 深入分析GeForce RTX 20系列顯卡值不值得買?
深入分析GeForce RTX 20系列顯卡值不值得買?
本周NVIDIA震撼發布的GeForce RTX 20系列顯卡值不值得買?如何選擇適合你的GPU?本文章深入分析這個問題,并提供建議,幫你做出最合適的選擇。
深度學習常被戲謔為“煉丹術”,那么,GPU于深度學習研究人員而言就是不可或缺的“煉丹爐”。
深度學習是一個計算要求很高的領域,選擇什么 GPU、選擇多少個 GPU 將從根本上決定你的深度學習體驗。如果沒有 GPU,可能需要好幾個月等待實驗完成,或者實驗運行一整天下來只是看到失敗的結果。
憑借良好、可靠的 GPU,煉丹師們可以快速迭代深度網絡的設計和參數,運行實驗的時間只需幾天而不是幾個月,幾小時而不是幾天,幾分鐘而不是幾小時。因此,在購買 GPU 時做出正確的選擇至關重要。
那么如何選擇適合你的 GPU 呢?本文作者Tim Dettmers是瑞士盧加諾大學信息學碩士,熱衷于開發自己的 GPU 集群和算法來加速深度學習。這篇文章深入研究這個問題,并提供建議,幫你做出最合適的選擇。
本周 NVIDIA 震撼發布的 GeForceRTX 20 系列顯卡值不值得買?它的能力、性價比如何?本文也給出分析。
先放結論:RTX 2080 最具成本效益的選擇。當然,GTX 1080/1070(+ Ti)卡仍然是非常好的選擇。
作者給出的GPU建議如下:
總體來說最好的 GPU 是:RTX 2080 Ti
成本效益高,但價格昂貴:RTX 2080, GTX 1080
成本效益高,且價格實惠: GTX 1070, GTX 1070 Ti, GTX 1060
我使用的數據集 > 250GB: RTX 2080 Ti or RTX 2080
我沒有太多預算: GTX 1060 (6GB)
我很窮:GTX 1050 Ti (4GB) or CPU (prototyping) + AWS/TPU (training)
我參加 Kaggle 競賽:GTX 1060 (6GB) 用于原型設計 , AWS 用于最終訓練; 使用 fastai 庫
我是計算機視覺研究人員:RTX 2080 Ti; 2019 年可以升級到 RTX Titan
我是一名研究人員:RTX 2080 Ti 或 GTX 10XX -> RTX Titan(看一下你當前模型的存儲要求)
我想建立一個 GPU 集群:這很復雜,可以參考這篇文章[1]
我剛開始進行深度學習,并且我是認真的:可以先從 GTX 1060 (6GB) 開始,或者從便宜的 GTX 1070 或 GTX 1070 Ti 開始。這取決于你下一步想做什么(去初創公司,參加 Kaggle 競賽,做研究,應用深度學習),然后賣掉最初的 GPU 再買更適合的
全面對比:NVIDIA、AMD、Intel、Google、Amazon
NVIDIA: 絕對王者
NVIDIA 的標準庫使得在 CUDA 中建立第一個深度學習庫變得非常容易,而 AMD 的 OpenCL 卻沒有這樣強大的標準庫。這種領先優勢,再加上英偉達強大的社區支持,迅速擴大了 CUDA 社區的規模。這意味著,如果你使用 NVIDIA GPU,在遇到問題時可以很容易找到支持;如果你自己寫 CUDA 程序,也很容易找到支持和建議,并且你會發現大多數深度學習庫都對 NVIDIA GPU 提供最佳支持。對于 NVIDIA GPU 來說,這是非常強大的優勢。
另一方面,英偉達現在有一項政策,在數據中心使用 CUDA 只允許 Tesla GPU,而不允許使用 GTX 或 RTX 卡。“數據中心” 的含義模糊不清,但這意味著,由于擔心法律問題,研究機構和大學往往被迫購買昂貴而且成本效率低的 Tesla GPU。然而,Tesla 卡與 GTX 和 RTX 卡相比并無大的優勢,價格卻要高 10 倍。
英偉達能夠沒有任何大障礙地實施這些政策,這顯示出其壟斷力量——他們可以隨心所欲,我們必須接受這些條款。如果你選擇了 NVIDIA GPU 在社區和支持方面的主要優勢,你還需要接受他們的隨意擺布。
AMD:能力強大,但缺乏支持
