") 計算機是如何理解人類語言的?
計算機是如何理解人類語言的?
面向用戶:對NLP感興趣,想學習處理問題思路并通過實例代碼練手
Adam Geitgey畢業(yè)于佐治亞理工學院,曾在團購網(wǎng)站Groupon擔任軟件工程師總監(jiān)。目前是軟件工程和機器學習顧問,課程作者,Linkedin Learning的合作講師。
計算機是如何理解人類語言的?

讓機器理解人類語言,是一件非常困難的事情。計算機的專長在處理結構化數(shù)據(jù),但人類語言是非常復雜的,碎片化,松散,甚至不合邏輯、心口不一。
既然直男不能明白為什么女朋友會生氣,那計算機當然無法理解A叫B為孫子的時候,是在喊親戚、罵街,或只是朋友間的玩笑。
面對人類,計算機相當于是金剛隕石直男。
正是由于人工智能技術的發(fā)展,不斷讓我們相信,計算機總有一天可以聽懂人類表達,甚至像真人一樣和人溝通。那么,就讓我們開始這算美好的教程吧。
創(chuàng)建一個NLP Pipeline
London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium.
倫敦,是英國的首都,人口居全國之首。位于大不列顛島東南方泰晤士河流域,在此后兩個世紀內(nèi)為這一地區(qū)最重要的定居點之一。它于公元50年由羅馬人建立,取名為倫蒂尼恩。
-- 維基百科
Step 1:斷句(句子切分)
上面介紹倫敦的一段話,可以切分成3個句子:
倫敦是大不列顛的首都,人口居全國之首(London is the capital and most populous city of England and the United Kingdom)
位于泰晤士河流域(Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia)
它于公元50年由羅馬人建立,取名為倫蒂尼恩(It was founded by the Romans, who named it Londinium)
Step 2:分詞
由于中文的分詞邏輯和英文有所不同,所以這里就直接使用原文了。接下來我們一句一句的處理。首先第一句:
“London”, “is”, “ the”, “capital”, “and”, “most”, “populous”, “city”, “of”, “England”, “and”, “the”, “United”, “Kingdom”, “.”
英文的分詞相對簡單一些,兩個空格之間可以看做一個詞(word),標點符號也有含義,所以把標點符號也看做一個詞。
Step 3:區(qū)分單詞的角色
我們需要區(qū)分出一個詞在句子中的角色,是名詞?動詞?還是介詞。我們使用一個預先經(jīng)過幾百萬英文句子訓練、被調(diào)教好的詞性標注(POS: Part Of Speech)分類模型:

這里有一點一定要記住:模型只是基于統(tǒng)計結果給詞打上標簽,它并不了解一個詞的真實含義,這一點和人類對詞語的理解方式是完全不同的。
處理結果:

可以看到。我們等到的信息中,名詞有兩個,分別是倫敦和首都。倫敦是個獨特的名稱,首都是個通用的稱謂,因此我們就可以判斷,這句話很可能是在圍繞倫敦這個詞說事兒。
Step 4: 文本詞形還原
很多基于字母拼寫的語言,像英語、法語、德語等,都會有一些詞形的變化,比如單復數(shù)變化、時態(tài)變化等。比如:
I had a pony(我有過一匹矮馬)
I have two ponies (我有兩匹矮馬)
其實兩個句子的關鍵點都是矮馬pony。Ponies和pony、had和have只是同一個詞的不同詞形,計算機因為并不知道其中的含義,所以在它眼里都是完全不一樣的東西,
讓計算機明白這個道理的過程,就叫做詞形還原。對之前有關倫敦介紹的第一句話進行詞形還原后,得到下圖

Step 5:識別停用詞
停用詞:在信息檢索中,為節(jié)省存儲空間和提高搜索效率,在處理自然語言數(shù)據(jù)(或文本)之前或之后會自動過濾掉某些字或詞,這些字或詞即被稱為Stop Words(停用詞)。這些停用詞都是人工輸入、非自動化生成的,生成后的停用詞會形成一個停用詞表。但是,并沒有一個明確的停用詞表能夠適用于所有的工具。甚至有一些工具是明確地避免使用停用詞來支持短語搜索的。
-- 維基百科
還是來看第一句話:

其中灰色的字,僅僅是起到銜接和輔助表述的作用。他們的存在,對計算機來說更多是噪音。所以我們需要把這些詞識別出來。
正如維基所說,現(xiàn)在雖然停用詞列表很多,但一定要根據(jù)實際情況進行配置。比如英語的the,通常情況是停用詞,但很多樂隊名字里有the這個詞,The Doors, The Who,甚至有個樂隊直接就叫The The!這個時候就不能看做是停用詞了。
Step 6:解析依賴關系
解析句子中每個詞之間的依賴關系,最終建立起一個關系依賴樹。這個數(shù)的root是關鍵動詞,從這個關鍵動詞開始,把整個句子中的詞都聯(lián)系起來。
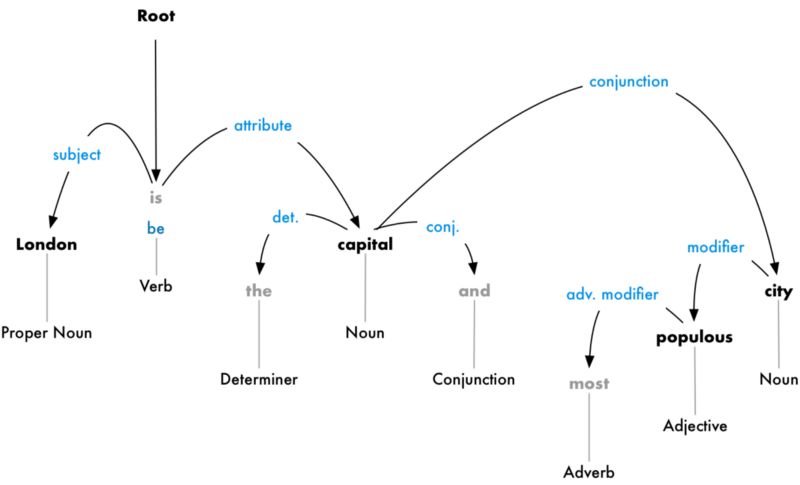
從這個關系樹來看,主語是London,它和capital被be聯(lián)系起來。然后計算機就知道,London is a capital。如此類推,我們的計算機就被訓練的掌握越來越多的信息。
但因為人類語言的歧義性,這個模型依然無法適應所有場景。但是隨著我們給他更多的訓練,我們的NLP模型會不斷提高準確性。Demo地址
https://explosion.ai/demos/displacy?utm_source=AiHl0
我們還可以選擇把相關的詞進行合并分組,例如把名詞以及修飾它的形容詞合并成一個詞組短語。不過這一步工作不是必須要有的,視具體情況而定。

Step 7:命名實體識別
經(jīng)過以上的工作,接下來我們就可以直接使用現(xiàn)有的命名實體識別(NER: Named Entity Recognition)系統(tǒng),來給名詞打標簽。比如我們可以把第一句話當中的地理名稱識別出來:

大家也可以通過下面的鏈接,在線體驗一下。隨便復制粘貼一段英文,他會自動識別出里面包含哪些類別的名詞:
https://explosion.ai/demos/displacy-ent?utm_source=AiHl0
Step 8:共指消解
人類的語言很復雜,但在使用過程中卻是傾向于簡化和省略的。比如他,它,這個,那個,前者,后者…這種指代的詞,再比如縮寫簡稱,北京大學通常稱為北大,中華人民共和國通常就叫中國。這種現(xiàn)象,被稱為共指現(xiàn)象。
在特定語境下人類可以毫不費力的區(qū)別出它這個字,到底指的是牛,還是手機。但是計算機需要通過共指消解才能知道下面這句話
它于公元50年由羅馬人建立,取名為倫蒂尼恩
中的它,指的是倫敦,而不是羅馬,不是羅紋,更不是蘿卜。
共指消解相對而言是我們此次創(chuàng)建NLP Pipeline所有環(huán)節(jié)中,最難的部分。
Coding
好了。思路終于講完了。接下來就是Coding的部分。首先我們理一下思路
提示:上述步驟只是標準流程,實際工作中需要根據(jù)項目具體的需求和條件,合理安排順序。
安裝spaCy
我們默認你已經(jīng)安裝了Python 3。如果沒有的話,你知道該怎么做。接下來是安裝spaCy:

安裝好以后,使用下面代碼

結果如下

GPE:地理位置、地名
FAC:設施、建筑
DATE:日期
NORP:國家、地區(qū)
PERSON:人名
我們看到,因為Londinium這個地名不夠常見,所以spaCy就做了一個大膽的猜測,猜這可能是個人名。
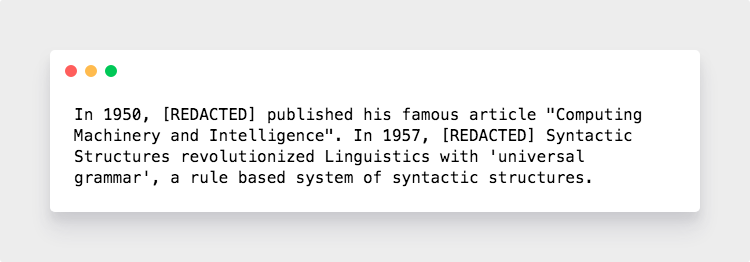
我們接下來進一步,構建一個數(shù)據(jù)清理器。假設你拿到了一份全國酒店入住人員登記表,你想把里面的人名找出來替換掉,而不改動酒店名、地名等名詞,可以這樣做:

把所有標注為[PERSON]的詞都替換成REDACTED。最終結果
提取詳細信息
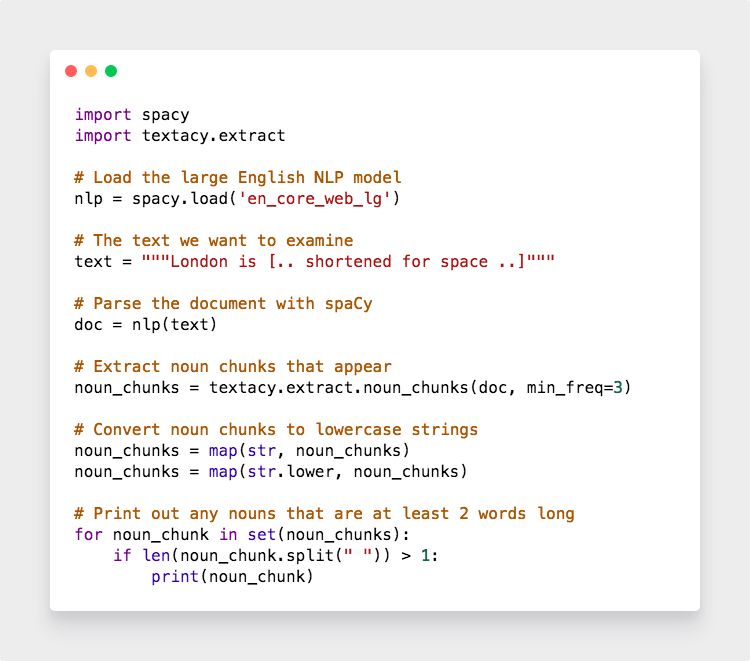
利用spaCy識別并定位的名詞,然后利用textacy就可以把一整篇文章的信息都提取出來。我們在wiki上復制整篇介紹倫敦的內(nèi)容到以下代碼

你會得到如下結果

我們獲得了這么多有用的信息,就可以應用在很多場景下。比如,搜索結果的相關推薦:
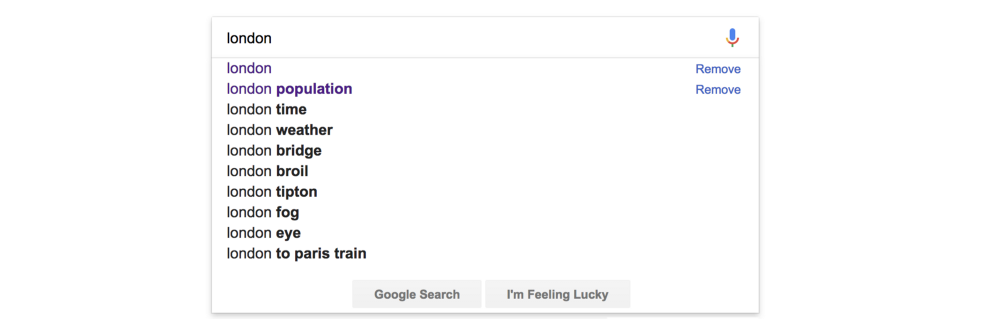
我們可以通過下面這種方法實現(xiàn)上圖的效果
-
計算機
+關注
關注
19文章
7488瀏覽量
87859 -
人工智能
+關注
關注
1791文章
47206瀏覽量
238274 -
python
+關注
關注
56文章
4792瀏覽量
84631
原文標題:用Python構建NLP Pipeline,從思路到具體代碼,這篇文章一次性都講到了
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
計算機語言概述
AI語音識別市場規(guī)模怎么樣?
計算機語言概述

感知計算機,靈感來自人類大腦的全新計算機架構

基于邏輯語言計算機軟件設計(JAVA語言)
研發(fā)聲音激活的計算機系統(tǒng),可識別人類語言
計算機編程語言的發(fā)展趨勢分析
NLP不僅可以做到幫助計算機學習并理解我們的語言
如何使用計算機讓機器人理解人類語言以及含義

計算機視覺:AI如何識別與理解圖像






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論