 一種具有基于CNN的閉環反饋的用于自動駕駛車輛的端到端轉向控制器
一種具有基于CNN的閉環反饋的用于自動駕駛車輛的端到端轉向控制器
摘要:過去幾十年的許多重要研究成果表明,卷積神經網絡( CNNs )能夠控制方向盤,這是自動駕駛車輛的基本和必要的操作動作。與傳統的基于CNN的方法相比,我們提出了一種具有基于CNN的閉環反饋的用于自動駕駛車輛的端到端轉向控制器,該控制器提高了駕駛性能。本文證明了所提出的神經網絡DAVE - 2SKY能夠通過初始監督預訓練和隨后的強化閉環后訓練,利用安裝在車輛上的攝像機的圖像來學習推斷方向盤角度,用于自動駕駛車輛的橫向控制。
我們使用PreScan仿真器和Caffe深度學習框架在環境軟件(SIL)仿真環境中進行多種環境下的訓練。我們使用DRIVE PX2計算機來實現一輛自動駕駛汽車對所提議的端到端控制器進行的實驗驗證。仿真和道路試驗也研究了該系統的性能。這項工作表明,基于CNN的端到端控制器即使在部分可觀察的道路條件下也能執行強大的轉向控制,這表明由基于CNN的端到端轉向控制器控制完全自動駕駛車輛的可能性。
I.介紹
在過去幾十年中,在工業機構包括汽車原始設備制造商( OEMs )、相關公司、研究機構和大學的不斷努力下,自動駕駛技術取得了顯著成就。此外,機器學習的重大進步使得使用深層神經網絡的自動駕駛車輛創新方法成為可能。
特別是,卷積神經網絡(CNN)[1]已經被證明具有實現方向盤控制的端到端學習的潛力,這是自動駕駛車輛的基本和必要的操作基礎。為了構建一個完全自我優化的學習系統,以最大限度地提高軌跡跟蹤和駕駛安全性能,而不是使用基于模型的中間控制標準,從一個面向前方的車載攝像頭學習方向盤的角度,我們開發了一個加強的閉環反饋訓練和推理架構。
1989年,卡內基梅隆大學開發了一種名為自主陸地車輛神經網絡(ALVINN)的自動駕駛汽車[2],該車首次展示了基于攝像頭的自動駕駛汽車端對端轉向控制的可能性。自ALVINN以來,其他值得關注的研究工作包括已經研究了神經網絡(NNs)和國防高級研究項目局(DARPA)的挑戰,這些挑戰促進了神經網絡的發展。
2004年,DARPA自主車輛( DAVE ) [ 3 ]項目演示了如何對一輛無線電控制( RC )汽車進行訓練,使其掌握由左、右攝像機拍攝的幾小時人類駕駛數據,并在越野環境中駕駛。雖然DAVE無法展示復雜駕駛環境的完整解決方案,但它激發了一個名為DAVE-2的高級版本[4]。
在自動駕駛車輛中,包括車輛轉向在內的橫向控制是一項基本功能。車道保持是橫向控制的代表性操作,在自動駕駛時可將車輛保持在車道的中心。雖然轉向控制是自動駕駛車輛的基本功能,但基于CNN的端到端控制器仍然難以在自動駕駛車輛中實現轉向[5]。
我們的目標是克服傳統的基于CNN的端到端控制方法的局限性,為自主車輛的轉向控制器提供一種前沿方法。我們提出了DAVE - 2SKY ( SK Telecom & Yonsei University修改的DAVE - 2 ),這是一種端到端轉向控制器,具有基于CNN的閉環反饋體系結構。網絡沒有被明確教導,并且學習轉向控制在跟蹤前方車輛時保持車道所需的整個處理流水線。學習過程由兩個訓練步驟組成:監督的預訓練和強化的閉環反饋后訓練。因此,DAVE - 2SKY從相機圖像數據中產生適當的方向盤角度,用于自動駕駛車輛的穩定和完全橫向控制。與DAVE-2 [4]的傳統反向傳播訓練方法相比,所提出的系統能夠在更短的訓練時間內學習駕駛任務,并具有穩健的、可改進的性能。
