 基于深度學習的目標檢測來實現監控系統的快速教程
基于深度學習的目標檢測來實現監控系統的快速教程
【導讀】這是一篇關于使用基于深度學習的目標檢測來實現監控系統的快速教程。在教程中通過使用 GPU 多處理器來比較不同目標檢測模型在行人檢測上的性能。
監控是安保和巡邏的一個組成部分,大多數情況下,這項工作都是在長時間去觀察發現那些我們不愿意發生的事情。然而突發事件發生的低概率性無法掩蓋監控這一平凡工作的重要性,這個工作甚至是至關重要的。
如果有能夠代替我們去做“等待和監視”突發事件的工具那就再好不過了。幸運的是,這些年隨著技術的進步,我們已經可以編寫一些腳本來自動執行監控這一項任務。在深入探究之前,需要我們先考慮兩個問題。
機器是否已經達到人類的水平?
任何熟悉深度學習的人都知道圖像分類器的準確度已經趕超人類。圖1顯示了近幾年來對于人類、傳統計算機視覺 (CV) 和深度學習在 ImageNet 數據集上的分類錯誤率。
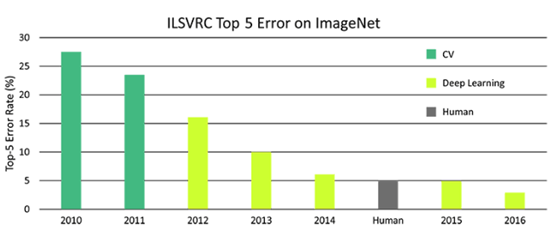
圖 1 人類、深度學習和 CV 在 ImageNet 上分類錯誤率
與人類相比,機器可以更好地監視目標,使用機器進行監視效率更高,其優點可總結如下:
重復的任務會導致人類注意力的下降,而使用機器進行監視時并無這一煩惱,我們可以把更多的精力放在處理出現的突發事件上面。
當要監視的范圍較大時,需要大量的人員,固定相機的視野也很有限。但是通過移動監控機器人 (如微型無人機) 就能解決這一問題。
此外,同樣的技術可用于各種不受限于安全性的應用程序,如嬰兒監視器或自動化產品交付。
那我們該如何實現自動化?
在我們討論復雜的理論之前,先讓我們看一下監控的正常運作方式。我們在觀看即時影像時,如果發現異常就采會取行動。因此我們的技術也應該通過仔細閱讀視頻的每一幀來發現異常的事物,并判斷這一過程是否需要報警。
大家可能已經知道了,這個過程實現的本質是通過目標檢測定位,它與分類不同,我們需要知道目標的確切位置,而且在單個圖像中可能有多個目標。為了更好的區分我們舉了一個簡單形象的例子如圖2所示。
圖2 分類、定位、檢測和分割的示例圖
為了找到確切的位置,我們的算法應該檢查圖像的每個部分,以找到某類的存在。自2014年以來,深度學習的持續迭代研究引入了精心設計的神經網絡,它能夠實時檢測目標。圖3顯示了近兩年R-CNN、Fast R-CNN 和 Faster R-CNN 三種模型的檢測性能。
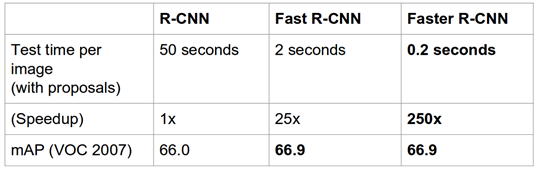
圖3 R-CNN、Fast R-CNN 和 Faster R-CNN 性能
這里有幾種在內部使用的不同方法來執行相同任務的深度學習框架。其中最流行的是 Faster-RCNN、YOLO 和 SSD。圖4展示了 Faster R-CNN、R-FCN 和 SSD 的檢測性能。
圖4 Faster R-CNN、R-FCN 和 SSD 的檢測性能,速度與準確性的權衡,更高的 mpA 和更低的 GPU 時間是最佳的。
每個模型都依賴于基礎分類器,這極大影響了最終的準確性和模型大小。此外,目標檢測器的選擇會嚴重影響計算復雜性和最終精度。在選擇目標檢測算法時,速度、精度和模型大小的權衡關系始終存在著。
在有了上面的學習了解后,接下來我們將學習如何使用目標檢測構建一個簡單而有效的監控系統。
我們先從由監視任務的性質而引起的限制約束開始討論起。
深度學習在監控中的限制
在實現自動化監控之前,我們需要考慮以下幾個因素:
1.即時影像
為了在大范圍內進行觀察,我們可能需要多個攝像頭。而且,這些攝像頭需要有可用來存儲數據的地方 (本地或遠程位置)。圖5為典型的監控攝像頭。
