


1、原理
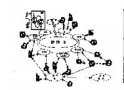
PNN,全稱為Product-based Neural Network,認為在embedding輸入到MLP之后學習的交叉特征表達并不充分,提出了一種product layer的思想,既基于乘法的運算來體現體征交叉的DNN網絡結構,如下圖:
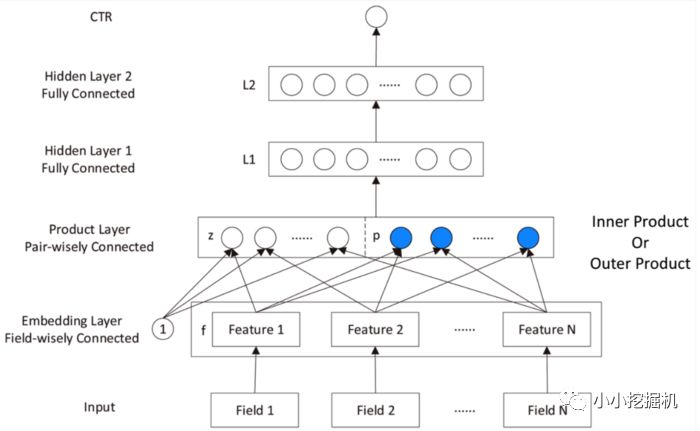
按照論文的思路,我們也從上往下來看這個網絡結構:
輸出層輸出層很簡單,將上一層的網絡輸出通過一個全鏈接層,經過sigmoid函數轉換后映射到(0,1)的區間中,得到我們的點擊率的預測值:
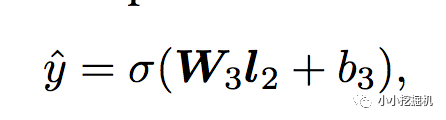
l2層根據l1層的輸出,經一個全鏈接層 ,并使用relu進行激活,得到我們l2的輸出結果:
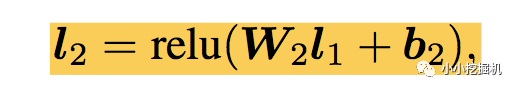
l1層l1層的輸出由如下的公式計算:
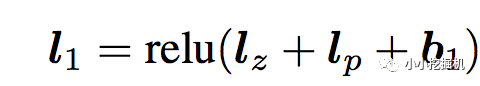
重點馬上就要來了,我們可以看到在得到l1層輸出時,我們輸入了三部分,分別是lz,lp 和 b1,b1是我們的偏置項,這里可以先不管。lz和lp的計算就是PNN的精華所在了。我們慢慢道來
Product Layer
product思想來源于,在ctr預估中,認為特征之間的關系更多是一種and“且”的關系,而非add"加”的關系。例如,性別為男且喜歡游戲的人群,比起性別男和喜歡游戲的人群,前者的組合比后者更能體現特征交叉的意義。
product layer可以分成兩個部分,一部分是線性部分lz,一部分是非線性部分lp。二者的形式如下:
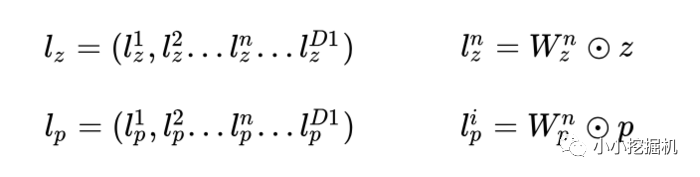
在這里,我們要使用到論文中所定義的一種運算方式,其實就是矩陣的點乘啦:
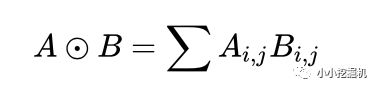
我們先繼續介紹網絡結構,有關Product Layer的更詳細的介紹,我們在下一章中介紹。
Embedding Layer
Embedding Layer跟DeepFM中相同,將每一個field的特征轉換成同樣長度的向量,這里用f來表示。
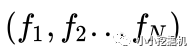
損失函數使用和邏輯回歸同樣的損失函數,如下:
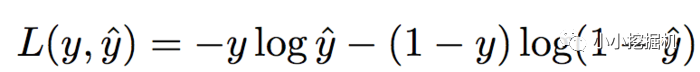
2、Product Layer詳細介紹
前面提到了,product layer可以分成兩個部分,一部分是線性部分lz,一部分是非線性部分lp。
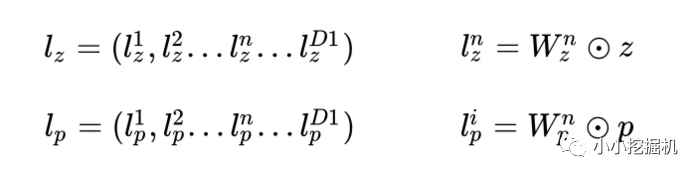
看上面的公式,我們首先需要知道z和p,這都是由我們的embedding層得到的,其中z是線性信號向量,因此我們直接用embedding層得到:
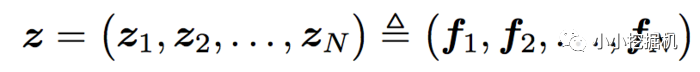