本文的其余部分結構如下:在第Ⅱ節,我們提供了所提出的系統DAVE - 2SKY的概述和細節。在第V節中的實驗結果之前,第III節和第IV節介紹了使用仿真器實施SIL的環境和結果。在第VI節中,我們討論了該系統仿真中的結果,最后,我們在第VII節中總結了本文。
Ⅱ.我們所提出的系統
A.網絡架構
我們的網絡有一個源自DAVE - 2 [ 4 ]的架構,該架構利用安裝在自主車輛上的輸入相機的圖像來訓練NNs,以計算方向盤角度來進行橫向控制。圖2中顯示的DAVE-2SKY是使用Caffe深度學習框架[6]實現的。歐幾里德損失模型用于計算地面實況和預測方向盤角度之間的平方誤差之和,如[7]。
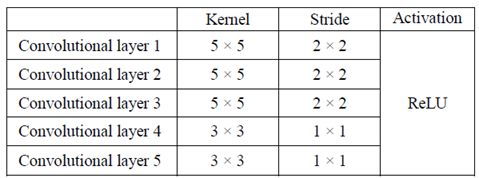
NN由10層組成,包括5個卷積層,3個歸一化層和2個完全連接的層,如圖1所示。如表I所示,前三個卷積層各有一個5×5內核和一個2×2跨距,接下來的兩個卷積層各有一個2×2內核和一個1×1跨距。在每個卷積層中都使用了整流線性單元(ReLU)激活。輸入圖像被分成RGB平面,然后傳送到網絡。卷積層被設計為特征提取器,完全連接層是用于操縱車輛的控制器。在卷積層2、3和4之前添加歸一化層,以避免梯度消失/爆炸問題,并通過穩定訓練過程來提高訓練速度[ 8 ]。
圖1.所提出的DAVE-2SKY CNN架構。
表I.DAVE-2SKY網絡卷積層
B.加強閉環反饋后訓練系統
基于DAVE - 2 [ 4 ]的DAVE - 2SKY系統可以在強化反饋回路中推斷轉向控制指令。DAVE - 2SKY可以通過兩個步驟進行訓練,包括監督的預培訓和強化的閉環反饋后培訓。下面解釋兩個訓練步驟結合的原因。
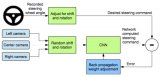
監督的預訓練是圖2 ( a )所示架構的第一步。我們實現了類似于傳統訓練系統的SIL配置,PreScan仿真器在PC上運行,基于Caffe深度學習框架的CNN訓練架構在DevBox計算機上運行。來自攝像機的圖像被饋送到DAVE-2SKY以產生方向盤角度,該方向盤角度將與記錄的可行方向盤角度進行比較,以使用反向傳播機制來調整卷積網絡的濾波器的權重。我們在受監督的預訓練步驟中訓練DAVE-2SKY進行有限次數的迭代,在本研究中少于80,000個周期。兩***立的計算機,用于仿真器的PC和DevBox,通過用戶數據報協議( UDP )網絡進行通信。
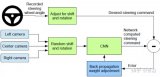
在預訓練步驟之后,DAVE-2SKY在加強的訓練后步驟中接受訓練。為了反饋回路,我們形成了一個獨特的SIL閉環體系結構,由運行在PC上的PreScan仿真器和MATLAB Simulink以及運行在DevBox計算機上的Caffe深度學習框架組成,如圖2 ( b )所示。
圖2.訓練神經網絡的框圖,DAVE - 2SKY :( a )有監督的預訓練;( b )強化閉環反饋后培訓。
在PreScan仿真中,我們使用了一輛帶有前置攝像頭的虛擬車輛。通過使用MATLAB Simulink的一個內置插件,我們在仿真過程中獲取了車輛的內部狀態和攝像機的圖像數據。這些狀態數據表示車輛的當前狀態,例如速度、位置、航向和橫擺角速度。車輛狀態被送入預覽驅動模型 (PDM),這是由仿真器配置的內置控制器模型,用于產生所需的方向盤角 (dd),方法是使用作者團隊 [9.10] 提供的算法。在本研究中,PDM預測的轉向輸出被用作基本事實。使用方向盤上的接口設備,如Logitech G27,可以用人工駕駛代替PDM。這種靈活性使我們能夠將訓練有素的DAVE - 2SKY轉移到一輛真正的自動駕駛汽車上進行道路試驗。