HIP 通過 ROCm 將 NVIDIA 和 AMD 的 GPU 統一在一種通用編程語言之下,在編譯成 GPU 匯編代碼之前被編譯成各自的 GPU 語言。如果我們的所有 GPU 代碼都在 HIP 中,這將成為一個重要里程碑,但這是相當困難的,因為 TensorFlow 和 PyTorch 代碼基很難移植。TensorFlow 對 AMD GPU 有一些支持,所有的主要網絡都可以在 AMD GPU 上運行,但是如果你想開發新的網絡,可能會遺漏一些細節,這可能阻止你實現想要的結果。ROCm 社區也不是很大,因此要快速解決問題并不容易。此外,AMD 似乎也沒有太多資金用于深度學習開發和支持,這減緩了發展的勢頭。
但是,AMD GPU 性能并不比 NVIDIA GPU 表現差,而且下一代 AMD GPU Vega 20 將會是計算能力非常強大的處理器,具有類似 Tensor Core 的計算單元。
總的來說,對于那些只希望 GPU 能夠順利運行的普通用戶,我仍然無法明確推薦 AMD GPU。更有經驗的用戶應該遇到的問題不多,并且支持 AMD GPU 和 ROCm / HIP 開發人員有助于打擊英偉達的壟斷地位,從長遠來看,這將為每個人帶來好處。如果你是 GPU 開發人員并希望為 GPU 計算做出重要貢獻,那么 AMD GPU 可能是長期產生良好影響的最佳方式。對于其他人來說,NVIDIA GPU 是更安全的選擇。
英特爾:仍需努力
我個人對英特爾 Xeon Phis 的經驗非常令人失望,我認為它們不是 NVIDIA 或 AMD 顯卡的真正競爭對手:如果你決定使用 Xeon Phi,請注意,你遇到問題時能得到的支持很有限,計算代碼段比 CPU 慢,編寫優化代碼非常困難,不完全支持 c++ 11 特征,不支持一些重要的 GPU 設計模式編譯器,與其他以來 BLAS routine 的庫(例如 NumPy 和 SciPy))的兼容性差,以及可能還有許多我沒遇到的挫折。
我很期待英特爾 Nervana 神經網絡處理器(NNP),因為它的規格非常強大,它可以允許新的算法,可能重新定義神經網絡的使用方式。NNP 計劃在 2019 年第三季度 / 第四季度發布。
谷歌:按需處理更便宜?
Google TPU 已經發展成為非常成熟的基于云的產品,具有極高的成本效益。理解 TPU 最簡單的方法是將它看作多個打包在一起的 GPU。如果我們看一下支持 Tensor Core 的 V100 和 TPUv2 的性能指標,我們會發現對于 ResNet50,這兩個系統的性能幾乎相同。但是,谷歌 TPU 更劃算。
那么,TPU 是不是基于云的經濟高效的解決方案呢?可以說是,也可以說不是。不管在論文上還是在日常使用上,TPU 都更具成本效益。但是,如果你使用 fastai 團隊的最佳實踐和指南以及 fastai 庫,你可以以更低的價格實現更快的收斂——至少對于用卷及網絡進行對象識別來說是這樣。
使用相同的軟件,TPU 甚至可以更具成本效益,但這也存在問題:(1)TPU 不能用于 fastai 庫,即 PyTorch;(2)TPU 算法主要依賴于谷歌內部團隊,(3)沒有統一的高層庫可以為 TensorFlow 實施良好的標準。
這三點都打擊了 TPU,因為它需要單獨的軟件才能跟上深度學習的新算法。我相信谷歌的團隊已經完成了這些工作,但是還不清楚對某些模型的支持有多好。例如,TPU 的官方 GitHub 庫只有一個 NLP 模型,其余的都是計算機視覺模型。所有模型都使用卷積,沒有一個是循環神經網絡。不過,隨著時間的推移,軟件支持很可能會迅速改進,并且成本會進一步下降,使 TPU 成為一個有吸引力的選擇。不過,目前 TPU 似乎最適合用于計算機視覺,并作為其他計算資源的補充,而不是主要的深度學習資源。
亞馬遜:可靠但價格昂貴
自從上次更新這篇博文以來,AWS 已經添加了很多新的 GPU。但是,價格仍然有點高。如果你突然需要額外的計算,例如在研究論文 deadline 之前所有 GPU 都在使用,AWS GPU instances 可能是一個非常有用的解決方案
然而,如果它有成本效益,那么就應該確保只運行幾個網絡,并且確切地知道為訓練運行選擇的參數是接近最優的。否則,成本效益會大大降低,還不如專用 GPU 有用。即使快速的 AWS GPU 是誘人的堅實的 gtx1070 和 up 將能夠提供良好的計算性能一年或兩年沒有太多的成本。
總結而言,AWS GPU instance 非常有用,但需要明智而謹慎地使用它們,以確保成本效益。有關云計算,我們后面還會再討論。
是什么讓一個 GPU 比另一個更快?