論文中使用的等號加一個三角形,其實就是相等的意思,你可以認為z就是embedding層的復制。
對于p來說,這里需要一個公式進行映射:
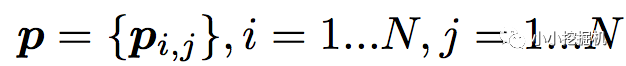
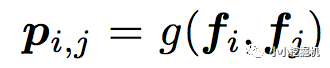
不同的g的選擇使得我們有了兩種PNN的計算方法,一種叫做Inner PNN,簡稱IPNN,一種叫做Outer PNN,簡稱OPNN。
接下來,我們分別來具體介紹這兩種形式的PNN模型,由于涉及到復雜度的分析,所以我們這里先定義Embedding的大小為M,field的大小為N,而lz和lp的長度為D1。
2.1 IPNN
IPNN的示意圖如下:
IPNN中p的計算方式如下,即使用內積來代表pij:
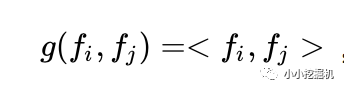
所以,pij其實是一個數,得到一個pij的時間復雜度為M,p的大小為N*N,因此計算得到p的時間復雜度為N*N*M。而再由p得到lp的時間復雜度是N*N*D1。因此 對于IPNN來說,總的時間復雜度為N*N(D1+M)。文章對這一結構進行了優化,可以看到,我們的p是一個對稱矩陣,因此我們的權重也可以是一個對稱矩陣,對稱矩陣就可以進行如下的分解:
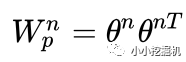
因此:
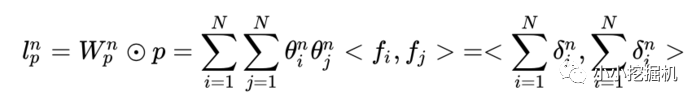
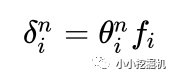
因此:
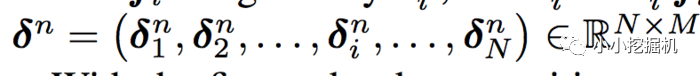
從而得到:
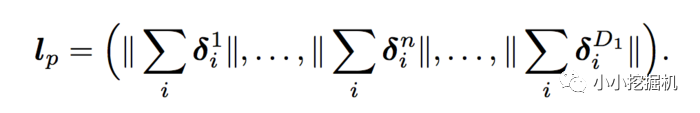
可以看到,我們的權重只需要D1 * N就可以了,時間復雜度也變為了D1*M*N。
2.2 OPNN
OPNN的示意圖如下:
OPNN中p的計算方式如下:
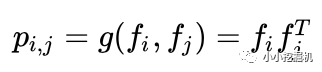
此時pij為M*M的矩陣,計算一個pij的時間復雜度為M*M,而p是N*N*M*M的矩陣,因此計算p的事件復雜度為N*N*M*M。從而計算lp的時間復雜度變為D1 * N*N*M*M。這個顯然代價很高的。為了減少負責度,論文使用了疊加的思想,它重新定義了p矩陣:
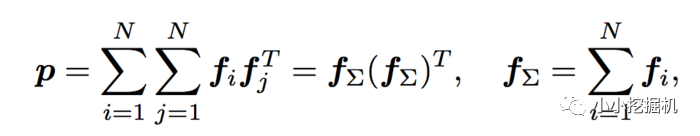
這里計算p的時間復雜度變為了D1*M*(M+N)
3、代碼實戰
終于到了激動人心的代碼實戰環節了,一直想找一個實現比較好的代碼,找來找去tensorflow沒有什么合適的,倒是pytorch有一個不錯的。沒辦法,只能自己來實現啦,因此本文的代碼嚴格根據論文得到,有不對的的地方或者改進之處還望大家多多指正。
本文的github地址為:https://github.com/princewen/tensorflow_practice/tree/master/Basic-PNN-Demo.