與常規監督訓練相比,所提出的兩個訓練步驟可提高學習效率和車輛操縱性能,原因可解釋如下。從前置攝像頭獲取NN的圖像數據并發送到DevBox。除了常規深層神經網絡訓練程序的正常反向傳播機制之外,DAVE - 2SKY還在閉環反饋架構中以強化的方式接受訓練。與典型的CNN類似,DAVE-2SKY將獲取的像素映射到方向盤角度(δC)。反向傳播機制[1]調整網絡的CNN濾波器的權重,以最小化δD和δC之間的誤差。然后,修正了方向盤角度(δD'),由CNN網絡根據調整后的重量,作為控制輸入被輸入到車輛。因此,在所提出的訓練后配置中嵌入了強化學習例程。
如前所述,訓練有素的NN DAVE-2SKY是自動駕駛車輛的控制器。傳統的簡單監督預訓練步驟可能不足以學習機動車輛所需的仿人端到端視覺智能。涉及閉環反饋的訓練后步驟允許在SIL環境中加強學習。如果我們用駕駛仿真器中的人類駕駛員代替PDM,DAVE - 2SKY可以學習啟發式駕駛體驗。
III.仿真環境
PreScan仿真器允許構建具有真實配置的虛擬驗證環境,以使用虛擬車輛模型獲取豐富的信息。使用Simulink和PreScan的插件收集訓練數據集。在仿真中使用具有默認物理模型和動態配置的虛擬車輛(奧迪A6)。如圖3所示,單個虛擬前置攝像頭安裝在虛擬車輛上。車輛的可控方向盤角度范圍為-500°至+ 500°。方向盤角度的符號表示方向盤的方向為順時針為負,逆時針為正,并且車輛的轉向比[11]設定為20:1。如圖4所示,行駛軌道長度為1492米,由兩條車道( 4米寬)組成。車道被黃色實線隔開,道路兩側都有人行道(高2m )。在仿真自動巡航控制和車道保持機動的過程中,我們將車輛速度設定為5m / s ( 18 km / h )的恒定速度。
圖3.安裝在虛擬車輛上的前置攝像頭傳感器。
A.數據收集和預處理
我們的目的是訓練系統來評估橫向控制能力;因此,只需要車輛的圖像和方向盤角度數據。當車輛在軌道上逆時針行駛時(圖4 ),數據以10hz的頻率提取。車輛狀態數據與幀號同步0.1s。用160×90像素幀捕獲圖像數據,然后裁剪到160×40像素,以消除不必要的上層像素信息,如天空、樹木或遠離道路的建筑物。方向盤角度數據是從內置的PDM算法獲得的,該算法被用作車輛控制器模型,以獲得精確的方向盤角度控制數據。因為PDM根據道路環境和車輛狀態產生精確的實時值,我們應該擴展它以獲得更廣泛的學習范圍。我們有意在PDM的方向盤角度輸出中添加范圍從–50到+ 50的隨機干擾。隨機干擾的目的是確定所提出的訓練回路對駕駛過程中可能出現的隨機干擾的魯棒性。
B.訓練
我們使用NVIDIA DevBox進行訓練,收集的圖像和方向盤角度數據是幀同步的。如第Ⅱ節所述,NN分兩個階段進行訓練。監督預訓練方法用80,000次迭代的數據訓練網絡。通過實驗找到迭代次數,以確定允許強化閉環反饋后訓練同時正確訓練和仿真的最少迭代次數。在預訓練之后,DAVE-2SKY模型經歷了訓練后的迭代。在訓練周期中,我們可以監控所有狀態數據,也可以可視化訓練和仿真環境,如圖5所示。
圖4.用于訓練和試駕仿真的軌道概述。
圖5.可視化仿真環境的截圖。
IV.仿真結果
通過仿真,我們打算通過允許自動駕駛車輛在SIL環境中的不同情況下巡航來研究所提出的端到端控制器的性能和能力。測試期間,車輛以順時針方向行駛,與訓練方向相反。通過在訓練和測試仿真過程中交替路線,我們可以輕松地為DAVE-2SKY網絡提供不同的體驗。
