


今天來看看強化學習,不過不是要用它來玩游戲,而是覺得它在制造業,庫存,電商,廣告,推薦,金融,醫療等與我們生活息息相關的領域也有很好的應用,當然要了解一下了。
本文結構:
定義
和監督式學習, 非監督式學習的區別
主要算法和類別
應用舉例
▌1. 定義
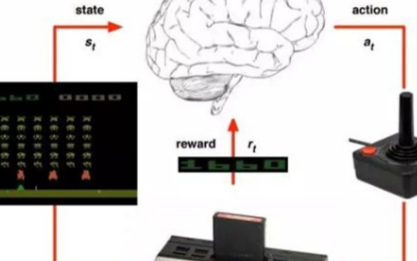
強化學習是機器學習的一個重要分支,是多學科多領域交叉的一個產物,它的本質是解決decision making 問題,即自動進行決策,并且可以做連續決策。
它主要包含四個元素,agent,環境狀態,行動,獎勵, 強化學習的目標就是獲得最多的累計獎勵。
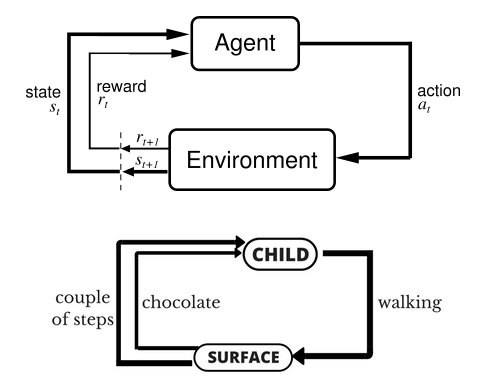
讓我們以小孩學習走路來做個形象的例子:
小孩想要走路,但在這之前,他需要先站起來,站起來之后還要保持平衡,接下來還要先邁出一條腿,是左腿還是右腿,邁出一步后還要邁出下一步。
小孩就是 agent,他試圖通過采取行動(即行走)來操縱環境(行走的表面),并且從一個狀態轉變到另一個狀態(即他走的每一步),當他完成任務的子任務(即走了幾步)時,孩子得到獎勵(給巧克力吃),并且當他不能走路時,就不會給巧克力。
▌2. 和監督式學習, 非監督式學習的區別
在機器學習中,我們比較熟知的是監督式學習,非監督學習,此外還有一個大類就是強化學習:
強化學習和監督式學習的區別:
監督式學習就好比你在學習的時候,有一個導師在旁邊指點,他知道怎么是對的怎么是錯的,但在很多實際問題中,例如 chess,go,這種有成千上萬種組合方式的情況,不可能有一個導師知道所有可能的結果。
而這時,強化學習會在沒有任何標簽的情況下,通過先嘗試做出一些行為得到一個結果,通過這個結果是對還是錯的反饋,調整之前的行為,就這樣不斷的調整,算法能夠學習到在什么樣的情況下選擇什么樣的行為可以得到最好的結果。
就好比你有一只還沒有訓練好的小狗,每當它把屋子弄亂后,就減少美味食物的數量(懲罰),每次表現不錯時,就加倍美味食物的數量(獎勵),那么小狗最終會學到一個知識,就是把客廳弄亂是不好的行為。
兩種學習方式都會學習出輸入到輸出的一個映射,監督式學習出的是之間的關系,可以告訴算法什么樣的輸入對應著什么樣的輸出,強化學習出的是給機器的反饋 reward function,即用來判斷這個行為是好是壞。
另外強化學習的結果反饋有延時,有時候可能需要走了很多步以后才知道以前的某一步的選擇是好還是壞,而監督學習做了比較壞的選擇會立刻反饋給算法。
而且強化學習面對的輸入總是在變化,每當算法做出一個行為,它影響下一次決策的輸入,而監督學習的輸入是獨立同分布的。
通過強化學習,一個 agent 可以在探索和開發(exploration and exploitation)之間做權衡,并且選擇一個最大的回報。exploration 會嘗試很多不同的事情,看它們是否比以前嘗試過的更好。exploitation 會嘗試過去經驗中最有效的行為。
