Bandits 系列算法早已被廣泛應用于商品推薦、新聞推薦和在線廣告等領域。近年也有一系列的工作將 RL 應用于信息檢索、排序的任務中 [57]。
金融領域。RL 強大的序列決策能力已經被金融系統所關注。無論是華爾街巨頭摩根大通還是創業公司如 Kensho,都在其交易系統中引入了 RL 技術。
對數據的選擇。在數據足夠多的情況下,如何選擇數據來實現“快、好、省”地學習,具有非常大的應用價值。近期在這方面也涌現出一系列的工作,如 UCSB 的 Jiawei Wu 提出的 Reinforced Co-Training [58] 等。
通訊、生產調度、規劃和資源訪問控制等運籌領域。這些領域的任務往往涉及“選擇”動作的過程,而且帶標簽數據難以取得,因此廣泛使用 RL 進行求解。
關于 RL 的更全面的應用綜述請參見文獻 [59,60]。
雖然有上文列舉的諸多成功應用,但我們依舊要認識到,當前 RL 的發展還處于初級階段,不能包打天下。目前還沒有一個通用的 RL 解決方案像 DL 一樣成熟到成為一種即插即用的算法。不同 RL 算法在各自領域各領風騷。在找到一個普適的方法之前,我們更應該針對特定問題設計專門的算法,比如在機器人領域,基于貝葉斯 RL 和演化算法的方法(如 CMAES[61])比 DRL 更合適。當然,不同的領域間應當互相借鑒與促進。RL 算法的輸出存在隨機性,這是其“探索”哲學帶來的本質問題,因此我們不能盲目 All in RL, 也不應該 RL in All, 而是要找準 RL 適合解決的問題。
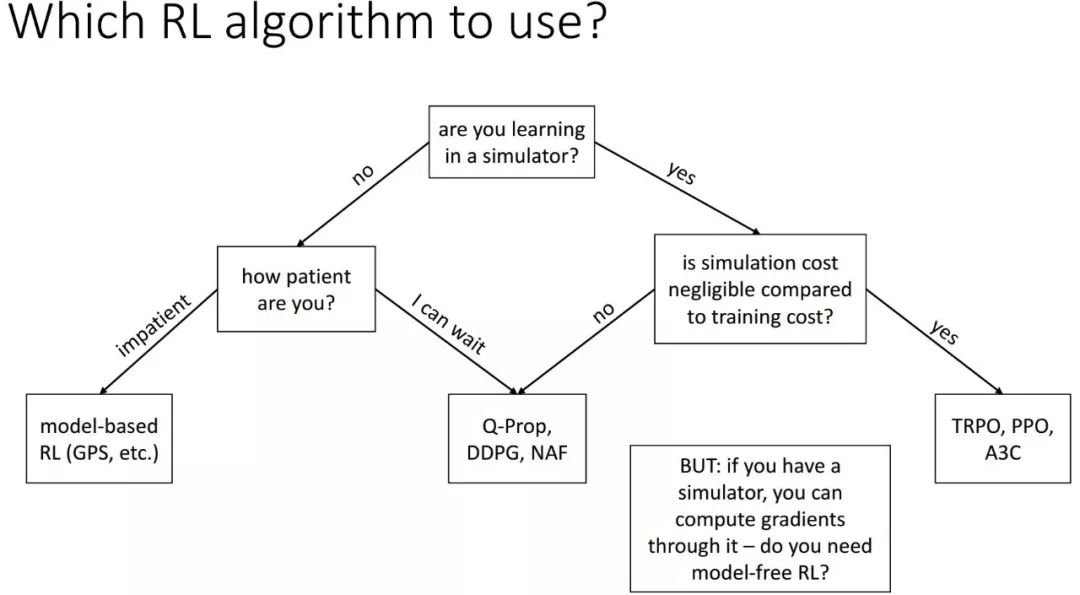
針對不同問題應該使用的不同 RL 方法 [22]
4.4 重新審視 RL 的價值
在 NIPS 2016 上,Yan LeCun 認為最有價值的問題是“Predictive Learning”問題,這其實類似于非監督學習問題。他的發言代表了學界近來的主流看法。而 Ben Recht 則認為,RL 比監督學習(Supervised Learning, SL)和非監督學習(Unsupervised Learning, UL)更有價值。他把這三類學習方式分別與商業分析中的描述分析(UL)、預測分析(SL)和指導分析(RL)相對應 [18]。
描述分析是對已有的數據進行總結,從而獲得更魯棒和清晰的表示,這個問題最容易,但價值也最低。因為描述分析的價值更多地在于美學方面而非實際方面。比如,“用 GAN 將一個房間的圖片渲染成何種風格”遠沒有“依據房間的圖片預測該房間的價格”更重要。而后者則是預測分析問題——基于歷史數據對當前數據進行預測。但是在描述分析和預測分析中,系統都是不受算法影響的,而指導分析則更進一步地對算法與系統間的交互進行建模,通過主動影響系統,最大化價值收益。