我們通過擾亂攝像機前方道路的視野范圍來調查端到端控制器的操作極限:我們在完全可觀察和部分可觀察的情況下仿真了轉向性能。需要各種駕駛條件,包括由擾亂完全觀察彎道的障礙物引起的完全以及部分可觀察的情況,以評估所提出的具有加強反饋回路的CNN模型如何能夠在車道保持操縱期間執行橫向控制。
完全可觀察的情況如圖6(b)所示實施,車輛獨自在軌道上行駛。對于部分可觀察的情況,如圖6(c)和6(d)所示,在距自我自動駕駛車輛不同距離處添加前方車輛。參數d定義為車輛后輪中心之間的距離,如圖6(a)所示。距離是確定前置攝像頭可觀測范圍的關鍵因素,我們在測試過程中將距離從7米改變為12米。在仿真期間,測試車輛以5m / s的恒定速度巡航。
圖6.輸入攝像機的視圖: ( a )距離d的定義;( b )完全可觀察到(無前方車輛);( c )部分可觀察到( d = 8m );( d )部分可觀察( d = 10m )的情況。
我們認為,如果車輛偏離車道,車道保持機動會出現故障。如果發生故障,則仿真暫停。來自控制器和前置攝像頭的所有數據與輸入圖像的幀數同步。地面實況由PDM的方向盤角度表示。跟蹤誤差是方向盤角度與第nth幀處的地面實況之間的差異。完整的仿真結束了大約3,001的幀數,因為車輛將返回到1,492米軌道的起始點,恒定巡航速度為5米/秒,并且在3,001幀內進行適當的車道保持操作。
A.完全可觀察的情況
圖7顯示了完全可觀察的案例的仿真結果。由DAVE-2SKY駕駛的車輛僅經過預訓練36小時即可成功駕駛車輛,直到到達圖4中標記的軌道的急彎位置。第1,500幀和第1,700幀之間軌道曲率的突然變化引起必要的轉向控制角度的快速變化以維持車道。因此,在車輛進入急劇彎曲的路段之后不久,車輛偏離其車道。此外,DAVE - 2SKY控制器通過主監督預訓練步驟和隨后的強化后訓練步驟成功地完成了全程軌道,并且與車道中心保持了可容忍的誤差距離。
B.部分可觀察的情況
在部分可觀察的情況下,每次嘗試通過DAVE-2SKY在預訓練步驟中駕駛車輛在仿真中都沒有成功,并且如果攝像機僅能部分地觀察彎道,則無法操縱車輛進行車道保持操縱。
如果距離d大于臨界值,由訓練有素的DAVE - 2SKY控制器控制的車輛可以將車道保持在容許誤差范圍內。在本文的仿真環境中,d的臨界值為9m。基于CNN的端到端控制器采用所提議的強化閉環訓練步驟進行訓練,在部分可觀察到的情況下表現出了更好的性能。
圖7.DAVE-2SKY充分觀測情況下的仿真結果:(a)方向盤角度(上);(b) PDM的參考值(即仿真中的地面真實值)與推理輸出值(下限)之間的誤差。
當前方行駛的車輛離自我駕駛車輛太近時,彎道的大部分輸入信息都會被前方車輛屏蔽。然而,如果在外部仿真中距離大于9m,車輛可以成功地在軌道上巡航,同時保持其車道在容許誤差范圍內。圖8中呈現的仿真結果有點嘈雜,但盡管在仿真期間施加了額外的干擾,但車輛仍然成功地行駛。
圖8.DAVE-2SKY部分可見情況下的仿真結果:(a)方向盤角度(上);(b) PDM的參考值(即仿真中的地面實況)與推理輸出值(下限)之間的誤差。
V.實驗結果
由于多個仿真已經證明了車道保持任務的可接受性能,因此DAVE-2SKY使用DRIVE?PX2計算機集成到真實的自動駕駛車輛中,用于實驗真實道路自動駕駛測試,如圖9和圖10所示。
通過應用第III節中描述的程序,收集并預處理真實道路的圖像數據以用于實際車輛的訓練。收集的數據集包含了延世大學國際圖8中行駛2小時以上的圖像。收集到的數據集包含Yonsei大學國際校區行駛2小時以上的圖像(環境如圖10所示)。在數據收集過程中,一名熟練的駕駛員駕駛車輛保持車道不偏離。
