


DeepMind為視覺問題回答提出了一種新的硬注意力機制,它只保留了回答問題所需的少量視覺特征。減少需要處理的特征使得能夠訓練更大的關系模型,并在CLEVR上實現98.8%的準確率。
視覺注意力在許多方面都有助于人類的復雜視覺推理。例如,如果想要在一群人中認出一只狗的主人,人的視覺系統會自適應地分配更多的計算資源來處理與狗和可能的主人相關聯的視覺信息,而非場景中的其他信息。感知效果是非常明顯的,然而,注意力機制并不是計算機視覺領域的變革性力量,這可能是因為許多標準的計算機視覺任務,比如檢測、分割和分類,都沒有涉及有助于強化注意力機制的復雜推理。
要回答關于特定圖像的細節問題,這種任務就需要更復雜的推理模式。最近,用于解決視覺問答(Visual QA)任務的計算機視覺方法出現了迅速發展。成功的Visual QA架構必須能夠處理多個目標及其之間的復雜關系,同時還要整合豐富的背景知識,注意力已成為一種實現優秀性能的、有前途的計算機視覺方面的策略。
我們發現,計算機視覺和機器學習中的注意力機制存在很大的區別,即軟注意力(soft attention)和硬注意力(hard attention)。現有的注意力模型主要是基于soft attention的,所有信息在被聚合之前會以自適應的方式進行重新加權。這樣可以分離出重要信息,并避免這些信息受到不重要信息的干擾,從而提高準確性。隨著不同信息之間相互作用的復雜度的降低,學習就變得越有效。
圖1:我們使用給定的自然圖像和文本問題作為輸入,通過Visual QA架構輸出答案。該架構使用硬注意力(hard attention)機制,僅為任務選擇重要的視覺特征,進行進一步處理。我們的架構基于視覺特征的規范與其相關性相關的前提,那些具有高幅的特征向量對應的是包含重要語義內容的圖像區域。
相比之下,hard attention僅僅選擇一部分信息,對其進行進一步處理,這一方法現在已經得到越來越廣泛地使用。和soft attention機制一樣,hard attention也有可能通過將計算重點放在圖像中的重要部分來提高準確性和學習效率。但除此之外,hard attention的計算效率更高,因為它只對認為相關度最高的那部分信息做完全處理。
然而,在基于梯度的學習框架(如深度學習)中存在一個關鍵的缺點:因為選擇要處理的信息的過程是離散化的,因此也就是不可微分的,所以梯度不能反向傳播到選擇機制中來支持基于梯度的優化。目前研究人員正在努力來解決視覺注意力、文本注意力,乃至更廣泛的機器學習領域內的這一缺點,這一領域的研究仍然非常活躍。
本文中,我們探討了一種簡單的hard attention方法,它在卷積神經網絡(CNN)的特征表示中引發有趣的現象:對于hard attention選擇而言,已被學習過的特征通常是易于訪問的。特別是,選擇那些具有最大L2范數值的特征向量有助于hard attention方法的實現,并體現出性能和效率上的優勢(見圖1)。這種注意力信號間接來自標準的監督任務損失,并且不需要明確的監督與對象存在、顯著性或其他可能有意義的相關指標。
硬注意力網絡和自適應硬注意力網絡
我們使用規范化的Visual QA pipeline,利用特征向量的L2-norms來選擇信息的子集,以進行進一步處理。第一個版本稱為硬注意力網絡(Hard Attention Network, HAN),它可以選擇固定數量的規范度最高的特征向量,對其對應的信息作進一步處理。
第二個版本稱為自適應硬注意力網絡(Adaptive Hard Attention Network ,AdaHAN),它會根據輸入選擇可變數量的特征向量。我們的實驗結果表明,在具有挑戰性的Visual QA任務中,我們的算法實際上可以勝過類似的soft attention架構。該方法還能生成可解釋的hard attention masks,其中與被選中特征相關的圖像區域通常包含在語義上有意義的信息。我們的模型在與非局部成對模型相結合時也表現出強大的性能。我們的算法通過成對的輸入特征進行計算,因此在特征圖中的規模與向量數量的平方成正比,這也突出了特征選擇的重要性。
方法
回答有關圖像的問題通常是根據預測模型制定的。這些結構將相對回答a的條件分布最大化,給定問題q和圖像x:

其中A是所有可能答案的可數集合。就像常見的問題-回答一樣,問題是一個單詞序列q = [q1,...,qn],而輸出被簡化為一組常見答案之間的分類問題。我們用于從圖像和問題中學習映射的架構如圖2所示。
圖2:hard attention取代了常用的soft attention機制。
我們用CNN(在這個例子中是預訓練過的ResNet-101,或者從頭開始訓練的一個小型CNN)對圖像進行編碼,然后用LSTM將問題編碼成固定長度的向量表示。通過將問題表示復制到CNN的每個空間位置來計算組合表示,并將其與視覺特性連接在一起。
在經過幾層組合處理之后,我們將注意力放在了空間位置上,就跟應用soft attention機制的先前工作一樣。最后,我們使用sum-pooling或relational 模塊聚合特性。我們用一個對應答案類別的標準邏輯回歸損失來端到端地訓練整個網絡。
結果
為了說明對于Visual QA,hard attention的重要性,我們首先在VQA-CP v2上將HAN與現有的soft attention(SAN)架構進行比較,并通過直接控制卷積圖中注意空間單元的數量來探究不同程度的hard attention的影響。
然后,我們對AdaHAN進行了實驗,AdaHAN自適應地選擇了attended cell的數量。我們也簡要地研究了網絡深度和預訓練的影響。最后,我們給出了定性的結果,并提供了在CLEVR數據集上的結果,以說明該方法的通用性。
Hard Attention的效果
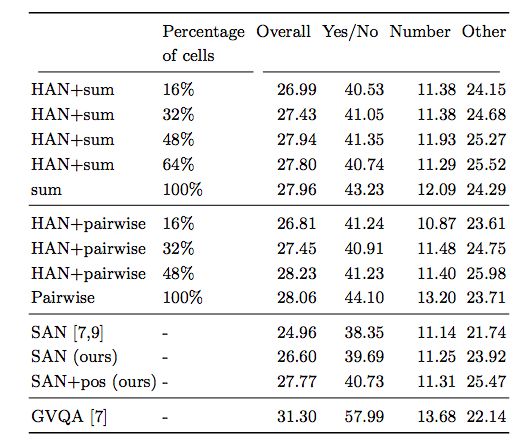
表1:不同數量的attended cell(整個輸入的百分比)和聚合操作的比較
結果顯示, 有 hard attention下,相比沒有 hard attention,模型的性能得到了提報。
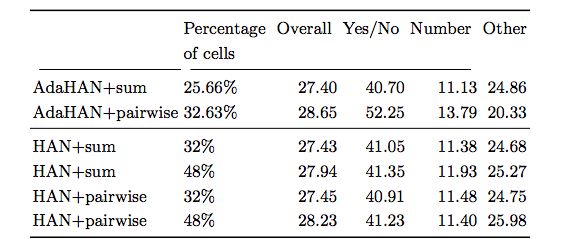
表2:不同的自適應hard-attention技術與平均參與數、以及聚合操作的比較
結果顯示,soft attention并不優于基本的sum polling方法。我們的結果盡管比state-of-the-art略差,但這可能是由于實驗中未包含的一些架構決策,例如不同類型問題的分離路徑,特殊問題嵌入和使用問題提取器( question extractor)。
Adaptive hard attention
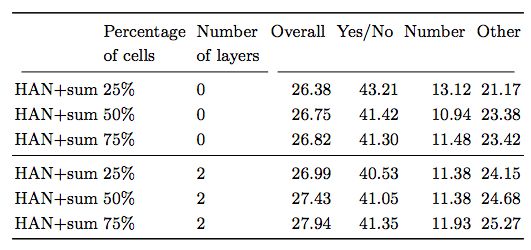
表3:不同數量的attended cells 占整個輸入的百分比
結果顯示,即使是以非常簡單的方法來適應圖像和問題,也可以導致計算和性能的提高,這表明更復雜的方法將是未來工作的重要方向。
CLEVR數據集上的表現
