 張民:人工智能、自然語言和自然語言處理
張民:人工智能、自然語言和自然語言處理
7月28-29日,由中國人工智能學會和深圳市羅湖區人民政府共同主辦,馬上科普承辦的“2018 中國人工智能大會(CCAI 2018)”完美收官。
大會第一天下午,蘇州大學特聘教授、國家杰出青年科學基金獲得者張民作題為《自然語言處理方法與應用》的主題講座。與參會者共同分享自然語言處理方法,以及應用和進展。
以下是根據速記整理的大會講座實錄。
蘇州大學特聘教授、國家杰出青年科學基金獲得者張民
張民:感謝大會的邀請,使我有機會和大家分享自然語言處理方法,以及應用和進展。這也是給了我一個非常大的機會和動力,讓我自己去總結、自己去深度挖掘、去想,做了這么多年,到底什么叫自然語言處理,有什么樣的方法,都是怎樣研究的,進展在哪里。更重要的是,用什么樣的方法能和在座的各位進行交流和溝通。
大家聽了很多次報告,這是其中一次,我在上面講,用自然語言的方式把想講的東西表達出來,大家在下面聽。大家有沒有仔細想過,你是怎樣理解我講的這些話,你學到了什么,你學完之后又采取了哪些動作,對你有哪些影響,這個過程就是一個很典型的自然語言處理過程。
我主要分四部分進行講解。既然是人工智能大會,自然語言處理本身也是人工智能非常重要的分支,我用一點時間給大家介紹一下什么是人工智能、什么是自然語言、什么是自然語言處理。然后再介紹自然語言處理方法、應用,以及在人工智能時代自然語言處理的特點。最后給大家一個結論。
1.
人工智能、自然語言和自然語言處理
人類社會的發展是從農業社會到工業社會,到現在是信息社會。提到信息社會會想到信息爆炸,有各種各樣的名詞出現,比如我們現在處于大數據時代、信息時代,有數字經濟,現在人工智能又這么熱。大家有時是不是很迷惑,到底我們處于什么樣的時代?其實所有這些從數據到信息、到知識、到智能都是信息時代的標志,它們之間到底有什么區別?數據是什么?信息是什么?知識是什么?智能是什么?
數據就是對事實的記錄,對我們所看到的主觀世界或客觀世界事物的數量、屬性、位置及其相互關系的抽象表示,以適合在這個領域中用人工或自然的方式進行保存、傳遞和處理。舉個簡單的例子,深圳今天的室外溫度很熱,37℃,數據是什么?數據就是氣溫,37℃。這就是一個數據,對深圳屬性描述、氣溫、氣壓是多少。僅有數據得不到任何信息,如果我說氣溫-20℃,什么意思?大家不知道。
信息就是在數據基礎上進行加工,能夠傳達你想聽到的和我所講的。你聽到我講的以后,就知道我講的什么意思了。信息是具有時效性的有一定含義的、有邏輯的、經過加工處理的、對決策有價值的數據流,也就是加工后有邏輯的數據。還是用天氣做例子, “2018年7月28日,中午,深圳的天氣是37℃”,這就是一條信息。如果只說溫度37℃,不知道什么意思。
知識是什么?小時候學的數學、化學、物理的定義和證明就是知識,知識就是在信息基礎上進行抽象、凝練、總結、歸納、演繹,使其有價值的部分沉淀下來,可以結構化、傳承、抽象,有價值的信息就轉變成知識。
人工智能
什么叫智能?智能包括兩部分,一部分是智,一部分是能;智就是智慧,能就是能力。用一句話總結,智能就是用知識來解決問題的能力。僅有數據不行,數據什么都不是;只有信息也不行,因為信息實在太豐富了;然后就必須要有知識;但有知識也不行,有知識必須要有能力;把知識運用起來,這時我們就把它叫做智能。這就是知識和智能關系。
現在人工智能已上升到國家發展戰略,科技部、教育部、基金委、工信部和產業、科研機構、大學都在談人工智能。從50年代、60年代、70年代到現在,會發現人工智能熱時,大家喊人類要毀滅,人工智能要替代人類,說你要失業了。如果人工智能不火時,說是騙子,騙了國家、用戶的錢,沒幫助我們解決問題。但是冷靜下來想,目前我們研究人工智能雖然取得了很大的進步,但是從人工智能的科學問題和智能的本質角度還差得很遠。如果拿人的年齡作比喻,人工智能最多是一兩歲。所以,第一,我們不是騙子;第二,人類也不會因為人工智能毀滅,還有很長的路要走。
中國人工智能學會理事長李德毅院士講過一句話,他說,講不清楚的人工智能內涵的人,都是在忽悠。李院士給人工智能下的定義(見圖1),我非常認可。這個定義就是人工智能的內涵,包括腦認知基礎、機器感知與模式識別、自然語言處理與理解和知識工程四部分。腦認知技術是基礎,然后是知識工程。知識工程做什么?要做的就是怎樣去把人類社會的知識用計算機表達出來,怎樣數學化建模。人工智能最終體現兩方面,一個是感知;一個是認知。語音識別和圖像處理屬于典型的感知問題;而自然語言處理和理解,是一個認知的過程。自然語言理解被認為是認知智能的核心難題。人工智能的外延是什么?按照李院士的定義來說,包括兩部分,一個是機器人;一個是智能系統。機器人包括很多,如工業機器人、農業機器人和國防機器人等;智能系統也包括很多,如智能商務、智能制造和智慧金融等,這就是人工智能的外延。
圖1 人工智能的內涵和外延(李德毅院士)
自然語言處理和理解
我們知道對一個智能生物體來講主要包括感知、認知和進化三部分。進化在人工智能領域研究得非常少。圖2示出了人的進化過程,左邊是一只老虎,圖上放了三個術語。第一點,人類經過了億萬年的進化,從食物鏈中端進化到食物鏈的頂端。這里不講人類有沒有控制世界、破壞世界(那是一個哲學問題),只是從生物鏈角度,我們站到食物鏈的頂端,享受人類世界的文明成果,可以作報告,可以談論人工智能問題,可以談論哲學問題,不用擔心被老虎吃掉。但是,如果以人的能力,從一個人的角度來講,肯定打不過老虎(除了武松之外)。第二點,大家都講,腦的容量越大就越聰明。有時候我給女兒講故事,我反問她,大腦容量越大越聰明對不對?她說,爸爸,你的腦容量大還是老虎腦容量大?我沒研究過,估計老虎腦容量比較大(老虎大腦比人腦重約6倍),但是人比老虎聰明。為什么人類能夠進化,處在食物鏈的頂端,和動物唯一的的區別就是有語言。人類通過語言進行溝通、合作,打不過老虎沒關系,在地上挖一個坑,上面放一塊肉,老虎咬那塊肉肯定會掉下去,結果不言而喻。所以,語言非常重要,語言區別于人與動物。