一般的監督學習算法不考慮這種平衡,就只是是 exploitative。
強化學習和非監督式學習的區別:
非監督式不是學習輸入到輸出的映射,而是模式。例如在向用戶推薦新聞文章的任務中,非監督式會找到用戶先前已經閱讀過類似的文章并向他們推薦其一,而強化學習將通過向用戶先推薦少量的新聞,并不斷獲得來自用戶的反饋,最后構建用戶可能會喜歡的文章的“知識圖”。
▌3. 主要算法和分類
從強化學習的幾個元素的角度劃分的話,方法主要有下面幾類:
Policy based, 關注點是找到最優策略。
Value based, 關注點是找到最優獎勵總和。
Action based, 關注點是每一步的最優行動。
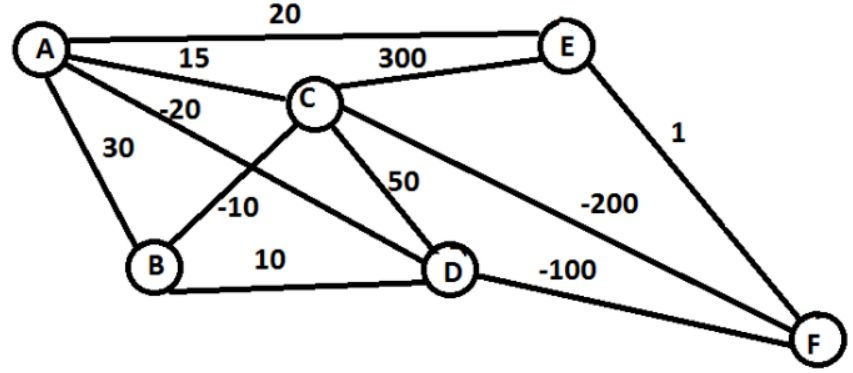
我們可以用一個最熟知的旅行商例子來看,
我們要從 A 走到 F,每兩點之間表示這條路的成本,我們要選擇路徑讓成本越低越好:
那么幾大元素分別是:
states ,就是節點 {A, B, C, D, E, F}
action ,就是從一點走到下一點 {A -> B, C -> D, etc}
reward function ,就是邊上的 cost
policy,就是完成任務的整條路徑 {A -> C -> F}
有一種走法是這樣的,在 A 時,可以選的 (B, C, D, E),發現 D 最優,就走到 D,此時,可以選的 (B, C, F),發現 F 最優,就走到 F,此時完成任務。
這個算法就是強化學習的一種,叫做epsilon greedy,是一種Policy based的方法,當然了這個路徑并不是最優的走法。
此外還可以從不同角度使分類更細一些:
如下圖所示的四種分類方式,分別對應著相應的主要算法:
Model-free:不嘗試去理解環境, 環境給什么就是什么,一步一步等待真實世界的反饋, 再根據反饋采取下一步行動。
Model-based:先理解真實世界是怎樣的, 并建立一個模型來模擬現實世界的反饋,通過想象來預判斷接下來將要發生的所有情況,然后選擇這些想象情況中最好的那種,并依據這種情況來采取下一步的策略。它比 Model-free 多出了一個虛擬環境,還有想象力。
Policy based:通過感官分析所處的環境, 直接輸出下一步要采取的各種動作的概率, 然后根據概率采取行動。
Value based:輸出的是所有動作的價值, 根據最高價值來選動作,這類方法不能選取連續的動作。
Monte-carlo update:游戲開始后, 要等待游戲結束, 然后再總結這一回合中的所有轉折點, 再更新行為準則。
Temporal-difference update:在游戲進行中每一步都在更新, 不用等待游戲的結束, 這樣就能邊玩邊學習了。
On-policy:必須本人在場, 并且一定是本人邊玩邊學習。
Off-policy:可以選擇自己玩, 也可以選擇看著別人玩, 通過看別人玩來學習別人的行為準則。
主要算法有下面幾種,這里先只是簡述:
(1). Sarsa