選擇 GPU 時,你的第一個問題可能是:對于深度學習來說,使得 GPU 運算速度快的最重要的特性是什么?是 CUDA Core,時鐘速度,還是 RAM 的大小?
雖然一個很好的簡化建議應該是 “注意內存帶寬”,但我不再建議這樣做。這是因為 GPU 硬件和軟件多年來的開發方式使得 GPU 的帶寬不再是其性能的最佳指標。在消費級 GPU 中引入 Tensor Core 進一步復雜化了這個問題。現在,帶寬、FLOPS 和 Tensor Core 的組合才是 GPU 性能的最佳指標。
為了加深理解,做出明智的選擇,最好要了解一下硬件的哪些部分使 GPU 能夠快速執行兩種最重要的張量操作:矩陣乘法和卷積。
考慮矩陣乘法的一個簡單而有效的方法是:它是受帶寬約束的。如果你想使用 LSTM 和其他需要做很多矩陣乘法的循環網絡的話,內存帶寬是 GPU 最重要的特性,
同樣,卷積受計算速度約束。因此,對于 ResNets 和其他卷積體系結構來說,GPU 的 TFLOP 是其性能的最佳指標。
Tensor Cores 稍微改變了這種平衡。Tensor Cores 是專用計算單元,可以加速計算——但不會加大內存帶寬——因此對于卷積網絡來說,最大的好處是 Tensor Core 可以使速度加快30%到 100%。
雖然Tensor Cores只能加快計算速度,但它們也允許使用 16-bit 數字進行計算。這也是矩陣乘法的一大優點,因為數字的大小只有 16-bit 而不是 32-bit,在內存帶寬相同的矩陣中,數字的數量可以傳輸兩倍。一般來說,使用 Tensor Cores 的 LSTM 可以加速 20% 到 60%。
請注意,這種加速并不是來自 Tensor Cores 本身,而是來自它進行 16-bit 計算的能力。在 AMD GPU 上的 16-bit 算法和在 NVIDIA 的具有 Tensor Cores 的卡上的矩陣乘法算法一樣快。
Tensor Cores 的一個大問題是它們需要 16-bit 浮點輸入數據,這可能會帶來一些軟件支持問題,因為網絡通常使用 32-bit 的值。如果沒有 16-bit 的輸入,Tensor Cores 就相當于沒用的。
但是,我認為這些問題很快就能得到解決,因為 Tensor Cores 太強大了,現在消費級 GPU 也使用 Tensor Cores,因此,將會有越來越多的人使用它們。隨著 16-bit 深度學習的引入,我們實際上使 GPU 的內存翻倍了,因為同樣內存的 GPU 中包含的參數翻倍了。
總的來說,最好的經驗法則是:如果你使用 RNN,要看帶寬;如果使用卷積,就看看 FLOPS;如果你買得起,就考慮 Tensor Cores(除非必要,否則不要買 Tesla 卡)

GPU 和 TPU 的標準化原始性能數據。越高越好。 RTX 2080 Ti 的速度大約是 GTX1080 Ti 的兩倍:0.75 vs 0.4。
性價比分析
性價比也許是選擇 GPU 時要考慮的最重要的一類指標。我對此做了一個新的成本性能分析,其中考慮了內存位寬、運算速度和 Tensor 核心。價格上,我參考了亞馬遜和 eBay 上的價格,參考權重比為 1:1。然后我考察了使用 / 不使用 Tensor Core 情況下的 LSTM、CNN 等性能指標。將這些指標數字通過標準化幾何平均得到平均性能評分,計算出性價比數字,結果如下:
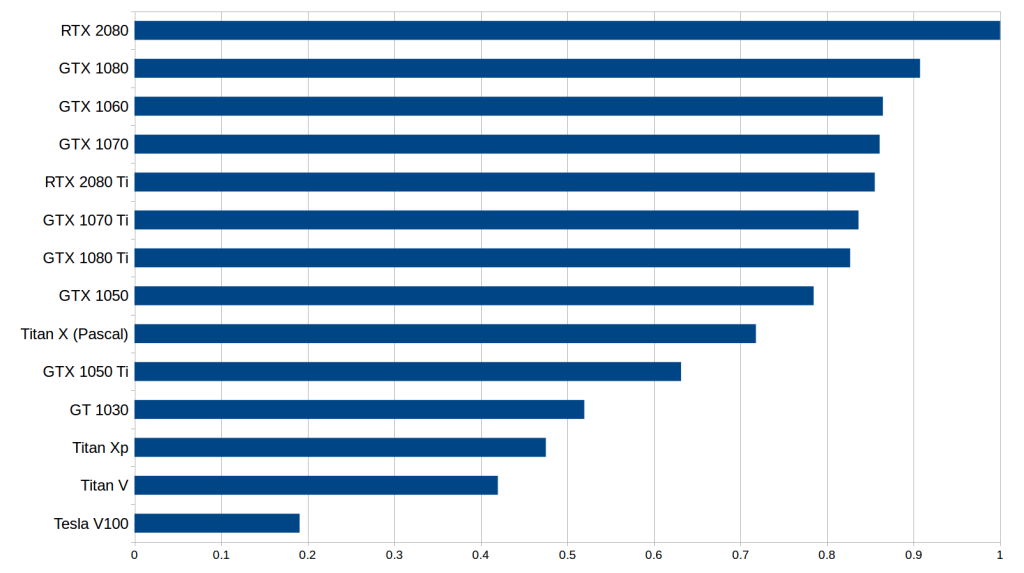
標準化處理后的性價比結果,考慮了內存帶寬(RNN)、計算速度(卷積網絡)、是否使用 Tensor Cores 等因素,數字越高越好。RTX2080 的性價比大概是 Tesla V100 的 5 倍。