圖2 自然語言與人的進化過程
人工智能最核心的一部分就是自然語言處理和理解。
什么是語言?從計算機角度來講,語言就是一個符號系統。一個符號系統有幾個特點:
第一必須有字母、有詞;
第二,必須有規則;
第三,必須有起始符號;
第四,必須有終止狀態。
這就是語言的基本定義。
語言的種類
(1)動物語言
如果從語言種類來講分為動物語言、人工語言和自然語言三種。動物語言和自然語言有什么區別?動物語言有幾個特點,第一,只有聲音,沒有文字。第二,只有單詞,最多表達20多種狀態,這20多個單詞不可以進行組合,而且動物語言表達狀態都是最基本的、單一的,比如餓了、飽了、敵人來了、遇到危險了。第三,與生俱來的,不是后天學出來的。一只在中國的老虎和一只在美國的老虎從來沒見過,它倆的語言可以交流;不像人,美國人和中國人從沒見過,不可以用語言進行交流的。第四,動物語言和人不一樣,不可以記錄現實,也不可以對現在進行描述,也不能展望未來。從來沒有老虎媽媽和老虎寶寶講,將來怎樣。
(2)人工語言
人工語言和動物語言與自然語言的區別。人工語言是由人創造的。首先人工語言目的是為了溝通;第二是一些非常有情懷的人做人工語言;第三,人工語言不像人類語言可以進行演變。一個代表性的例子就是世界語,由波蘭人柴門霍夫發明的,在上世紀80年代非常流行。隨著全球各國逐漸開放,世界語言不流行了,逐漸被英語取代。
人工語言發明的原因有多種,比如,人類之間交流、溝通使用;著作者愛好;藝術語言、文學作品的溝通……人工語言我比較推崇的,一個是《魔戒》作者創造的。還有就是《失落的帝國》中古代語言的亞特蘭帝斯語。如果看過這部電影,會看到其導演費了很大的精力,請了歷史學家、作家、語言學家坐在一起,為這部電影創造語言。你會發現這些人在講的時候不是亂講,是有規律的,而且可以進行溝通。
(3)自然語言
什么是自然語言?自然語言的定義、起源、種類和分布到底是什么?自然語言的定義非常多,大概有幾十種定義,無論是做語言學的,還是做文學的,你會發現每種定義都是從某個側面對自然語言某些特征的描述,都會有漏洞,都會有它描述不到的地方。到目前為止,還找不到一個大家公認的,一個科學的、能被廣泛接受的自然語言定義。
自然語言的起源有幾種說法。第一個是神授說。不同的宗教,對語言的起源給出不同的定義。比如,基督教認為是耶穌創造的;我國廣西壯族自治區少數民族認為是山神創造的;印度教也有印度教的說法,認為是吠陀創造的。第二個是人創說。既然人講自然語言,自然語言就是人創造出來的。在我國有一個非常標準的定義,即恩格斯說的定義,他說:語言是從勞動中并和勞動中一起產生的。不管理不理解,恩格斯講的都是對的;但是他不是亂講的,為什么說勞動創造語言?恩格斯在講這句話之前先給三個條件:①人類的思維能力要發展到一定的水平;②人類要具備一定的生理條件;③人類社會有了產生語言的必要。滿足這三個條件就可以創造語言,正好勞動滿足三個條件,所以語言就是由勞動創造出來的。
自然語言的種類。目前世界存在語言6 909種,只有2 000多種語言有書面文字,2500種語言瀕危。漢語、西班牙語、英語、阿拉伯語和印度語是世界上使用最多的;英、法、西、葡、荷蘭語是世界上分布最廣的;漢語國際化還不夠。
自然語言處理
自然語言處理就是用計算機來處理人類的自然語言。那么,計算機怎樣才能處理自然語言?都要做什么?
自然語言處理就做三件事情(見圖3),把這三件事情做好了,可以獲諾貝爾獎、圖靈獎。
第一,分析和理解。什么叫分析和理解?就是我在上面講,你聽見了,如果你明白我講什么了,在理解、思考我講的什么,這個過程就是一個分析和理解的過程。
第二,生成和應用。什么叫生成和應用?我講了之后,我們(人與人)進行對話、進行溝通,我講了一句話你聽懂反過來你要回答我,這就是一個互動和生成的過程。自然語言還有很多應用的過程。
第三,一個自然語言處理系統還要做一件事情,就是要有動作。比如對機器人講:“給我倒一杯咖啡”;機器人聽懂了,它說:“好的,主人,我給你倒一杯咖啡”。不要說好的,然后不動,這是不對的。
圖3 自然語言處理系統
總之,自然語言處理方法目前可以概括四個方法:
第一,自然語言處理本身算法和理論。作為一門學科,它有自己的問題、規則和方法,要定義什么叫詞法、句法、語義,以及其相應的分析算法。
第二,更抽象一點,從人工智能和機器學習角度講,包括規則、統計、機器學習的方法和目前比較熱深度學習的方法。再過幾年之后,隨著研究的深入,肯定會出現新方法取代深度學習。對這些方法抽象化,要解決自然語言處理時,要解決表示、推理和學習三個問題。表示什么意思?一個自然語言在計算機里怎樣表達出來,語意、句話、篇章怎么表達。
第三,推理。
第四,學習過程。如圖4所示。

圖4 自然語言處理方法
自然語言分析、理解和生成,嚴格意義上講這是自然語言處理最核心的兩個問題。自然語言處理應用有兩個層面,第一個是自然語言處理本身的直接應用;第二個是自然語言處理在行業的應用。本身的應用很多人都知道,比如問答、對話系統、機器翻譯、自動文摘、機器寫作等,這是自然語言處理本身的應用。自然語言處理在各行各業都可以得到應用,比如搜索、國際交流、教育、醫療、司法、金融,以及在公共安全、國防、旅游等行業應用。以教育為例就有很多,如對小孩的輔導和教學,無論學數學還是學英語,高考機器人等。
自然語言處理的歷史,從廣義理解,一直到秦朝、古希臘時代。真正的自然語言處理在計算機誕生之后,從1950年起就有了。為什么叫做forever?因為語言本身是人類區別于動物的一個標志,是最智能的行為,如果把語言研究透了,就可以解決人工智能一系列問題。這個問題只有人存在,只要對人本身沒有研究透徹,這個問題就可以一直研究下去。
為什么在人工智能時代,自然語言處理這么熱?