圖5 典型的監控攝像頭
高質量的視頻比低質量的視頻要占更多的內存。此外,RGB 輸入流比 BW 輸入流大3倍。由于我們只能存儲有限數量的輸入流,故通常情況下我們會選擇降低質量來保證最大化存儲。
因此,可推廣的監控系統應該能夠解析低質量的圖像。同時我們的深度學習算法也必須在低質量的圖像上進行訓練。
2.處理能力
在哪里處理從相機源獲得的數據是另一個大問題。通常有兩種方法可以解決這一問題。
集中式服務器處理
來自攝像機的視頻流在遠程服務器或集群上逐幀處理。這種方法很強大,使我們能夠從高精度的復雜模型中獲益。但這種方法的缺點是有延遲。此外,如果不用商業 API,則服務器的設置和維護成本會很高。圖6顯示了三種模型隨著推理時間的增長內存的消耗情況。
圖6 內存消耗與推理時間(毫秒),大多數高性能模型都會占用大量內存
分散式邊緣處理
通過附加一個微控制器來對相機本身進行實時處理。優點在于沒有傳輸延遲,發現異常時還能更快地進行反饋,不會受到 WiFi 或藍牙的限制 (如 microdrones)。缺點是微控制器沒有 GPU 那么強大,因此只能使用精度較低的模型。使用板載 GPU 可以避免這一問題,但是太過于昂貴。圖 7 展示了目標檢測器 FPS 的性能。
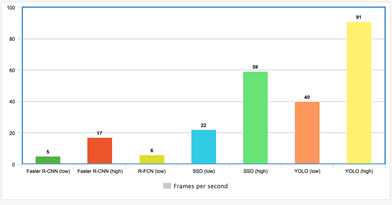
圖 7 各類目標檢測器 FPS 的性能
訓練監控系統
在接下來的內容里我們將會嘗試如何使用目標檢測進行行人識別。使用 TensorFlow 目標檢測 API 來創建目標檢測模塊,我們還會簡要的闡述如何設置 API 并訓練它來執行監控任務。整個過程可歸納為三個階段 (流程圖如圖8所示):
數據準備
訓練模型
推論
圖8 目標檢測模型的訓練工作流程
▌第1階段:數據準備
第一步:獲取數據集
監控錄像是獲取最準確數據集的來源。但是,在大多數情況下,想要獲取這樣的監控錄像并不容易。因此,我們需要訓練我們的目標檢測器使其能從普通圖像中識別出目標。
圖9 從數據集中提取出帶標注的圖像
正如前面所說,我們的圖像質量可能較差,所以所訓練的模型必須適應在這樣的圖像質量下進行工作。我們對數據集中的圖像 (如圖9所示) 添加一些噪聲或者嘗試模糊和腐蝕的手段,來降低數據集中的圖片質量。
在目標檢測任務中,我們使用了 TownCentre 數據集。使用視頻的前3600幀進行訓練,剩下的900幀用于測試。
第二步:圖像標注
使用像 LabelImg 這樣的工具進行標注,這項工作雖然乏味但也同樣很重要。我們將標注完的圖像保存為 XML 文件。
第三步:克隆存儲庫
運行以下命令以安裝需求文件,編譯一些 Protobuf 庫并設置路徑變量
pipinstall-rrequirements.txtsudoapt-getinstallprotobuf-compilerprotocobject_detection/protos/*.proto--python_out=.exportPYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
第四步:準備所需的輸入
首先,我們需要給每個目標一個標簽,并將文件中每個標簽表示為如下所示的label_map.pbtxt
item{id:1name:‘target’}
接下來,創建一個包含 XML 和圖像文件名稱的文本文件。例如,如果數據集中有 img1.jpg, img2.jpg, 和 img1.xml, img2.xml ,則 trainval.txt 文件的表示應如下所示:
img1img2
