 一種名為“普適注意力”的新翻譯模型,用2D卷積網絡做序列預測
一種名為“普適注意力”的新翻譯模型,用2D卷積網絡做序列預測
目前的機器翻譯模型基于編碼器-解碼器系統結構,本文提出了一種名為“普適注意力”的新翻譯模型,用2D卷積網絡做序列預測,無論長句短句翻譯結果都更好,使用的參數也更少。實驗表明,新模型的總體表現優于目前最出色的解碼器-編碼器模型系統。
目前,最先進的機器翻譯系統基于編碼器-解碼器架構,首先對輸入序列進行編碼,然后根據輸入編碼生成輸出序列。兩者都與注意機制接口有關,該機制基于解碼器狀態,對源令牌的固定編碼進行重新組合。
本文提出了一種替代方法,該方法于跨兩個序列的單個2D卷積神經網絡。網絡的每一層都根據當前的輸出序列重新編碼源令牌。因此,類似注意力的屬性在整個網絡中普遍存在。我們的模型在實驗中表現出色,優于目前最先進的編碼器-解碼器系統,同時在概念上更簡單,參數更少。
“普適注意力”模型及原理
我們的模型中的卷積層使用隱性3×3濾波器,特征僅根據先前的輸出符號計算。圖為經過一層(深藍色)和兩層(淺藍色)計算之后的感受野,以及正常3×3濾波器(灰色)的視野的隱藏部分。
上圖為具有兩個隱藏層的解碼器網絡拓撲的圖示,底部和頂部的節點分別表示輸入和輸出。水平方向連接用于RNN,對角線方向連接用于卷積網絡。在兩種情況下都會使用垂直方向的連接。參數跨時間步長(水平方向)共享,但不跨層(垂直方向)共享。

塊級(頂部)和每個塊(底部)內的DenseNet體系結構

令牌嵌入大小、層數(L)和增長率(g)的影響
無論是長句、短句,翻譯結果都更好
與現有最佳技術的比較
我們將結果與表3中的現有技術進行了比較,包括德-英翻譯(De-En)和英-德翻譯(En-De)。我們的模型名為Pervasive Attention。除非另有說明,我們使用最大似然估計(MLE)訓練所有模型的參數。對于一些模型,我們會另外報告通過序列水平估計(SLE,如強化學習方法)獲得的結果,我們通常直接針對優化BLEU量度,而不是正確翻譯的概率。
在不同句子序列長度上的表現
在上圖中,我們將翻譯質量視為句子長度的函數,并將我們的模型與RNNsearch、ConvS2S和Transformer進行比較。結果表明,我們的模型幾乎在所有句子長度上都得到了最好的結果,ConvS2S和Transformer只在最長的句子上表現更好。總的來說,我們的模型兼備RNNsearch在短句中的強大表現,同時也接近ConvS2S和Transformer在較長句子上的良好表現。
隱性的句子對齊

上圖所示為最大池化運算符在我們的模型中生成的隱式句子對齊。作為參考,我們還展示了我們的模型使用的“自我注意力”產生的對齊。可以看到,兩種模型都成功定性地模擬了隱性的句子對齊。
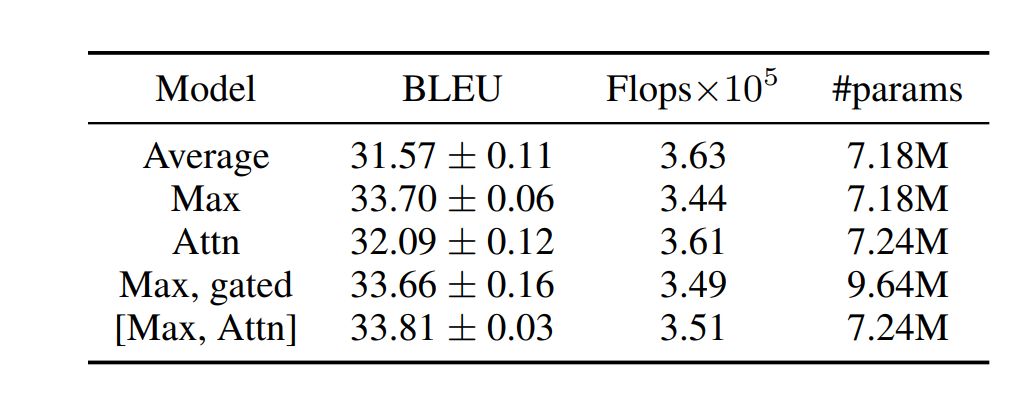
我們的模型(L = 24,g = 32,ds = dt = 128),具有不同的池化操作符,使用門控卷積單元