第一,技術取得了巨大進步,雖然離真正解決問題還差很遠;
第二,產業落地的巨大需求。
以前我認為,自然語言處理技術沒有成熟到達到產業需求的下限。目前自然語言處理在很多應用上已經達到產業需求的下限。有產業落地,就催生了技術需求,技術達到了產業落地的基本需求,反過來大大推動了技術進步。在人工智能時代,自然語言處理這么熱是大勢所趨。
機器能不能理解人類自然語言?舉一個簡單例子,我買件衣服是紅色的,很高興,所有人對這句話都能理解。但對計算機來說,它翻譯成英文(見圖5),這是今天早上的翻譯結果,我測了很多機器翻譯系統,幾乎沒有一句話對的。但是你問機器,誰是紅色的?機器可能說衣服是紅色的,也可能說我是紅色的;如果問誰高興,機器可能會想到我高興、衣服高興,甚至會想到紅色高興。翻譯成英文的話,省略都要補齊。

圖5 機器翻譯示例1
另外一個例子。一天,小老虎看見一只貓在捉老虎,身手敏捷,羨慕極了。這是《老虎和貓學本領》中的一句話,非常簡單。當給我女兒讀故事書時,怕她不理解,經常問她,爸爸給你讀完這個故事你聽懂了嗎?爸爸講什么?你能講一遍不?她最后都煩了,你為什么老問我這些問題?我說什么叫敏捷?什么叫羨慕?她想了想,不知道,然后她問我。我一想我也不知道,我怎么給小孩解釋什么叫敏捷、什么叫羨慕。于是去Google圖片搜索“敏捷”,有一只老虎跑來跑去;“羨慕”就用表情表達,我女兒就明白差不多了。但是這對機器來說有點“強人所難”。我又問我女兒,既然你和我說你理解了身手敏捷和羨慕極了,我問你,誰身手敏捷,誰羨慕誰?她一看問題比較難就亂講了,一會說老鼠身手敏捷,一會又說貓、又說老虎。如果從機器角度來講,她說的都沒錯。誰羨慕誰都可以?老鼠羨慕貓,我每天被你抓來抓去的,不過我辛辛苦苦偷了這么多東西還要被你吃;老虎羨慕貓,貓羨慕老虎都可以。從人的角度來講沒有任何問題,我們有很多常識,小孩沒有,機器沒有。我舉這個例子不是說自然語言處理太難,機器做不了,我提醒大家不要太樂觀,不要覺得人工智能發展,人類就要毀滅,遠遠達不到這個水平。
第三個例子,籃球放不進箱子里,太大了,太小了,形狀不對。大家肯定知道,第一,籃球太大了,不可能箱子太大。但是問機器,機器就開始亂猜了。第二,太小了,形狀不對,大家都能解決這些問題。但是機器必須要有知識庫、要有推理、要有常識才能解決這個問題。再看機器翻譯的結果,完全沒有對這句話進行理解,“身手敏捷、羨慕極了”,從英文翻譯來看,看不出任何修飾關系(見圖6)。

圖6 機器翻譯示例2
這是被我抽象出來的例子,“我們班就一個女生,班上15個男生都喜歡她。B就問,那你喜歡她嗎?回答說我們班有17位同學”。我到底喜歡還是不喜歡你?從正常角度講是不喜歡的,只是很委婉地不想傷那個女生的自尊心或者不好意思回答。對機器來說不好回答,我女兒也沒理解。我們很多問題隱含在語言、隱含在背后的推理和常識,這些邏輯關系非常抽象。
我們再看最后一個例子,這句話很有意思,這個題目是我女兒給我的。王師傅是賣魚的,每公斤魚進價48元,現38元一斤,顧客買了兩公斤,給了王師傅200元假錢,王師傅沒零錢,于是找了鄰居換了200元。事后鄰居存錢過程中發現錢是假的,被銀行沒收了,王師傅又賠了鄰居200,請問王師傅一共虧了多少?對計算機來說,怎么明白進價、假錢的意思?這么簡單例子,可以看出自然語言處理中常識和知識的重要性。
自然語言處理為什么這么難?下面從功能、知識、特點、語用性等方面闡述(見圖7)。第一,語言是對世界的認識,是對客觀、主觀世界所有能夠看到的東西、想到的東西的描述。第二,自然語言處理主要是基于語言學知識,除了自然語言知識還有外部世界知識、領域知識、常識知識。第三,自然語言組合性、開放性、動態性。還有一個非常重要的特點,是語用性。除了知識之外,對自然語言處理要解決另外一個最重要的問題,就是語言是有特點和環境的,尤其在對話過程中是有上下文、有信息、有意圖的。

圖7 自然語言處理為什么這么難?
2.