Q 為動作效用函數(action-utility function),用于評價在特定狀態下采取某個動作的優劣,可以將之理解為智能體(Agent)的大腦。
SARSA 利用馬爾科夫性質,只利用了下一步信息, 讓系統按照策略指引進行探索,在探索每一步都進行狀態價值的更新,更新公式如下所示:
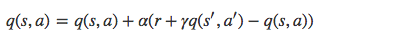
s 為當前狀態,a 是當前采取的動作,s’ 為下一步狀態,a’ 是下一個狀態采取的動作,r 是系統獲得的獎勵, α 是學習率, γ 是衰減因子。
(2). Q learning

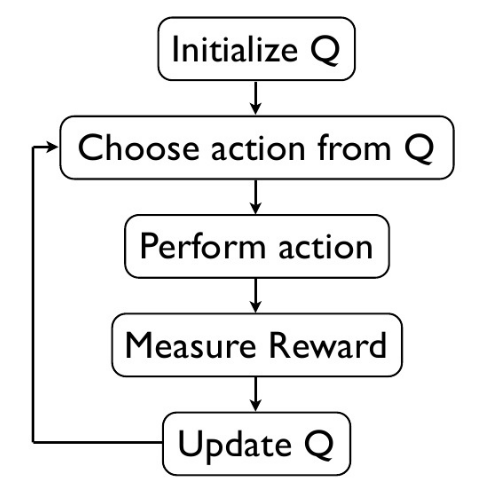
Q Learning 的算法框架和 SARSA 類似, 也是讓系統按照策略指引進行探索,在探索每一步都進行狀態價值的更新。關鍵在于 Q Learning 和 SARSA 的更新公式不一樣,Q Learning 的更新公式如下:
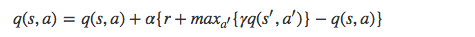
(3). Policy Gradients
系統會從一個固定或者隨機起始狀態出發,策略梯度讓系統探索環境,生成一個從起始狀態到終止狀態的狀態-動作-獎勵序列,s1,a1,r1,.....,sT,aT,rT,在第 t 時刻,我們讓gt=rt+γrt+1+... 等于 q(st,a),從而求解策略梯度優化問題。
(4). Actor-Critic
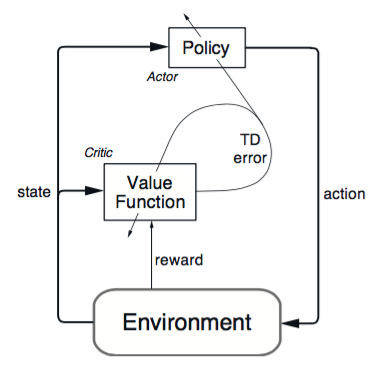
算法分為兩個部分:Actor 和 Critic。Actor 更新策略, Critic 更新價值。Critic 就可以用之前介紹的 SARSA 或者 Q Learning 算法。
(5). Monte-carlo learning
用當前策略探索產生一個完整的狀態-動作-獎勵序列:
s1,a1,r1,....,sk,ak,rk~π
在序列第一次碰到或者每次碰到一個狀態 s 時,計算其衰減獎勵:
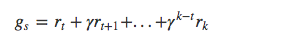
最后更新狀態價值:
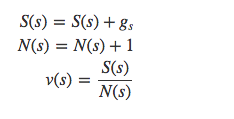
(6). Deep-Q-Network
DQN 算法的主要做法是 Experience Replay,將系統探索環境得到的數據儲存起來,然后隨機采樣樣本更新深度神經網絡的參數。它也是在每個 action 和 environment state 下達到最大回報,不同的是加了一些改進,加入了經驗回放和決斗網絡架構。

▌4. 應用舉例
強化學習有很多應用,除了無人駕駛,AlphaGo,玩游戲之外,還有下面這些工程中實用的例子:
(1). Manufacturing
例如一家日本公司 Fanuc,工廠機器人在拿起一個物體時,會捕捉這個過程的視頻,記住它每次操作的行動,操作成功還是失敗了,積累經驗,下一次可以更快更準地采取行動。
(2). Inventory Management
在庫存管理中,因為庫存量大,庫存需求波動較大,庫存補貨速度緩慢等阻礙使得管理是個比較難的問題,可以通過建立強化學習算法來減少庫存周轉時間,提高空間利用率。
(3). Dynamic pricing
強化學習中的 Q-learning 可以用來處理動態定價問題。
(4). Customer Delivery
制造商在向各個客戶運輸時,想要在滿足客戶的所有需求的同時降低車隊總成本。通過 multi-agents 系統和 Q-learning,可以降低時間,減少車輛數量。
(5). ECommerce Personalization
在電商中,也可以用強化學習算法來學習和分析顧客行為,定制產品和服務以滿足客戶的個性化需求。
(6). Ad Serving
例如算法 LinUCB (屬于強化學習算法 bandit 的一種算法),會嘗試投放更廣范圍的廣告,盡管過去還沒有被瀏覽很多,能夠更好地估計真實的點擊
率。
再如雙 11 推薦場景中,阿里巴巴使用了深度強化學習與自適應在線學習,通過持續機器學習和模型優化建立決策引擎,對海量用戶行為以及百億級商品特征進行實時分析,幫助每一個用戶迅速發現寶貝,提高人和商品的配對效率。還有,利用強化學習將手機用戶點擊率提升了 10-20%。
(7). Financial Investment Decisions
例如這家公司 Pit.ai,應用強化學習來評價交易策略,可以幫助用戶建立交易策略,并幫助他們實現其投資目標。
(8). Medical Industry
動態治療方案(DTR)是醫學研究的一個主題,是為了給患者找到有效的治療方法。 例如癌癥這種需要長期施藥的治療,強化學習算法可以將患者的各種臨床指標作為輸入 來制定治療策略。
-
機器學習
+關注
關注
66文章
8507瀏覽量
134738 -
強化學習
+關注
關注
4文章
269瀏覽量
11621
原文標題:一文了解強化學習
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
深度強化學習實戰

機器學習算法中有監督和無監督學習的區別
最基礎的半監督學習
機器學習中的無模型強化學習算法及研究綜述

強化學習的基礎知識和6種基本算法解釋
強化學習的基礎知識和6種基本算法解釋

什么是強化學習






 工商網監
工商網監

評論