本文的代碼根據之前DeepFM的代碼進行改進,我們只介紹模型的實現部分,其他數據處理的細節大家可以參考我的github上的代碼.
模型輸入
模型的輸入主要有下面幾個部分:
self.feat_index = tf.placeholder(tf.int32, shape=[None,None], name='feat_index')self.feat_value = tf.placeholder(tf.float32, shape=[None,None], name='feat_value')self.label = tf.placeholder(tf.float32,shape=[None,1],name='label')self.dropout_keep_deep = tf.placeholder(tf.float32,shape=[None],name='dropout_deep_deep')
feat_index是特征的一個序號,主要用于通過embedding_lookup選擇我們的embedding。feat_value是對應的特征值,如果是離散特征的話,就是1,如果不是離散特征的話,就保留原來的特征值。label是實際值。還定義了dropout來防止過擬合。
權重構建
權重由四部分構成,首先是embedding層的權重,然后是product層的權重,有線性信號權重,還有平方信號權重,根據IPNN和OPNN分別定義。最后是Deep Layer各層的權重以及輸出層的權重。
對線性信號權重來說,大小為D1 * N * M對平方信號權重來說,IPNN 的大小為D1 * N,OPNN為D1 * M * M。
def _initialize_weights(self): weights = dict() #embeddings weights['feature_embeddings'] = tf.Variable( tf.random_normal([self.feature_size,self.embedding_size],0.0,0.01), name='feature_embeddings') weights['feature_bias'] = tf.Variable(tf.random_normal([self.feature_size,1],0.0,1.0),name='feature_bias') #Product Layers ifself.use_inner: weights['product-quadratic-inner'] = tf.Variable(tf.random_normal([self.deep_init_size,self.field_size],0.0,0.01)) else: weights['product-quadratic-outer'] = tf.Variable( tf.random_normal([self.deep_init_size, self.embedding_size,self.embedding_size], 0.0, 0.01)) weights['product-linear'] = tf.Variable(tf.random_normal([self.deep_init_size,self.field_size,self.embedding_size],0.0,0.01)) weights['product-bias'] = tf.Variable(tf.random_normal([self.deep_init_size,],0,0,1.0)) #deep layers num_layer = len(self.deep_layers) input_size = self.deep_init_size glorot = np.sqrt(2.0/(input_size + self.deep_layers[0])) weights['layer_0'] = tf.Variable( np.random.normal(loc=0,scale=glorot,size=(input_size,self.deep_layers[0])),dtype=np.float32 ) weights['bias_0'] = tf.Variable( np.random.normal(loc=0,scale=glorot,size=(1,self.deep_layers[0])),dtype=np.float32 ) for i in range(1,num_layer): glorot = np.sqrt(2.0 / (self.deep_layers[i - 1] + self.deep_layers[i])) weights["layer_%d" % i] = tf.Variable( np.random.normal(loc=0, scale=glorot, size=(self.deep_layers[i - 1], self.deep_layers[i])), dtype=np.float32) # layers[i-1] * layers[i] weights["bias_%d" % i] = tf.Variable( np.random.normal(loc=0, scale=glorot, size=(1, self.deep_layers[i])), dtype=np.float32) # 1 * layer[i] glorot = np.sqrt(2.0/(input_size + 1)) weights['output'] = tf.Variable(np.random.normal(loc=0,scale=glorot,size=(self.deep_layers[-1],1)),dtype=np.float32) weights['output_bias'] = tf.Variable(tf.constant(0.01),dtype=np.float32) return weights