將數據集分為兩個文件夾 (圖像與標注)。將 label_map.pbtx 和 trainval.txt放在標注文件夾中,然后在標注文件夾中創建一個名為 xmls 的子文件夾,并將所有 XML 文件放入該子文件夾中。目錄層次結構應如下所示:
-base_directory|-images|-annotations||-xmls||-label_map.pbtxt||-trainval.txt
第五步:創建 TF 記錄
API 接受 TPRecords 文件格式的輸入。使用 creat_tf_record.py 文件將數據集轉換為 TFRecords。我們應該在 base directory 中執行以下命令:
pythoncreate_tf_record.py--data_dir=`pwd`--output_dir=`pwd`
在該程序執行完后,我們可以獲取 train.record 和 val.record 文件。
▌第2階段:訓練模型
第1步:模型選擇
如前所述,速度與準確度兩者不可得兼,從頭開始創建和訓練目標檢測器是非常耗時的。因此, TensorFlow 目標檢測 API 提供了一系列預先訓練好的模型,我們可以根據自己的使用情況進行微調,該過程稱為遷移學習,它可以大大提高我們的訓練速度。
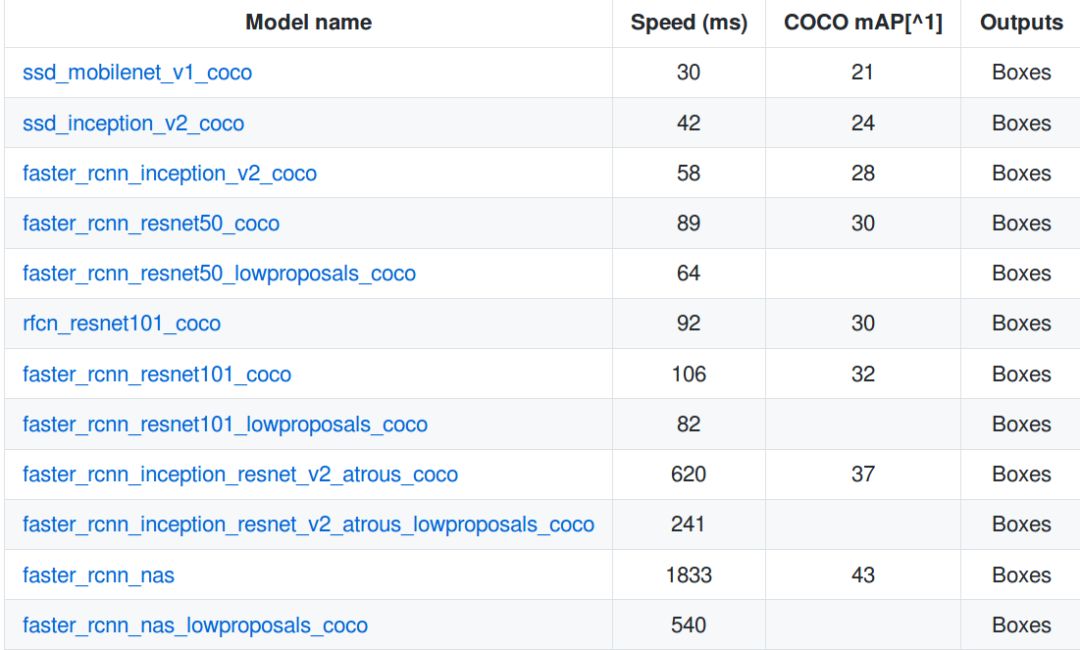
圖10 MS COCO 數據集中一組預訓練過的模型
從圖 10 中下載一個模型,并將內容解壓縮到 base directory 中。可獲取模型檢查點,固定推理圖和 pipeline.config 文件。
第2步:定義訓練工作
我們必須在 pipleline.config 文件中定義“訓練工作”,并將該文件放到 base directory 中。該文件中最重要的是后幾行——我們只需將突出顯示的值放到各自的位置。
gradient_clipping_by_norm:10.0fine_tune_checkpoint:"model.ckpt"from_detection_checkpoint:truenum_steps:200000}train_input_reader{label_map_path:"annotations/label_map.pbtxt"tf_record_input_reader{input_path:"train.record"}}eval_config{num_examples:8000max_evals:10use_moving_averages:false}eval_input_reader{label_map_path:"annotations/label_map.pbtxt"shuffle:falsenum_epochs:1num_readers:1tf_record_input_reader{input_path:"val.record"}}
第3步:開始訓練
執行以下命令以啟動訓練工作,建議使用具有足夠大的 GPU 計算機,以便加快訓練過程。
pythonobject_detection/train.py--logtostderr--pipeline_config_path=pipeline.config--train_dir=train
▌第3階段:推論
第1步:導出訓練模型
在模型使用之前,需要將訓練好的檢查點文件導出到固定推理圖上,實現這個過程并不困難,只需要執行以下代碼 (用檢查點替換“xxxxx”)
