 深入解讀人工智能、機器學習和認知計算
深入解讀人工智能、機器學習和認知計算
人工智能的發展曾經經歷過幾次起起伏伏,近來在深度學習技術的推動下又迎來了一波新的前所未有的高潮。近日,IBM 官網發表了一篇概述文章,對人工智能技術的發展過程進行了簡單梳理,同時還圖文并茂地介紹了感知器、聚類算法、基于規則的系統、機器學習、深度學習、神經網絡等技術的概念和原理。
人類對如何創造智能機器的思考從來沒有中斷過。期間,人工智能的發展起起伏伏,有成功,也有失敗,以及其中暗藏的潛力。今天,有太多的新聞報道是關于機器學習算法的應用問題,從癌癥檢查預測到圖像理解、自然語言處理,人工智能正在賦能并改變著這個世界。
現代人工智能的歷史具備成為一部偉大戲劇的所有元素。在最開始的 1950 年代,人工智能的發展緊緊圍繞著思考機器和焦點人物比如艾倫·圖靈、馮·諾伊曼,迎來了其第一次春天。經過數十年的繁榮與衰敗,以及難以置信的高期望,人工智能及其先驅們再次攜手來到一個新境界。現在,人工智能正展現著其真正的潛力,深度學習、認知計算等新技術不斷涌現,且不乏應用指向。
本文探討了人工智能及其子領域的一些重要方面。下面就先從人工智能發展的時間線開始,并逐個剖析其中的所有元素。
現代人工智能的時間線
1950 年代初期,人工智能聚焦在所謂的強人工智能,希望機器可以像人一樣完成任何智力任務。強人工智能的發展止步不前,導致了弱人工智能的出現,即把人工智能技術應用于更窄領域的問題。1980 年代之前,人工智能的研究一直被這兩種范式分割著,兩營相對。但是,1980 年左右,機器學習開始成為主流,它的目的是讓計算機具備學習和構建模型的能力,從而它們可在特定領域做出預測等行為。
圖 1:現代人工智能發展的時間線
在人工智能和機器學習研究的基礎之上,深度學習在 2000 年左右應運而生。計算機科學家在多層神經網絡之中使用了新的拓撲學和學習方法。最終,神經網絡的進化成功解決了多個領域的棘手問題。
在過去的十年中,認知計算(Cognitive computing)也出現了,其目標是打造可以學習并與人類自然交互的系統。通過成功地擊敗 Jeopardy 游戲的世界級選手,IBM Watson 證明了認知計算的價值。
在本文中,我將逐一探索上述的所有領域,并對一些關鍵算法作出解釋。
基礎性人工智能
1950 年之前的研究提出了大腦是由電脈沖網絡組成的想法,正是脈沖之間的交互產生了人類思想與意識。艾倫·圖靈表明一切計算皆是數字,那么,打造一臺能夠模擬人腦的機器也就并非遙不可及。
上文說過,早期的研究很多是強人工智能,但是也提出了一些基本概念,被機器學習和深度學習沿用至今。
圖 2:1950 - 1980 年間人工智能方法的時間線
人工智能搜索引擎
人工智能中的很多問題可以通過強力搜索(brute-force search)得到解決。然而,考慮到中等問題的搜索空間,基本搜索很快就受影響。人工智能搜索的最早期例子之一是跳棋程序的開發。亞瑟·塞繆爾(Arthur Samuel)在 IBM 701 電子數據處理機器上打造了第一款跳棋程序,實現了對搜索樹(alpha-beta 剪枝)的優化;這個程序也記錄并獎勵具體行動,允許應用學習每一個玩過的游戲(這是首個自我學習的程序)。為了提升程序的學習率,塞繆爾將其編程為自我游戲,以提升其游戲和學習的能力。
盡管你可以成功地把搜索應用到很多簡單問題上,但是當選擇的數量增加時,這一方法很快就會失效。以簡單的一字棋游戲為例,游戲一開始,有 9 步可能的走棋,每 1 個走棋有 8 個可能的相反走棋,依次類推。一字棋的完整走棋樹包含 362,880 個節點。如果你繼續將這一想法擴展到國際象棋或者圍棋,很快你就會發展搜索的劣勢。
感知器