自然語言處理方法
學科的內涵和外延
自然語言處理方法到底是什么?首先要定義如圖1所示的學科內涵、外延和邊界。自然語言處理三件事,即分析理解、生成和應用、動作。內涵是分析理解和生成;多語言處理、跨語言和單語言理解有不同特點,我把多語言處理也作為自然語言處理學科內涵,包括對詞法分析、句法分析、語意分析和篇章分析。自然語言生成從內部表示生成自然語言的表達。多語言處理就是語言之間的對齊和轉換。這就是自然語言處理學科內涵問題,也就是“聽得懂、講明白”。學科外延有機器翻譯、文本分類、信息檢索、機器對答等自然語言本身的直接應用和自然語言處理加行業(見圖8)。下面對內涵和外延所要解決的問題,給大家解釋一下。

圖8 自然語言處理的外延(應用)
分詞
第一是分詞,意思是人聽一句話之后理解的是以詞為單位,而不是以句子為單位。計算機要解決第一個問題就是分詞。舉個例子,“嚴守一把手機關了”有非常多歧義,一把手、機關都是詞,這里只有一個正確分詞結果就是“嚴守一/把/手機/關了”。自然語言處理解決第一個問題就是分詞,目前我們把它叫做序列標注方法。
一個圖
B是開始,I是中間,E是結束,S是單個;B又是開始,E又是結束;“關”是單獨,“了”也是單獨。這個字到底是一個詞的開始還是一個詞的中間,還是一個詞的結束,還是這個字本身就是單獨的。這就是目前分詞所用到的數學模型。目前主要包括兩種方法,第一種是基于離散特征的CRF;第二種是神經網絡的方法。
自然語言分詞挑戰有五個。
第一,交叉歧義、分真歧義和偽歧義,如乒乓球拍賣完了,這就是一個真歧義。
第二,新詞不斷涌現。
第三,領域移植問題,如在新聞領域做得非常好,如果放在法律領域、醫療領域就不一樣。
第四,數據融合問題。到底什么是詞?不同人有不同鑒別。現在有各種各樣的語料,分詞標準不同,在理解這些問題時怎么樣進行標注和融合?
第五,粒度不同的問題。
分詞進展包括四個方面。
第一,深度學習方法,使分詞定義有了進一步提高。
第二,網絡文本分詞數據的人工標注,這是由于在互聯網時代,尤其互聯網公司產生了巨大的需求,對網絡文本分詞有了進展。
第三,多源異構數據的融合和利用。第四,多粒度分詞。
如圖9所示,第一個句子“特別是我國經濟下滑”,在CTB,“特別是”做一個詞,如果在PD描述,把“特別是”分開,“我國”也是。第二個是“全國各地醫學界專家走出人民大會堂”,可以看到兩個分詞標準完全不同。統計表明,90%詞一致性都做不到,這是一個很大的問題。還有分詞的粒度問題,不同人對詞語認知不同,包括生活環境、體系不同。還有漢語語素和合成詞的界限很模糊,這也是一個問題。在1996年,Sproat教授一個實驗結果表明,中文的native speaker分詞一致率僅76%。
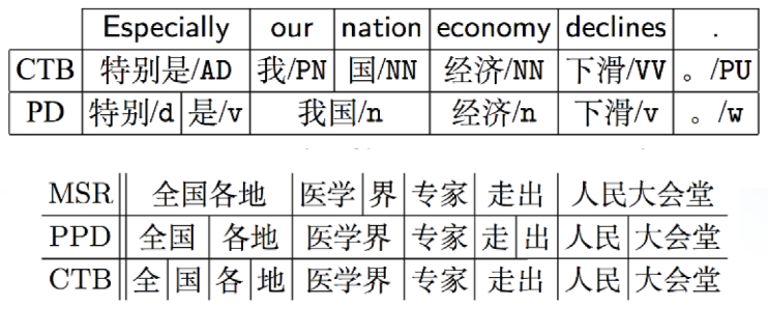
圖9 分詞的粒度
粗粒度分詞和細粒度分詞有不同的需求。以前一個互聯網公司高層人員說,分詞不需要做了,我們每天有這么多數據,每天新詞都能發現,每天分詞結果都很準確。于是讓我的學生給他一些文章,測一下其分詞結果怎樣?結果可想而知。所以分詞的問題從這里可以看出,遠沒有解決。
如何能夠在多源異構數據中學習?我們現在用的分詞系統還是機器協同的系統,有了這么多異構數據,怎樣能夠學出好的分詞模型,這也是目前研究的熱點。多粒度分詞也是這樣,不像最開始講的,把分詞看成線性序列問題,現在把分詞做成一棵樹,樹的任何一個節點都可以看作是一個詞。如圖9所示,如果醫學界在圖中1這個節點,醫學就是一個詞;如果在圖中2這個節點,醫學界就是一個詞。這是目前研究比較有意思的現象,我們叫做多粒度分詞。