pythonobject_detection/export_inference_graph.py--input_type=image_tensor--pipeline_config_path=pipeline.config--trained_checkpoint_prefix=train/model.ckpt-xxxxx--output_directory=output
該程序執行完后,我們可得到 frozen_inference_graph.pb 以及一堆檢查點文件。
第2步:在視頻流上使用
我們需要從視頻源中提出每一幀,這可以使用 OpenCV 的 VideoCapture 方法完成,代碼如下所示:
cap=cv2.VideoCapture()flag=Truewhile(flag):flag,frame=cap.read()##--ObjectDetectionCode--
第一階段使用的數據提取代碼會使我們的測試集圖像自動創建“test_images”文件夾。我們的模型可以通過執行以下命令在測試集上進行工作:
pythonobject_detection/inference.py--input_dir={PATH}--output_dir={PATH}--label_map={PATH}--frozen_graph={PATH}--num_output_classes=1--n_jobs=1--delay=0
實驗
正如前面所講到的,在選擇目標檢測模型時,速度與準確度不可得兼。對此我們進行了一些實驗,測量使用三種不同的模型檢測到人的 FPS 和數量精確度。此外,我們的實驗是在不同的資源約束 (GPU并行約束) 條件下操作的。
▌設置
我們的實驗選擇了以下的模型,這些模型可以在 TensorFlow 目標檢測API 的Zoo 模塊中找到。
Faster RCNN with ResNet 50
SSD with MobileNet v1
SSD with InceptionNet v2
所有的模型都在 Google Colab 上進行了 10k 步訓練,通過比較模型檢測到的人數與實際人數之間的接近程度來衡量計數準確度。在一下約束條件下測試 FPS 的推理速度。
Single GPU
Two GPUs in parallel
Four GPUs in parallel
Eight GPUs in parallel
結果
下面的 GIF是我們在測試集上使用 FasterRCNN 輸出的片段。
▌訓練時間
圖11展示了以10 k步 (單位:小時) 訓練每個模型所需的時間 (不包括參數搜索所需要的時間)
圖11 各模型訓練所需時間
▌速度 (每秒幀數)
在之前的實驗中,我們測量了3種模型在5種不同資源約束下的 FPS 性能,其測量結果如圖12所示:
圖12 使用不同 GPU 數量下的 FPS 性能
當我們使用單個 GPU 時,SSD速度非常快,輕松超越 FasterRCNN 的速度。但是當 GPU 個數增加時,FasterRCNN 很快就會追上 SSD 。
為了證明我們的結論:視頻處理系統的速度不能高于圖像輸入系統的速度,我們優先讀取圖像。圖13展示了添加延遲后帶有 NobileNet +SSD 的 FPS 改進狀況,從圖13中可看出當我們加入延遲后,FPS 迅速增加。
圖13 增加不同延遲后模型的 FPS 改進狀況
▌計數準確性
我們將計數準確度定義為目標檢測系統正確識別出人臉的百分比。圖14是我們每個模型精確度的表現,從圖14中可看出 FasterRCNN 是準確度最高的模型,MobileNet 的性能優于 InceptionNet。
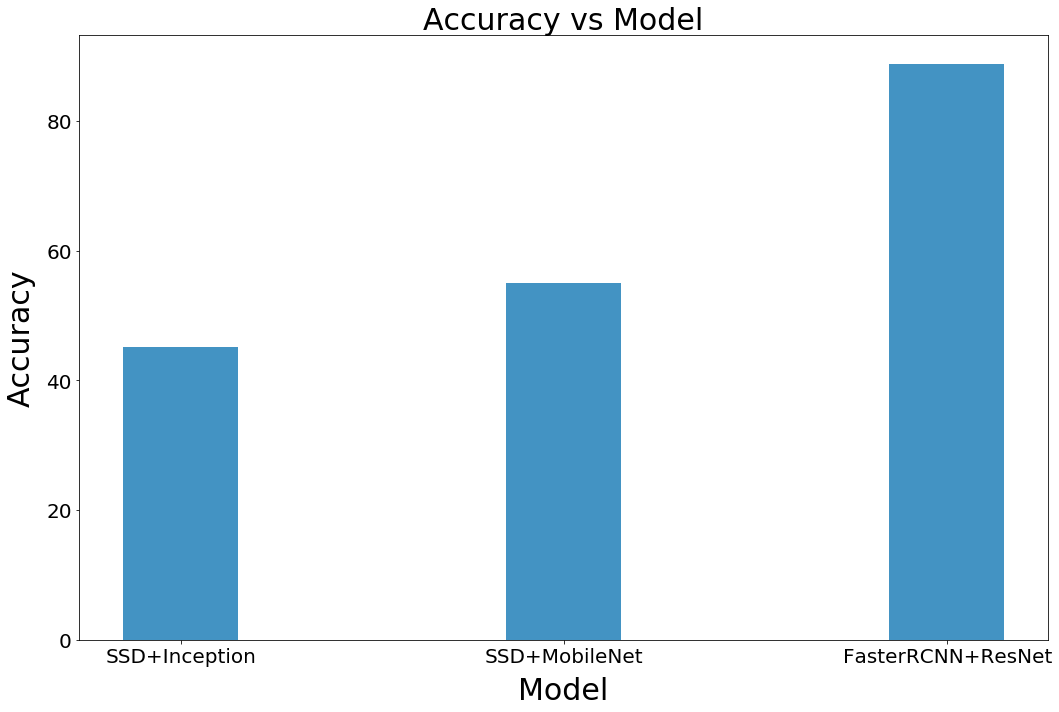
圖 14 各模型計數精確度
Nanonets