圖3: hard attention機制的不同變體與不同聚合方法之間的定性比較。綠色表示正確答案,紅色表示不正確,橙色表示和人類的答案之間的存在部分共識。這張圖說明了不同方法的優點。
圖4:我AdaHAN +成pairwise的其他結果。圖中,被注意的區域突出顯示,不被注意的區域則用暗色表示。綠色表示正確,紅色不正確的答案。 橙色表示存在部分共識。
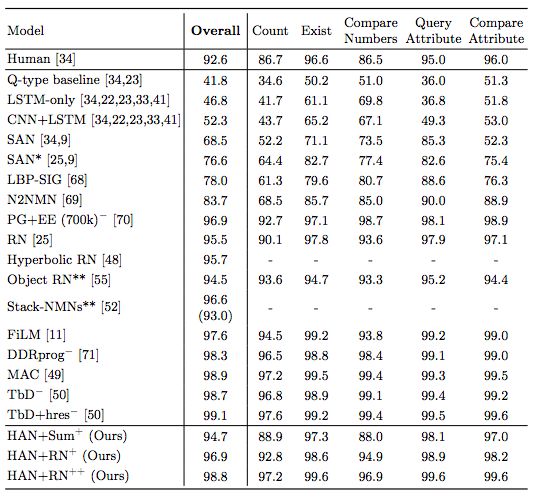
表4:在CLEVR上的準確率
由于hard-attention,我們能夠訓練更大的模型,我們稱之為HAN + sum?,HAN + RN?,以及HAN + RN??。這些模型使用更大的CNN和LSTM,而且HAN + RN??還使用更高的輸入分辨率。模型在CLEVR上的準確率分別達到94.7%、96.9%和98.8%。
總結
我們在計算機視覺領域引入了一種新的方法,可以選擇特征向量的子集,以便根據它們的大小進行進一步處理。我們研究了兩個模型,其中一個模型(HAN)會選擇數目預先確定的向量的子集,另一個模型(AdaHAN)則自適應地選擇子集規模作為輸入的函數。現有文獻中經常避免提到hard attention,因為它不可微分,對基于梯度的方法提出了挑戰。但是,我們發現特征向量的大小與相關信息有關,hard attention機制可以利用這個屬性來進行選擇。
結果顯示,HAN和AdaHAN方法在具有挑戰性的Visual QA數據集上的表現具備很強的競爭力。我們的方法至少和更常見的soft attention方法的表現一樣好,同時還提升了計算的效率。hard attention方法對于越來越常見的non-local方法而言尤其重要,這類方法通常需要的計算量和存儲器數量與輸入向量的平方成正比。最后,我們的方法還提供了可解釋的表示,因為這種方法所選擇的特征的空間位置與圖像中最重要的部分構成最強的相關性。
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103761 -
計算機視覺
+關注
關注
9文章
1709瀏覽量
46797 -
機器學習
+關注
關注
66文章
8505瀏覽量
134696
原文標題:DeepMind提出視覺問題回答新模型,CLEVR準確率達98.8%
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

一種通過引入硬注意力機制來引導學習視覺回答任務的研究
注意力機制的誕生、方法及幾種常見模型
基于注意力機制的深度學習模型AT-DPCNN

基于通道注意力機制的SSD目標檢測算法
一種注意力增強的自然語言推理模型aESIM

結合注意力機制的跨域服裝檢索方法
一種新的深度注意力算法

基于YOLOv5s基礎上實現五種視覺注意力模塊的改進





 工商網監
工商網監

評論