請注意,RTX 2080 和 RTX 2080 Ti 的數字可能有些水分,因為實際的硬性能數據還未發布。我根據這個硬件下的矩陣乘法和卷積的 roofline 模型以及來自 V100 和 Titan V 的 Tensor Core 基準數字來估計性能。由于目前沒有硬件規格數字,RTX 2070 完全沒有排入。注意,RTX 2070 可能很容易在成本效益上擊敗其他兩款 RTX 系列顯卡,但目前沒有數據支持。
從初步數據來看,我們發現 RTX 2080 比 RTX 2080 Ti 的性價比更高。 與 RTX2080 相比,RTX 2080 Ti 的 Tensor 核心和帶寬增加了約 40%,價格提高了 50%,但性能并沒有提高 40%。對于 LSTM 和其他 RNN 來說,從 GTX 10 系到 RTX 20 系的性能增長,主要是在于支持了 16 位浮點計算,而不是 Tensor 核心本身。雖然卷積網絡的性能在理論上應該與 Tensor 核心呈線性增加,但我們從性能數據中并沒有看出這一點。
這表明,卷積體系結構的其他部分無法憑借 Tensor 核心獲得性能提升,而這些部分在整體計算需求中也占了很大比重。因此,RTX 2080 具有更高的性價比,因為它具有比 GTX 10 系列獲得性能提升(GDDR6 + Tensor 核心)所需的所有功能,同時也比 RTX 2080 Ti 更便宜。
此外請讀者注意,這個分析中存在一些問題,對這些數據的解釋需要慎重:
(1)如果你購買的是高性價比、但運算速度較慢的顯卡,那么在某些時候計算機可能不再會有更多 GPU 空間,因此會造成資源浪費。因此,本圖表偏向于昂貴的 GPU。為了抵消這種偏差,還應該對原始性能圖表進行評估。
(2)此性價比圖表假設,讀者會盡量多地使用 16 位計算和 Tensor 內核。也就是說,對于 32 位計算而言,RTX 系顯卡的性價比很低。
(3)此前有傳聞說,有大量的 RTX 20 系顯卡由于加密貨幣行情的下滑而被延緩發布。因此,像 GTX 1080 和 GTX 1070 這樣流行的挖礦 GPU 可能會迅速降價,其性價比可能會迅速提高,使得 RTX 20 系列在性價比方面不那么有優勢。另一方面,大量的 RTX 20 系顯卡的價格將保持穩定,以確保其具備競爭力。很難預測這些顯卡的后續前景。
(4)如前文所述,目前還沒有關于 RTX 顯卡硬性、無偏見的性能數據,因此所有這些數字都不能太當真。
可以看出,在這么多顯卡中做出正確選擇并不容易。但是,如果讀者對所有這些問題采取一種平衡的觀點,其實還是能夠做出自己的最佳選擇的。
云端深度學習
AWS 上的 GPU 實例和 Google Cloud 中的 TPU 都是深度學習的可行選擇。雖然 TPU 稍微便宜一點,但它缺乏 AWS GPU 的多功能性和靈活性。 TPU 可能是訓練目標識別模型的首選。但對于其他類型的工作負載,AWS GPU 可能是更安全的選擇。部署云端實例的好處在于可以隨時在 GPU 和 TPU 之間切換,甚至可以同時使用它們。
但是,請注意這種場景下的機會成本問題:如果讀者學習了使用 AWS 實例能夠順利完成工作流程的技能,那么也就失去了利用個人 GPU 進行工作的時間,也無法獲得使用 TPU 的技能。而如果使用個人 GPU,就無法通過云擴展到更多 GPU / TPU 上。如果使用 TPU,就無法使用 TensorFlow,而且,切換到 AWS 平臺并不是一件很容易的事。流暢的云工作流程的學習成本是非常高的,如果選擇 TPU 或 AWS GPU,應該仔細衡量一下這個成本。
