


編者按:關于NLP領域的遷移學習我們已經介紹過了,fast.ai也有很多相應的討論。今天給大家展示一個在亞馬遜評論數據集上實現的任務,即將評論分為積極或消極兩類。
什么是遷移學習?
得益于遷移學習,計算機視覺領域的發展非常迅速。有著幾百萬個參數的高度非線性模型通常需要大型數據集的訓練,經過幾天甚至幾周的訓練,也只能分辨貓狗。
有了ImageNet挑戰賽后,每年各種隊伍都會設計出不同的圖像分類器。我們發現這類模型的隱藏層可以捕捉圖像的通用特征(例如線條、形式、風格等)。于是,這樣就不用每次都為新的任務重建模型了。
以VGG-16模型為例:
它的結構相對復雜,圖層較多,同時參數也很多。論文作者稱需要用四個GPU訓練三周。
而遷移學習的理念是,由于中間的圖層是學習圖像一般特征的,所以我們可以將其用作一個大型“特征生成器”!我們可以先下載一個預訓練模型(在ImageNet任務上訓練了好幾周),刪去網絡的最后一層(全連接層),根據我們的任務進行調整,最后只訓練我們的分類器圖層。由于使用的數據可能和之前訓練的模型所用數據不同,我們也可以花點時間訓練所有圖層。
由于只在最后一層進行訓練,遷移學習會用到更少的標記數據。對數據進行標注非常費時,所以創建不需要大量數據的高質量模型就非常受歡迎了。
NLP中的遷移學習
說實話,遷移學習在自然語言處理中的發展并不像在機器視覺里那樣受重視。讓機器學習線條、圓圈、方塊,然后再用于分析還是比較容易設計的。但是用來處理文本數據似乎不那么容易。
最初用來處理NLP中的遷移學習問題的是詞嵌入模型(常見的是word2vec和GloVe),這些詞嵌入表示利用詞語所在的語境來用向量表示它們,所以相似的詞語有相似的詞語表示。
然而,詞嵌入只能表示大多數NLP模型的第一個圖層,之后我們仍需要從零開始訓練所有的RNN/CNN等圖層。
對語言模型進行微調
今年年初,Jeremy Howard和Sebastian Ruder提出了ULMFiT模型,這也是對NLP領域遷移學習的深入嘗試。具體可參考論智此前報道的:《用遷移學習創造的通用語言模型ULMFiT,達到了文本分類的最佳水平》。
他們所研究的問題基于語言模型。語言模型是能夠基于已知單詞預測下一個單詞的模型(例如手機上的智能拼寫)。就像圖像分類器一樣,如果NLP模型能準確預測下一個單詞,那就可以認為該模型學了很多自然語言組合的規則了。這一模型可以作為初始化,能夠針對不同任務進行訓練。
ULMFiT提出要在大型語料上訓練語言模型(例如維基百科),然后創建分類器。由于你的文本數據可能和維基百科的語言風格不同,你就需要對參數進行微調,把這些差異考慮進去。然后,我們會在語言模型的頂層添加一個分類圖層,并且只訓練這個圖層!論文建議逐漸解鎖各個圖層進行訓練。
ULMFiT論文中的收獲
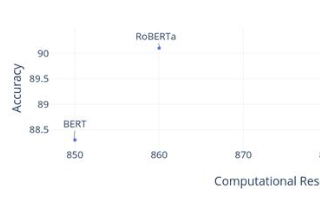
這篇論文最讓人驚喜之處就是用非常少的標記數據訓練分類器。雖然未經標記過的數據隨處可見,但是標記過的數據獲取的成本是很高的。下面是對IMDb進行情感分析之后的結果:
只用了100個案例,他們就達到了和用2萬個案例訓練出的模型同樣的錯誤率水平。除此之外,他們還提供了對模型進行預訓練的代碼,因為維基百科有多種語言,這使得我們能快速地進行語言轉換。除英語之外,其他語種并沒有很多經過標記的公開數據集,所以你可以在語言模型上對自己的數據進行微調。
處理亞馬遜評論
為了加深對這種方法的理解,我們在另一個公開數據集上試了試。在Kaggle上發現了這個“亞馬遜評論情感分析數據集”(地址:www.kaggle.com/bittlingmayer/amazonreviews/home)。它含有400萬條商品評論已經相關的情感標簽(積極或消極)。我們用fast.ai提出的ULMFiT對亞馬遜的評價進行分類。我們發現,僅用1000個案例,模型就達到了在全部數據上訓練的FastText模型的表現成果。而用100個案例進行訓練,模型也能表現出不錯的性能。
如果你想復現這個實驗,可以參考notebook:github.com/feedly/ml-demos/blob/master/source/TransferLearningNLP.ipynb,在微調和分類過程中有一個GPU還是很高效的。
NLP中非監督 vs 監督學習
在使用ULMFiT的過程中,我們用到了非監督和監督學習兩種方法。訓練一個非監督式語言模型很“便宜”,因為你可以從網上找到很多文本數據。但是,監督式模型的成本就很高了,因為需要標記數據。
雖然語言模型可以捕捉到很多有關自然語言組織的信息,但是仍不能確定模型能否捕捉到文本的含義,即它們能否了解說話者想傳達的信息。
Emily Bender在推特上曾提出了一個有趣的“泰語實驗”:“假設給你所有泰語書籍,沒有譯文。假如你一點都不懂泰語,你永遠不會從中學會什么。”
所以,我們認為語言模型更多的是學習語法規則,而不是含義。而語言模型能做的不僅僅是預測在語法規則上相近的句子。例如“I ate this computer”和“I hate this computer”兩句話結構相同,但是一個良好的模型應該會將后者看作是“更正確”的句子。所以我們可以將語言模型看作是學習自然語言句子的架構的工具,從而幫助我們了解句子含義。
想了解更多這方面的話題,可以觀看ACL 2018上Yejin Choi的演講:sites.google.com/site/repl4nlp2018/home?authuser=0
NLP遷移學習的未來
ULMFiT的出現推動了遷移學習在自然語言處理中的發展,同時也出現了其他的微調工具,例如FineTune Transformer LM。我們注意到隨著更多更好地語言模型的出現,遷移的效率也在不斷提高。
-
計算機視覺
+關注
關注
9文章
1709瀏覽量
46825 -
nlp
+關注
關注
1文章
490瀏覽量
22644 -
遷移學習
+關注
關注
0文章
74瀏覽量
5740
原文標題:僅訓練了1000個樣本,我完成了400萬條評論分類
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
遷移學習的原理,基于Keras實現遷移學習

什么是遷移學習?遷移學習的實現方法與工具分析
遷移學習與模型預訓練:何去何從
NLP遷移學習面臨的問題和解決
機器學習方法遷移學習的發展和研究資料說明

基于脈沖神經網絡的遷移學習算法
基于遷移深度學習的雷達信號分選識別
遷移學習Finetune的四種類型招式
NLP中的遷移學習:利用預訓練模型進行文本分類
一文詳解遷移學習
視覺深度學習遷移學習訓練框架Torchvision介紹






 工商網監
工商網監

評論