看到這里相信大家都有一個共同的感受——步驟太多了吧!是的,如果是這樣的一個模型在實際工作即繁重又昂貴。
為此,更好的解決方案就是使用已部署在服務器上的 API 服務。Nanonets 就提供了這樣的一個 API,他們將 API 部署在帶有 GPU 的高質量硬件上,以便開發者不用為性能而困擾。
Nanonets可以減少工作的流程的方法在于:我將現有的 XML 注釋轉換成 JSON 格式并提供給NanonetsAPI。所以當不想進行手動注釋數據集時,可以直接請求NanonetsAPI來為數據添加注釋。
上圖表示為減少后的工作流程
Nanonets 的訓練時間大約花了 2 個小時,就訓練時間而言,Nanonets是明顯的贏家,并且在準確性方面Nanonets也擊敗了 FasterRCNN。
FasterRCNNCountAccuracy=88.77%NanonetsCountAccuracy=89.66%
下面展現了我們的測試數據集中四個模型的性能。顯然,兩種 SSD 模型都有點不穩定并且精度較低。盡管 FasterRCNN 和 Nanonets 都有較高的精準度,但Nanonets具有更穩定的邊界框。
自動監控的可信度有多高?
深度學習是一種令人驚嘆的工具。但是我們在多大程度上可以信任我們的監控系統并自動采取行動?在以下幾個情況下,自動化過程時需要引起注意。
▌可疑的結論
我們不知道深度學習算法是如何得出結論的。即使數據的饋送過程很完美,也可能存在大量虛假的成功例子。雖然引導反向傳播在一定程度上可以解釋決策,但是關于這方面的研究還有待我們進一步的研究。
▌對抗性攻擊
深度學習系統很脆弱,對抗性攻擊類似于圖像的視錯覺。計算出的不明顯干擾會迫使深度學習模型分類失誤。使用相同的原理,研究人員已經能夠通過使用 adversarial glasses 來規避基于深度學習的監控系統。
▌誤報
另一個問題是,如果出現誤報我們該怎么做。該問題的嚴重程度取決于應用程序本身。例如邊境巡邏系統的誤報可能比花園監控系統更重要。
▌相似的面孔
外觀并不像指紋一樣獨一無二,同卵雙胞胎是最好的一個例子。這會帶來恨大的干擾。
▌數據集缺乏多樣性
深度學習算法的好壞和數據集有很大關聯,Google 曾將一個黑人錯誤歸類為大猩猩。
注:鑒于 GDPR 和以上原因,關于監控自動化的合法性和道德性問題是不可忽視的。此教程也是出于并僅用于學習分享目的。在教程中使用的公開數據集,所以在使用過程中有責任確保它的合法性。
-
監控系統
+關注
關注
21文章
3904瀏覽量
174438 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
45980 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:如何通過深度學習輕松實現自動化監控?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度學習實現目標檢測俄羅斯總統***對沙特王儲攤的“友好攤手”瞬間
CV:基于深度學習實現目標檢測之GUI界面產品設計并實現圖片識別、視頻識別、攝像頭識別
全網唯一一套labview深度學習教程:tensorflow+目標檢測:龍哥教你學視覺—LabVIEW深度學習教程
【HarmonyOS HiSpark AI Camera】基于深度學習的目標檢測系統設計
探究深度學習在目標視覺檢測中的應用與展望
OpenCV使用深度學習做邊緣檢測的流程


如何學習基于Tansformer的目標檢測算法






 工商網監
工商網監
評論