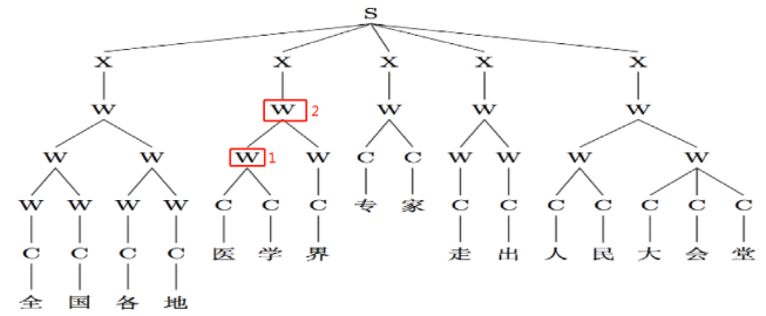
圖10 基于樹結構的多粒度分詞示例
命名實體
在多源數據融合,研究的都是基于模糊標注的耦合序列學習,還有基于樹結構的多粒度分詞。作為自然語言處理要解決第一個問題就是分詞問題,第二個問題就是命名實體識別問題。“周潤發出生香港南丫島,籍貫廣東開平”,這里有很多命名實體(見圖11)。命名實體就是指人名、地名、組織機構名、產品名和時間等;還有很多專有名詞,我們也叫做命名實體。比如,昆蟲的名字在生物學界就是很難解決的問題。據說在英文里,昆蟲的種類大概有幾百萬種,如為每一只昆蟲命名是很難的問題。如圖10所示就出現了非常多的命名實體。

圖11 命名實體示例
要解決第二個問題,怎樣能夠把命名實體識別出來。
命名實體識別方法有兩種:
第一,規則系統;第二,基于機器學習的學習系統。
研究難點包括三個方面:
第一,新領域舊實體類別識別。在新的領域里面,實體沒有變過,但是領域發生變化;第二,新實體新類別,以前沒有這個類別,現在出現新的類別怎么樣定義、發現出來;第三,方法,這是目前研究的熱點和難點。
句法分析
有了分詞、命名實體,下一步要做的就是句法分析。句法分析要研究的問題就是,從結構的角度,這些詞為什么能夠組成一個句子?就是說,在這個句子內部,這些詞到底有什么關系?這里以依存句法分析為例(見圖12)。輸入是一個句子的詞系列,輸出的是依存關系句法樹。這些對應關系我們能夠知道的,或者以前學過的,比如主、謂、賓、定、狀、補。這是目前在學術界或者工業界常用的句法樹庫,第一個是格位語法;第二個是短語結構文法;第三個是依存語法。
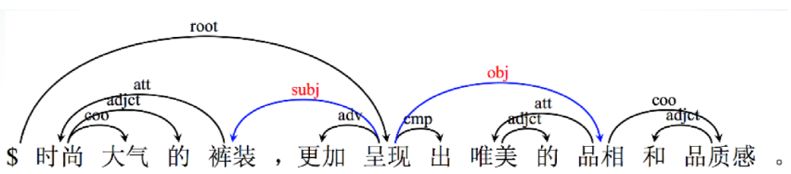
圖12 依存句法分析示例
表1所示的這些句法樹之間,由于不同的人后面有不同的學術背景和認知背景,都是不完全兼容的。
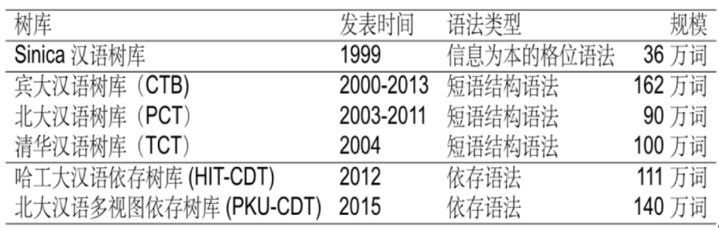
表1句法樹庫
句法分析方法有兩種:
第一,圖的方法;
第二是轉移方法。
從全圖里,怎樣能找到子圖。基于轉移的方法是狀態的轉移,每個狀態代表了N個結構里的公共部分。狀態的方法叫做移進規約的方法。這是句法分析的性能,從圖13可以看到性能進步非常快,尤其在2016和2017年。2016年Google提出了基于深度學習的轉移句法分析方法,2017年斯坦福提出了基于深度學習的圖分析方法, 所以目前有近10%的性能進步。英文比中文性能高8%~10%;英文句法分析如果在學術界里標準測試題達到90%~95%,中文86%的水平。
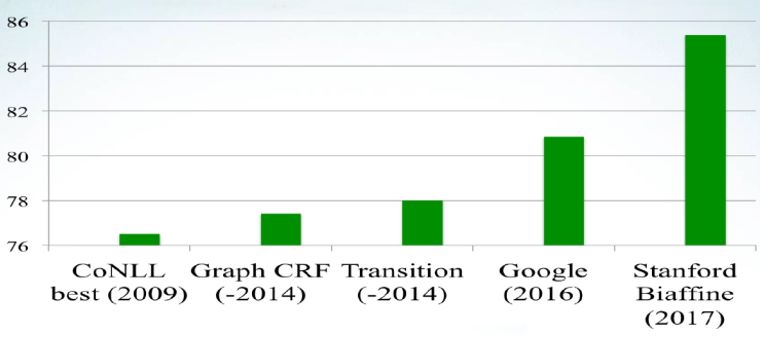
圖13 句法分析性能
句法分析的難點有兩個:
第一,處理網絡文本時準確率急劇下降5%~10%,我們和企業合作時也發現了這個問題。不僅句法分析有這個問題,同樣分詞也有這樣的問題,分詞可以下降到20%。
第二,語義知識和外部知識的利用。
研究熱點包括兩部分:
第一,資源構建,局部標注的主動學習和樹庫轉換。樹庫標準、規范不一樣,而且要在企業標新的樹庫出來,怎樣把樹庫轉換成標準格式,從而能充分利用起來?