在不同的濾波器尺寸k和深度L下,我們的模型(g = 32,ds = dt = 128)的表現。
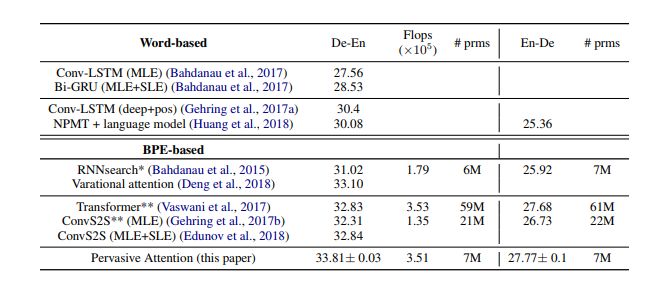
與IWSLT德語-英語翻譯模型的最新結果的比較。
(*):使用我們的實現獲得的結果(**):使用FairSeq獲得的結果。
脫離編碼器-解碼器范式,用DenseNet作機器翻譯
我們提出了一種新的神經機器翻譯架構,該架構脫離了編碼器-解碼器范例。我們的模型將源序列和目標序列聯合編碼為深度特征層次結構,其中源令牌嵌入到部分目標序列的上下文中。沿源維度對此聯合編碼進行最大池化,將相關要素映射到下一個目標令牌的預測。該模型實現基于DenseNet的2D CNN。
由于我們的模型會結合語境,對每一層當前生成的目標序列的輸入令牌重新編碼,因此該模型網絡構造的每層中都具有“類似注意力”(attention-like)的屬性。
因此,添加明確的“自注意模塊”具有非常有限、但十分積極的效果。然而,我們模型中的最大池化運算符生成的隱式句子對齊,在性質上與注意力機制生成的對齊類似。我們在IWSLT'14數據集上評估了我們的模型,將德-英雙語互譯。
我們獲得的BLEU分數與現有最佳方法相當,我們的模型使用的參數更少,概念上也更簡單。我們希望這一成果可以引發對編碼器-解碼器模型的替代方案的興趣。在未來,我們計劃研究混合方法,其中聯合編碼模型的輸入不是由嵌入向量提供的,而是1D源和目標嵌入網絡的輸出。
未來我們還將研究如何該模型來跨多語種進行翻譯。
-
濾波器
+關注
關注
161文章
7796瀏覽量
177997 -
編碼器
+關注
關注
45文章
3639瀏覽量
134429 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14880
原文標題:機器翻譯新突破!“普適注意力”模型:概念簡單參數少,性能大增
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
探索一種降低ViT模型訓練成本的方法
北大研究者創建了一種注意力生成對抗網絡
一種新的神經機器翻譯架構,它脫離了編碼器-解碼器的范疇
基于注意力機制的深度學習模型AT-DPCNN

一種注意力增強的自然語言推理模型aESIM

融合雙層多頭自注意力與CNN的回歸模型

基于深度圖注意力卷積CNN的三維模型識別方法

基于多層CNN和注意力機制的文本摘要模型

基于循環卷積注意力模型的文本情感分類方法
基于視覺注意力的全卷積網絡3D內容生成方法
一種新的深度注意力算法

一種基于因果路徑的層次圖卷積注意力網絡






 工商網監
工商網監
評論