另一個問題是關于何時使用云服務。如果讀者想學習深度學習或者需要設計原型,那么使用個人 GPU 可能是最好的選擇,因為云實例可能成本昂貴。但是,一旦找到了良好的深度網絡配置,并且只想使用與云實例的數據并行性來訓練模型,使用云服務是一種可靠的途徑。也就是說,要做原型設計,使用小型 GPU 就夠了,也可以依賴云計算的強大功能來擴大實驗規模,實現更復雜的計算。
如果你的資金不足,使用云計算實例也可能是一個很好的解決方案,但問題是,當你只需要一點點原型設計時,還是只能分時購買大量計算力,造成成本和計算力的浪費。在這種情況下,人們可能希望在 CPU 上進行原型設計,然后在 GPU / TPU 實例上進行快速訓練。這并不是最優的工作流程,因為在 CPU 上進行原型設計可能是非常痛苦的,但它確實是一種經濟高效的解決方案。
結論
在本文中,讀者應該能夠了解哪種 GPU 適合自己。總的來說,我認為在選擇 GPU 是有兩個主要策略:要么現在就使用 RTX 20 系列 GPU 實現快速升級,或者先使用便宜的 GTX 10 系列 GPU,在 RTX Titan 上市后再進行升級。如果對性能沒那么看重,或者干脆不需要高性能,比如 Kaggle 數據競賽、創業公司、原型設計或學習深度學習,那么相對廉價的 GTX 10 系列 GPU 也是很好的選擇。如果你選擇了 GTX 10 系列 GPU,請注意確保 GPU 顯存大小可以滿足你的要求。
那么對于深度學習,如何選擇GPU?我的建議如下:
總體來說最好的 GPU 是:RTX 2080 Ti
成本效益高,但價格昂貴:RTX 2080, GTX 1080
成本效益高,且價格實惠: GTX 1070, GTX 1070 Ti, GTX 1060
我使用的數據集 > 250GB: RTX 2080 Ti or RTX 2080
我沒有太多預算: GTX 1060 (6GB)
我很窮:GTX 1050 Ti (4GB) or CPU (prototyping) + AWS/TPU (training)
我參加 Kaggle 競賽:GTX 1060 (6GB) 用于原型設計 , AWS 用于最終訓練; 使用 fastai 庫
我是計算機視覺研究人員:RTX 2080 Ti; 2019 年可以升級到 RTX Titan
我是一名研究人員:RTX 2080 Ti 或 GTX 10XX -> RTX Titan(看一下你當前模型的存儲要求)
我想建立一個 GPU 集群:這很復雜,可以參考這篇文章[1]
我剛開始進行深度學習,并且我是認真的:可以先從 GTX 1060 (6GB) 開始,或者從便宜的 GTX 1070 或 GTX 1070 Ti 開始。這取決于你下一步想做什么(去初創公司,參加 Kaggle 競賽,做研究,應用深度學習),然后賣掉最初的 GPU 再買更適合的
-
gpu
+關注
關注
28文章
4729瀏覽量
128901 -
顯卡
+關注
關注
16文章
2431瀏覽量
67580 -
深度學習
+關注
關注
73文章
5500瀏覽量
121117
原文標題:【深度分析】深度學習選GPU,RTX 20系列值不值得?
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
70元的STLINK V3 MINI ,值不值得入手?
iPhoneXR上手 值不值得買
榮耀手環4Running版上手體驗評測 值不值得買
NokiaX71手機評測 值不值得買
紅米7怎么樣 值不值得買
榮耀20i上手評測 值不值得買
三星A8s值不值得買
NokiaX71體驗評測 值不值得買
小米8青春版體驗評測 值不值得買
投影儀值不值得買?測機達人總結高性價比投影儀推薦






 工商網監
工商網監
評論