第二,知識驅動的句法分析。
到目前為止分享了分詞、命名實體,還有句法分析。下一步進入語義分析,輸入是自然語言的句子,輸出是自然語言句子含義的結構化和機器可讀的表示。語義不像句法,句法有標準的表達形式,在語義層面還沒有形成一個大家公認的、可計算的、深層次的、能夠在計算機里面可用的,在學術界得到充分認可的表達。不同的應用語義表達方法也不一樣,分析方法也不一樣。
語義表達有三種:
第一,淺層語義分析,回答誰做了什么,什么時候做的,為什么這么做,怎么做的。
第二,邏輯語義分析,是基于邏輯表達式的分析。
第三,抽象語義表示是南加州大學提出的ARM。
方法分三種:
第一,基于同步上下文無關文法。
第二,基于組合范疇語法。
第三,在上述兩種方法加了神經網絡的,基于神經網絡序列到序列方法。
語義分析性能以ARM為例子,1-10個詞率達到75%,這是稍微簡單一點的;如果句子長一些,30、40、50個詞,性能則急劇下降。這是目前語義分析的性能現狀。
篇章分析
到目前為止我們討論了分詞、實體、句法、語義,下面看一下篇章的分析。篇章是什么?“比爾來自美國,今天交通非常擁擠。長江貫穿中國多個省市。因此,自然語言處理是計算機科學與語言學的融合。”讀完這句話以后,發現每句話都沒錯,拿出其中任何一句話都覺得是有意義的,但是放在一起,覺得這個人語無倫次了,邏輯有問題。第二句話,“這里交通非常擁擠,張先生早上6:40之前就得出發。常常會提前半個小時到辦公室;如果稍晚一點,他很可能會遲到。”同樣一句話,第一句話比第二句話講得還冠冕堂皇,好像文風更好,但是第一句話表達不出任何意思,第二句話就表達了完整的意義。篇章是做什么?為什么三個句子、四個句能夠按照一定順序講,為什么不顛倒過來?這些句子到底有什么關系?篇章就是解決這些問題的。人在理解自然語言時是以篇章為單位,不能斷章取義就是這個意思。
這是學術界老前輩宋柔老先生的例子,《圍城》里有一句話:“高松年發奮辦公,夙夜匪懈,精明得真是睡覺還睜著眼睛,戴著眼睛,做夢都不含糊的。搖籃也挑選得很好,在平成縣鄉下一個本地財主家的花園里,面溪背山。” 一個逗號到底,中間有一個句號。讀完雖然有點繞口,基本上能明白它意思。但是這些句子和句子的關系非常復雜,它們到底有什么關系?“帶著眼鏡和睜著眼睛”之間有并列關系,從計算機角度一定要明確;“做夢都不含糊”,做夢和睡覺也是并列關系。。
看另外一個例子。“如果你不出面干預,他即使把設備賣了,也沒人組織得了他。”這里隱含什么關系?轉折關系、因果關系或者假設關系。這些關系如果分析不清楚,自然語言處理應用,比如理解、問答、對話都做不了。
篇章分析到底要做什么?其實就是要解決兩個問題,一個是篇章結構;還有一個是篇章特征。篇章結構包括剛才看到的邏輯語義結構、話題結構、指代結構、功能結構和事件結構等。除了功能結構之外,其他幾個結構目前在自然語言處理都有所研究(都是非常難的問題)。篇章的基本特征包括銜接性、連貫性、意圖性、可接受性、信息性、情景性和跨篇章性七個,目前學術界研究最多的還是銜接性和連貫性。銜接性指的是你在一段話或在一篇文章里講這個詞時,主題基本上都會用一個詞、用同樣的詞,不會跳來跳去,不會發生很大變化,這就叫做詞匯鏈的概念。連貫性指的是結構。
篇章分析語言學理論有中心理論、脈絡理論、篇章表示理論等,我們統稱叫做修辭結構理論(RST)。RST對從事計算機語言的人影響非常大。目前最大的中英文篇章標注樹庫基本上都是基于RST,在它的基礎上進行小幅度改進所標注。這些篇章分析的庫,我們叫做篇章樹庫。
篇章分析的目標就是分析篇章所蘊含的各種結構,以及構成單元之間的各種語義關系。其任務:
第一,識別篇章基本單元;
第二,識別這些單元之間的篇章關系。
篇章分析有三種方法:
第一種是線性;
第二種是組塊方法;
第三種是樹結構方法。
篇章里一直在講修辭結構,到底有什么用?
第一個修辭結構。“張三才30出頭,既沒有什么學歷,又沒有多少新的工作經驗,但是不論干什么,他都非常認真,所以處長總是把一些重要的任務交給他。”這句話跳來跳去。問的問題是,為什么處長總把一些重要任務交給他?如果篇章分析做不好,這個問題沒法回答,只有在篇章分析基礎上,我們回答,最終原因是,他不論干什么,都非常認真,所以處長才把任務交給他。
第二個話題結構。“我昨天上街看見一個人,長得很魁梧,穿著軍大衣,買了兩斤肉。”這句話比較通俗。問題是誰買了兩斤肉?無外乎就是兩個答案,一個是我;一個是看見的那個人。如果篇章分析不出來,完全給不出答案,所以篇章非常重要。
自然語言生成
分詞、命名實體為代表的詞法、句法、語義、篇章這是分析和理解層次,它們是自然語言處理或者自然語言理解必須要解決、要做的事情,這是最核心的科學問題;此外還有生成。
自然語言生成和分析比起來,研究差得很多。
造成這種情況的原因無外乎兩點:
第一,生成是基于分析的,如果分析做不好,生成也很難做好;
第二,以前產業界對生成沒有很大的需求,尤其是近三年或者近五年,隨著人機對話、問答,對生成的要求越來越高。
2000—2005年在國際會議上舉辦一個自然語言生成的比賽沒有人參加,但現在自然語言生成變得尤其重要。一個系統要做人機交互,要把自己的想法用自然語言表達出來,表達得好壞直接決定用戶體驗,生成就變得非常有用。自然語言生成有基于規則方法、基于知識庫檢索方法和基于深度學習的方法。
到此為止,對自然語言處理方法介紹了詞法、句法、語義和篇章,在生成這個層次介紹了生成的所采用的不同的方法。
3.