類比以上兩個例子,指導分析則是解決“如何通過對房間進行一系列改造來最大化提升房間價格”之類的問題。這種問題最難,因為涉及到了算法與系統的復雜交互,但也最有價值,因為指導性分析(RL)的天然目標就是價值最大化,也是人類解決問題的方式。并且,無論是描述分析還是預測分析,所處理的問題的環境都是靜態的、不變的,這個假設對大多數實際的問題都不成立。而指導分析則被用來處理環境動態變化的問題,甚至還要考慮到與其他對手的合作或競爭,與人類面臨的大多數實際問題更相似。
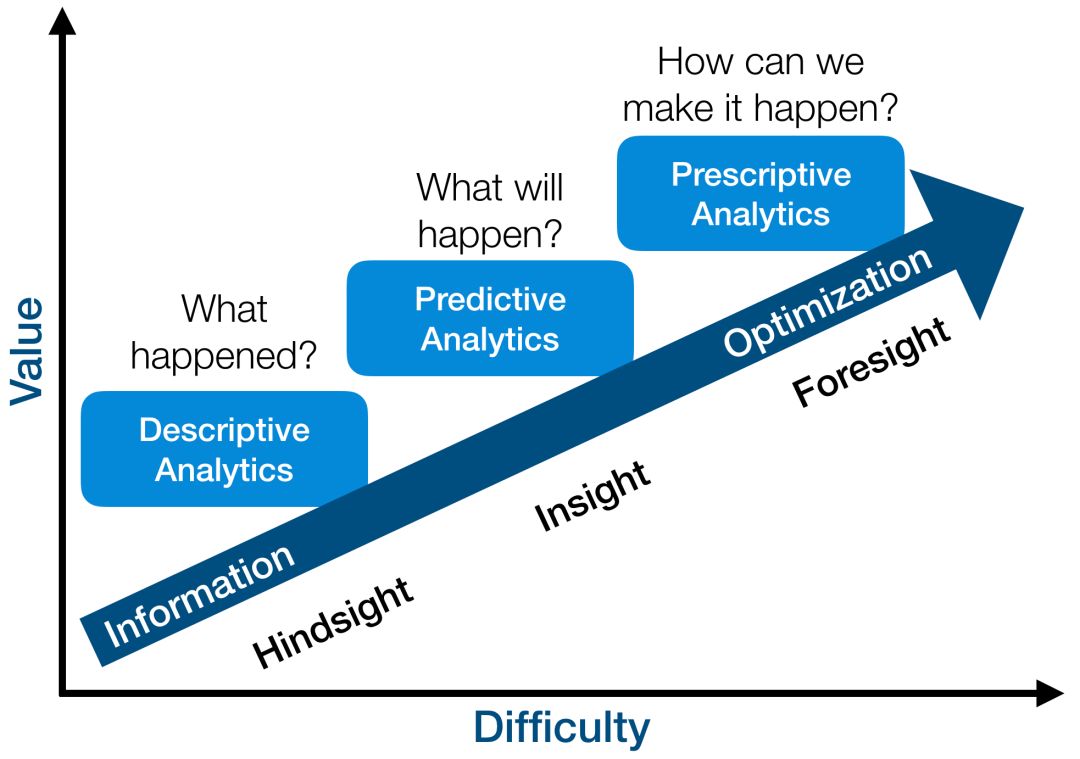
指導分析問題最難,也最有價值 [18]
在最后一節,筆者將試圖在更廣的范圍內討論類似于 RL 的從反饋中學習的方法,從而試圖給讀者介紹一種看待 RL 的新視角。
五、廣義的 RL——從反饋學習
本節使用“廣義的 RL”一詞指代針對“從反饋學習”的橫跨多個學科的研究。與上文中介紹的來自機器學習、控制論、經濟學等領域的 RL 不同,本節涉及的學科更寬泛,一切涉及從反饋學習的系統,都暫且稱為廣義的 RL。
5.1 廣義的 RL,是人工智能研究的最終目標
1950 年,圖靈在其劃時代論文 Computing Machinery and Intelligence[62] 中提出了著名的“圖靈測試”概念:如果一個人(代號 C)使用測試對象皆理解的語言去詢問兩個他不能看見的對象任意一串問題。對象為:一個是正常思維的人(代號 B)、一個是機器(代號 A)。如果經過若干詢問以后,C 不能得出實質的區別來分辨 A 與 B 的不同,則此機器 A 通過圖靈測試。
請注意,“圖靈測試”的概念已經蘊含了“反饋”的概念——人類借由程序的反饋來進行判斷,而人工智能程序則通過學習反饋來欺騙人類。同樣在這篇論文中,圖靈還說到“除了試圖直接去建立一個可以模擬成人大腦的程序之外,為什么不試圖建立一個可以模擬小孩大腦的程序呢?如果它接受適當的教育,就會獲得成人的大腦。”——從反饋中逐漸提升能力,這不正是 RL 的學習方式么?可以看出,人工智能的概念從被提出時其最終目標就是構建一個足夠好的從反饋學習的系統。
1959 年,人工智能先驅 Arthur Samuel 正式定義了“機器學習”這概念。也正是這位 Samuel,在 50 年代開發了基于 RL 的的象棋程序,成為人工智能領域最早的成功案例 [63]。為何人工智能先驅們的工作往往集中在 RL 相關的任務呢?經典巨著《人工智能:一種現代方法》里對 RL 的評論或許可以回答這一問題:可以認為 RL 囊括了人工智能的所有要素:一個智能體被置于一個環境中,并且必須學會在其間游刃有余(Reinforcement Learning might be considered to encompass all of AI: an agent is placed in an environment and must learn to behave successfully therein.) [64]。