使用所提出的兩種連續訓練方法訓練該車輛72小時。然后,訓練好的模型被轉移到安裝在車輛上的PX - 2計算機上進行實驗性真實道路測試。在測試過程中,我們還評估了一個基于先前文章《[ 12,13]》的自動停車算法的代客停車場景。實驗驗證了應用于DAVE - 2SKY控制器的上述技術可能能夠對自動駕駛車輛進行縱向控制。實驗視頻顯示在YouTube [14,15]上。由于長度限制,我們省略了本文中實驗場景和相應數據的詳細信息。
圖9.實驗自主真實道路駕駛測試的測試車輛實施
圖10.自動駕駛的實驗路線,以及道路測試下車輛的快照照片
Ⅵ.討論
對完全和部分可觀察到的情況的仿真顯示了用所提議的步驟訓練的DAVE - 2SKY的獨特能力。第IV節中描述的仿真結果表明,僅通過監督預訓練自學的模型(其具有與傳統端到端CNN模型相似的特性)無法對車道保持任務執行適當的橫向控制。然而,盡管訓練周期數相似,但訓練后的加強閉環反饋實際上增強并改善了轉向控制的性能。
部分可觀察的案例顯示了DAVE-2SKY的穩健性。由于除了深NN中的反向傳播回路之外的閉環反饋系統,所提出的DAVE-2SKY即使在車道保持機動中的部分可觀察情況下也執行魯棒的轉向控制。仿真結果表明,DAVE - 2SKY能夠從軌道自巡航控制期間的少量干擾中恢復。結果支持了我們的斷言,即受監督的預訓練和隨后的訓練后步驟以及增強的閉環反饋使得端到端控制器能夠在合理的誤差范圍內對車道保持任務進行完全橫向控制。
Ⅶ.結論
我們提出了一種端到端轉向控制器,該控制器具有基于CNN的自主車輛閉環反饋,與傳統的基于CNN的方法相比,該控制器可提高控制性能。提議的NN,DAVE - 2SKY,能夠通過監督的預訓練和加強的閉環后訓練,利用安裝在車輛上的攝像機的圖像來學習控制方向盤角度,用于自動駕駛車輛的橫向控制。我們使用PreScan仿真器和Caffe深度學習框架在SIL仿真環境中進行多種環境下的訓練。通過仿真和路況試驗,研究了該系統的性能。我們使用DRIVE PX2計算機實現了一輛自動駕駛汽車對所提議的端到端控制器進行了實驗驗證。總之,這項工作表明,基于CNN的端到端控制器即使在部分可觀察的情況下也能執行魯棒的轉向控制,這表明完全智能的自動駕駛車輛有可能由基于CNN的端到端轉向控制器控制。
致謝
這項工作得到了韓國科學和信通技術部的支持,并得到了信息和通信技術促進研究所監督的信通技術一致性創新方案( IITP - 2017 - 2017 - 0 - 01015 )的支持。作者在SK電信ICT研發中心支持的SKT -Yonsei全球人才培養計劃下,作為SKT - Yonsei合作自動駕駛研究中心研究項目的一部分進行了這項工作。
-
控制器
+關注
關注
112文章
16433瀏覽量
178944 -
自動駕駛
+關注
關注
784文章
13915瀏覽量
166774 -
cnn
+關注
關注
3文章
353瀏覽量
22281
原文標題:基于CNN閉環反饋的自動駕駛車輛端到端轉向控制器
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA在自動駕駛領域有哪些應用?
為何自動駕駛需要5G?
網聯化自動駕駛的含義及發展方向
CNXMotion將開發制動轉向技術,用于自動駕駛車輛
分享一種基于自動駕駛需求的線控轉向設計方法









 工商網監
工商網監
評論