自然語言處理應用
自然語言處理應用包括兩方面,第一方面是自然語言處理本身應用;第二方面是自然語言處理+行業。下面介紹幾個代表性的自然語言處理應用。
情緒和情感分析
情感和情緒不同。
情感分析主要對產品評論和新聞文本表達的意見、情感、情緒、主客觀性、評價等方面的研究。情感分析在工業界和學術界已經有著廣泛的應用,比如輿情監測,我國做得非常好;還有企業征信、聊天服務機器人等做得也好。情感包括正面、負面和中性三個方面。如圖14所示,“這部電影情節還不錯,我很喜歡,但是這家影院的3D效果太爛,以后不會再來了。”如果在句子層面,這個層面是正面;句子二是負面;既有正面也有負面,綜合評價是負面,他不會再來。

圖14 情感分析示例
情感非常重要。學術界一般做情感分析都是做一個句子或者一篇文章,在我們和某電商公司合作之后,發現了很多在學術界所看不到的問題。在電商領域有很多用戶,用戶和用戶之間、用戶和客服之間進行交流,產生了很多新的科學問題和應用場景,比如基于問答的情感分析,以及基于單產品、單一問答多用戶的情感分析。這些問題都是在實際中電商公司必須解決的,都是學術界沒有意識到的問題,沒有數據,沒有要求,也沒有科學問題的驅動,但是企業界有這樣需求,一歸納就發現了很多的科學問題和實際應用。
情緒就是喜怒哀驚,難過、新奇、憤怒等。比如,“今天學發了國家獎學金太開心了。明天就去買個LV包包。”這個情緒第一個是太開心;,第二個產生的結果就是買個LV包包,這就是情緒分析。模型從機器角度來講,各個方法都有。問題驅動是做自然語言處理更感興趣的,那就是情感和情緒分析到底要哪些解決問題。然后分析完之后又挨個做一遍。
問答系統
自然語言處理應用,第一個就是情感和情緒;第二個是問答。問答也非常有意思,問答輸入自然語言句子,輸出是精準答案。但是很多情況下給不出一個精準答案,很多答案是主觀的,或者很多答案你認為正確,但是不敢說、不能說。問答任務分為社區問答、基于知識的問答、垂直領域問答、開放領域問答、閱讀理解等。
問答的分類也有很多種。事實類,2018中國人工智能大會在哪里召開?深圳。描述性問答,這款新發布的手機有什么特點?過程性問答,護照怎么申請辦理?需要計算的問答,飛巴黎和飛洛杉磯最短的時間差多少?這相對難一些,要找到飛巴黎和飛洛杉磯的時間,然后互相減掉。很多小學應用題里蘊含很多對自然語言處理很難,以及很多推理、常識性又是可計算性的東西。推理因果關系,為什么中國會發生疫苗事件?這個答案不唯一,政府發言人是一個,敵對勢力是一個,受害小孩家長也是一個,憤青是一個。觀點性問答,你對疫苗事件和中美貿易戰有何看法?二者有關系嗎?如果讓小冰回答,小冰估計會說“跟我沒關系,我不告訴你”,這也是一種回答。
問答分類分析和理解分為一階和二階,一階比較簡單,比如喜馬拉雅山有多高?二階問答,比如《紅樓夢》作者還寫過哪些書?還有更復雜的,經常用的例子,謝霆峰前妻的什么之類,繞了很多圈最后又繞到謝霆峰這里,推理得非常翔實。這也是一階、二階邏輯。第二就是要做好問題分類、分析和理解,要做好答案的匹配和檢索。第三個是答案生成。要看問題是什么,歸歸類,作者意圖是什么。答案匹配和檢索,既然把問題分好了,總要找到答案,無論是知識庫、社區還是互聯網要匹配和檢索出來。答案生成可能涉及到推理、涉及到知識圖譜、組合、指代等很多東西,一個問答系統需要做好這三個模塊。
問答發展歷史和人工智能歷史是一樣的。現在測試人工智能要進行圖靈測試,這就是一個問答系統;后面有TREC、IBM沃森、社區問答、看圖說話等。
問答有四個難點:
第一,多源異構大數據背景下開放域問答瓶頸;
第二,語義理解問題;
第三,知識庫與知識圖譜問題;
第四,多模態場景下的問答(就是常說的看圖說話)。
研究方法:
第一,針對多源異構大數據以前用IR方法,目前就是IR+閱讀理解的方法。
第二,深度理解主要抽取的方法,現在抽取+生成的方法。生成是問答非常重要的一環,目前生成式問答已經成為主流。
第三,知識圖譜以后專門介紹。
第四,多模態場景下的問答,最有趣的地方是要把語言學用的模型和圖像處理模型在一個框架下統一起來;也就是說,要跨媒體、跨模態的特征共享、獨立和抗依賴。
問答系統有什么樣的應用?圖15是在網上找到人工智能行業圖譜,發現每個領域只要涉及人機交互都可以用到問答。
圖15 人工智能行業圖譜
對話系統
對話系統不像問答系統這么單純,一個是開放域對話系統;一個是封閉域對話系統,或者面向任務驅動的對話系統。比如銀行、客服、旅游就是封閉域對話系統。開放就是隨便問、隨便答。開放域對話系統分兩種,一種是閑聊;一種是解決問題。對話系統是綜合性問題,主要涉及語言識別、語言理解、狀態跟蹤、自然語言生成和語音合成。
知識圖譜
圖16所示的是我們和某電商公司做的一個計劃,叫做藏經閣計劃,是在國內幾所科研機構、大學在某電商公司支持下共同打造的。
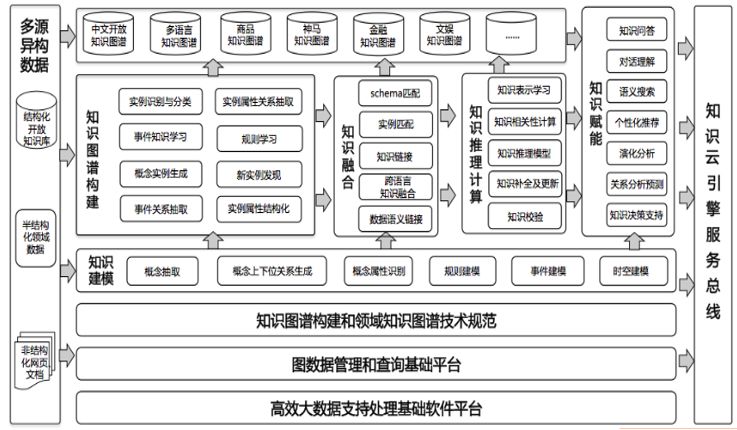
圖16 藏經閣計劃(知識圖譜)