不僅僅在人工智能領域,哲學領域也強調了行為與反饋對智能形成的意義。生成論(Enactivism)認為行為是認知的基礎,行為與感知是互相促進的,智能體通過感知獲得行為的反饋,而行為則帶給智能體對環境的真實有意義的經驗 [65]。
行為和反饋是智能形成的基石 [65]
看來,從反饋學習確實是實現智能的核心要素。
回到人工智能領域。DL 取得成功后,與 RL 結合成為 DRL。知識庫相關的研究取得成功后,RL 算法中也逐漸加入了 Memory 機制。而變分推理也已經找到了與 RL 的結合點。近期學界開始了反思 DL 的熱潮,重新燃起對因果推理與符號學習的興趣,于是也出現了關系 RL 和符號 RL[66] 相關的工作。通過回顧學術的發展,我們也可以總結出人工智能發展的一個特點:每當一個相關方向取得突破,總是會回歸到 RL 問題, 尋求與 RL 相結合。與其把 DRL 看作 DL 的拓展,不如看作 RL 的一次回歸。因此我們不必特別擔心 DRL 的泡沫,因為 RL 本就是人工智能的最終目標,有著旺盛的生命力,未來還會迎來一波又一波的發展。
5.2 廣義的 RL,是未來一切機器學習系統的形式
Recht 在他的最后一篇博文中 [67] 中強調,只要一個機器學習系統會通過接收外部的反饋進行改進,這個系統就不僅僅是一個機器學習系統,而且是一個 RL 系統。當前在互聯網領域廣為使用的 A/B 測試就是 RL 的一種最簡單的形式。而未來的機器學習系統,都要處理分布動態變化的數據并從反饋中學習。因此可以說,我們即將處于一個“一切機器學習都是 RL”的時代,學界和工業界都亟需加大對 RL 的研究力度。Recht 從社會與道德層面對這一問題進行了詳細探討 [67],并將他從控制與優化角度對 RL 的一系列思考總結成一篇綜述文章供讀者思考 [69]。
5.3 廣義的 RL,是很多領域研究的共同目標
4.2 節已經提到 RL 在機器學習相關的領域被分別發明與研究,其實這種從反饋中學習的思想,在很多其他領域也被不斷地研究。僅舉幾例如下:
在心理學領域,經典條件反射與操作性條件反射的對比,就如同 SL 和 RL 的對比;而著名心理學家 Albert Bandura 提出的“觀察學習”理論則與 IL 非常相似;精神分析大師 Melanie Klein 提出的“投射性認同”其實也可以看做一個 RL 的過程。在心理學諸多領域中,與 RL 關聯最近的則是行為主義學派(Behaviorism)。其代表人物 John Broadus Watson 將行為主義心理學應用于廣告業,極大推動了廣告業的發展。這很難不讓人聯想到,RL 算法的一大成熟應用就是互聯網廣告。而行為主義受到認知科學影響而發展出的認知行為療法則與 RL 中的策略遷移方法有異曲同工之妙。行為主義與 RL 的淵源頗深,甚至可以說是 RL 思想的另一個源頭。本文限于篇幅無法詳述,請感興趣的讀者參閱心理學方面的文獻如 [53]。