Embedding Layer這個部分很簡單啦,是根據feat_index選擇對應的weights['feature_embeddings']中的embedding值,然后再與對應的feat_value相乘就可以了:
# Embeddingsself.embeddings = tf.nn.embedding_lookup(self.weights['feature_embeddings'],self.feat_index) # N * F * Kfeat_value = tf.reshape(self.feat_value,shape=[-1,self.field_size,1])self.embeddings = tf.multiply(self.embeddings,feat_value) # N * F * K
Product Layer根據之前的介紹,我們分別計算線性信號向量,二次信號向量,以及偏置項,三者相加同時經過relu激活得到深度網絡部分的輸入。
# Linear Singallinear_output = []for i in range(self.deep_init_size): linear_output.append(tf.reshape( tf.reduce_sum(tf.multiply(self.embeddings,self.weights['product-linear'][i]),axis=[1,2]),shape=(-1,1)))# N * 1self.lz = tf.concat(linear_output,axis=1) # N * init_deep_size# Quardatic Singalquadratic_output = []if self.use_inner: for i in range(self.deep_init_size): theta = tf.multiply(self.embeddings,tf.reshape(self.weights['product-quadratic-inner'][i],(1,-1,1))) # N * F * K quadratic_output.append(tf.reshape(tf.norm(tf.reduce_sum(theta,axis=1),axis=1),shape=(-1,1))) # N * 1else: embedding_sum = tf.reduce_sum(self.embeddings,axis=1) p = tf.matmul(tf.expand_dims(embedding_sum,2),tf.expand_dims(embedding_sum,1)) # N * K * K for i in range(self.deep_init_size): theta = tf.multiply(p,tf.expand_dims(self.weights['product-quadratic-outer'][i],0)) # N * K * K quadratic_output.append(tf.reshape(tf.reduce_sum(theta,axis=[1,2]),shape=(-1,1))) # N * 1self.lp = tf.concat(quadratic_output,axis=1) # N * init_deep_sizeself.y_deep = tf.nn.relu(tf.add(tf.add(self.lz, self.lp), self.weights['product-bias']))self.y_deep = tf.nn.dropout(self.y_deep, self.dropout_keep_deep[0])
Deep Part論文中的Deep Part實際上只有一層,不過我們可以隨意設置,最后得到輸出:
# Deep componentfor i in range(0,len(self.deep_layers)): self.y_deep = tf.add(tf.matmul(self.y_deep,self.weights["layer_%d" %i]), self.weights["bias_%d"%i]) self.y_deep = self.deep_layers_activation(self.y_deep) self.y_deep = tf.nn.dropout(self.y_deep,self.dropout_keep_deep[i+1])self.out = tf.add(tf.matmul(self.y_deep,self.weights['output']),self.weights['output_bias'])
剩下的代碼就不介紹啦!好啦,本文只是提供一個引子,有關PNN的知識大家可以更多的進行學習呦。
-
網絡結構
+關注
關注
0文章
48瀏覽量
11651 -
深度學習
+關注
關注
73文章
5569瀏覽量
123061 -
dnn
+關注
關注
0文章
61瀏覽量
9311
原文標題:推薦系統遇上深度學習(六)--PNN模型理論和實踐
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【我是電子發燒友】如何加速DNN運算?
神經網絡結構搜索有什么優勢?
TD-SCDMA網絡結構
DeviceNet 網絡結構
HFC網絡,HFC網絡結構組成是什么?
環形網絡,環形網絡結構是什么?
如何優化PLC的網絡結構?






 工商網監
工商網監

評論