第一個圖譜知識建模,就是人工智能內涵里很重要的部分知識工程。知識工程一個非常核心的部分叫做知識建模。如果問你,什么叫知識?大家回答不出來。經常說,你有知識沒文化;有知識沒能力,你是一個書呆子。知識建模就是要解決這些問題。我們每天都在講這些東西,怎么能用計算機表達出來?是用圖的表達還是用樹的表達?屬性是什么?這就是知識建模。有了建模之后,要進行圖譜的構建。圖譜包括很多,目前先講的都是實體之間的關系,再講實體的屬性。圖譜非常多,不僅有屬性。比如,某搜索公司做用戶意圖圖譜,某電商公司做用戶購買力圖譜,還可以做事件圖譜。有了知識建模,有了知識圖譜構建之外,下面要做的就是知識的融合。有各種各樣的圖譜,有各種各樣的知識;化學第一章學的是有機化學,下一章是無機化學,怎么樣把知識融合起來?這就是知識融合解決的問題。還有知識推理和計算。有了知識和圖譜這些靜態的東西,如果利用起來,必須要有推理、要有計算的過程;有了推理和計算之后要賦能,人很會造詞。以前對賦能這個詞很反感,聽時間長了,慢慢也接受了。因為英文不是你的母語,沒有文化認同感,沒有主人感,如果有一個新詞就會很容易接受;但是中文出了一個新詞,會思考這樣有沒有道理。
信息抽取
信息抽取做了幾件事情,第一,命名實體;第二個叫做mention,是指代的意思;還有關系,比如北大和清華有什么關系;還有事件的關系,比如講破案過程,肯定是先發生案件,然后被人發現了,警察去了開始搜集線索,最后破案了,這就是事件的關系。
舉個例子,什么叫信息抽取?圖17所示的這段話很長,看起來是不是很費力氣?如果用圖18所示的表格表示則非常簡單,一看就明白了。信息抽取要做什么?信息抽取基本的任務就是要把那段話變成這種結構化的表達;也就是說,信息抽取就是要把非結構化數據、自然語言數據變成結構化數據,或者非結構化、或者半結構化數據變成結構化數據。

圖17 非結構化數據

圖18 結構化數據 (信息抽取的結果)
機器翻譯
機器翻譯有基于詞典的方法、基于規則轉換的方法、基于中間語言的方法、基于實例的方法、基于統計的方法和基于神經網絡的方法。舉個例子看看機器怎樣做機器翻譯(見圖19),輸入是“我們必須與友邦建立一種關系”。這個短語可以隨便劃分,我們必須與友邦建立關系。第二步是做短語翻譯,第一步先做短語切分,再做短語的翻譯;第三步做短語的轉化,翻譯結果就出來了。這是短語結構的機器翻譯,非常簡單。
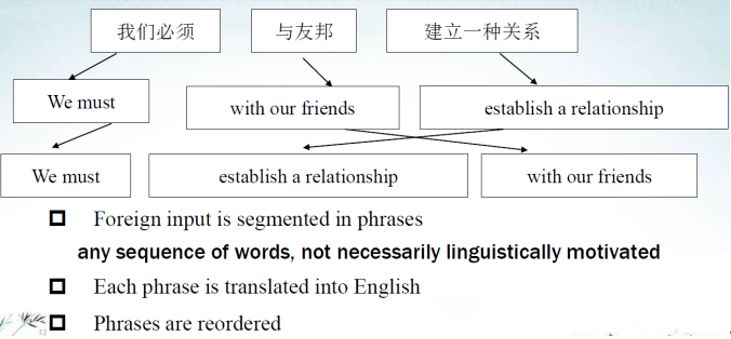
圖19 短語結構的機器翻譯
目前用的神經網絡方法也非常簡單(圖20)。首先把句子進行切分,然后從左向右掃描一遍,再從右向左掃描一遍,掃描過程用的循環神經網絡。掃描后這個句子形成一個向量,有了向量就產生了目標源的詞,從左向右一個個產生。產生詞時要用到兩個條件,一個是狀態序列;另一個就是當前詞和源語言每個詞的attention。神經網絡方法比短語方法更簡單,先是從左向右,然后是從右向左兩邊掃描,這是編碼過程;然后是從左向右解碼。
圖20 神經網絡方法的機器翻譯
目前最新進展是Google提出的Transformer方法,在大規模語料上比之前SMT提高了10個點。Transformer只需要一個叫做attention的東西,第一詞本身;第二詞的位置;第三個是詞與詞之間的attention進行編碼。
機器翻譯的挑戰:第一是知識建模和翻譯引擎,從句法到語義到知識,沒有知識就沒有智能。第二,廣度和深度,廣度就是篇章,深度就是深度學習。第三,面向產業化需求,滿足國家重大需求。
上面講了自然語言處理方法和自然語言處理應用,最后的自然語言處理+行業,從目前的發展來看,自然語言處理在各行各業有非常大的需求。
4.
AI時代自然語言處理
AI時代自然語言處理有什么特點?第一非常熱;第二取得巨大進步。技術進步和產業需求推動了行業的發展。特點包括表示、搜索、推理和學習三個方面。學習有各種各樣的學習方法,多任務學習、對抗學習、遷移學習等,這些都是自然語言處理發生的新框架(見圖21)。
圖21 AI時代自然語言處理的特點
最后簡單介紹蘇州大學的自然語言處理。我們目前有200多人的自然語言處理團隊,做了30年的自然語言處理研究,前面講的東西,在我們蘇州大學自然語言處理實驗室都在做(見圖22)。
圖22 蘇州大學自然語言處理的研究
5.
總結
第一,自然語言處理發展正處于歷史的最好時期,并取得了很大進步。最重要的原因是技術的進步達到了產業需求的下限,產業的巨大需求反過來推動了技術的進步。
第二,AI時代自然語言處理發展趨勢,一個是知識;一個是學習。
第三,學科自身發展和邊界,要凝練自然語言處理本身的科學問題,研究框架和規范。
第四,加快產學研的進一步融合。
-
人工智能
+關注
關注
1800文章
48083瀏覽量
242164 -
自然語言
+關注
關注
1文章
291瀏覽量
13453
原文標題:CCAI2018演講實錄丨張民:自然語言處理方法與應用
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學會】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
python自然語言
【推薦體驗】騰訊云自然語言處理
什么是人工智能、機器學習、深度學習和自然語言處理?
什么是自然語言處理_自然語言處理常用方法舉例說明






 工商網監
工商網監
評論