在教育學領域,一直有關于“主動學習”與“被動學習”兩種方式的對比與研究,代表性研究有 Cone of Experience,其結論與機器學習領域關于 RL 與 SL 的對比非常相似。而教育學家杜威提倡的“探究式學習”就是指主動探索尋求反饋的學習方法;
在組織行為學領域,學者們探究“主動性人格”與“被動性人格”的不同以及對組織的影響;
在企業管理學領域,企業的“探索式行為”和“利用式行為”一直是一個研究熱點;
……
可以說,一切涉及通過選擇然后得到反饋,然后從反饋中學習的領域,幾乎都有 RL 的思想以各種形式存在,因此筆者稱之為廣義的 RL。這些學科為 RL 的發展提供了豐富的研究素材,積累了大量的思想與方法。同時,RL 的發展不會僅僅對人工智能領域產生影響,也會推動廣義的 RL 所包含的諸多學科共同前進。
結 語
雖然 RL 領域目前還存在諸多待解決的問題,在 DRL 這一方向上也出現不少泡沫,但我們應該看到 RL 領域本身在研究和應用領域取得的長足進步。這一領域值得持續投入研究,但在應用時需保持理性。而對基于反饋的學習的研究,不僅有望實現人工智能的最終目標,也對機器學習領域和諸多其他領域的發展頗有意義。這確實是通向人工智能的最佳路徑。這條路上布滿荊棘,但曙光已現。
-
人工智能
+關注
關注
1791文章
47183瀏覽量
238247 -
強化學習
+關注
關注
4文章
266瀏覽量
11246
原文標題:泡沫破裂之后,強化學習路在何方?
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
嵌入式和人工智能究竟是什么關系?
如何使用 PyTorch 進行強化學習
人工智能、機器學習和深度學習存在什么區別

《AI for Science:人工智能驅動科學創新》第6章人AI與能源科學讀后感
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
risc-v在人工智能圖像處理應用前景分析
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創新
人工智能如何強化智能家居設備的功能
報名開啟!深圳(國際)通用人工智能大會將啟幕,國內外大咖齊聚話AI
FPGA在人工智能中的應用有哪些?
通過強化學習策略進行特征選擇






 工商網監
工商網監
評論