感知器是單層神經網絡的一個早期監督學習算法。給定一個輸入特征向量,感知器可對輸入進行具體分類。通過使用訓練集,網絡的權重和偏差可為線性分類而更新。感知器的首次實現是 IBM 704,接著在自定義硬件上用于圖像識別。

圖 3:感知器與線性分類
作為一個線性分類器,感知器有能力解決線性分離問題。感知器局限性的典型實例是它無法學習專屬的 OR (XOR) 函數。多層感知器解決了這一問題,并為更復雜的算法、網絡拓撲學、深度學習奠定了基礎。
聚類算法
使用感知器的方法是有監督的。用戶提供數據來訓練網絡,然后在新數據上對該網絡進行測試。聚類算法則是一種無監督學習(unsupervised learning)方法。在這種模型中,算法會根據數據的一個或多個屬性將一組特征向量組織成聚類。
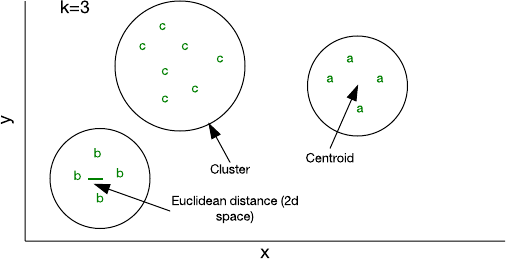
圖 4:在一個二維特征空間中的聚類
你可以使用少量代碼就能實現的最簡單的聚類算法是 k-均值(k-means)。其中,k 表示你為樣本分配的聚類的數量。你可以使用一個隨機特征向量來對一個聚類進行初始化,然后將其它樣本添加到其最近鄰的聚類(假定每個樣本都能表示一個特征向量,并且可以使用 Euclidean distance 來確定「距離」)。隨著你往一個聚類添加的樣本越來越多,其形心(centroid,即聚類的中心)就會重新計算。然后該算法會重新檢查一次樣本,以確保它們都在最近鄰的聚類中,最后直到沒有樣本需要改變所屬聚類。
盡管 k-均值聚類相對有效,但你必須事先確定 k 的大小。根據數據的不同,其它方法可能會更加有效,比如分層聚類(hierarchical clustering)或基于分布的聚類(distribution-based clustering)。
決策樹
決策樹和聚類很相近。決策樹是一種關于觀察(observation)的預測模型,可以得到一些結論。結論在決策樹上被表示成樹葉,而節點則是觀察分叉的決策點。決策樹來自決策樹學習算法,其中數據集會根據屬性值測試(attribute value tests)而被分成不同的子集,這個分割過程被稱為遞歸分區(recursive partitioning)。
考慮下圖中的示例。在這個數據集中,我可以基于三個因素觀察到某人是否有生產力。使用一個決策樹學習算法,我可以通過一個指標來識別屬性(其中一個例子是信息增益)。在這個例子中,心情(mood)是生產力的主要影響因素,所以我根據 Good Mood 一項是 Yes 或 No 而對這個數據集進行了分割。但是,在 Yes 這邊,還需要我根據其它兩個屬性再次對該數據集進行切分。表中不同的顏色對應右側中不同顏色的葉節點。
圖 5:一個簡單的數據集及其得到的決策樹
決策樹的一個重要性質在于它們的內在的組織能力,這能讓你輕松地(圖形化地)解釋你分類一個項的方式。流行的決策樹學習算法包括 C4.5 以及分類與回歸樹(Classification and Regression Tree)。
基于規則的系統
最早的基于規則和推理的系統是 Dendral,于 1965 年被開發出來,但直到 1970 年代,所謂的專家系統(expert systems)才開始大行其道。基于規則的系統會同時存有所需的知識的規則,并會使用一個推理系統(reasoning system)來得出結論。
基于規則的系統通常由一個規則集合、一個知識庫、一個推理引擎(使用前向或反向規則鏈)和一個用戶接口組成。下圖中,我使用了知識「蘇格拉底是人」、規則「如果是人,就會死」以及一個交互「誰會死?」

圖 6:基于規則的系統
基于規則的系統已經在語音識別、規劃和控制以及疾病識別等領域得到了應用。上世紀 90 年代人們開發的一個監控和診斷大壩穩定性的系統 Kaleidos 至今仍在使用。
機器學習
機器學習是人工智能和計算機科學的一個子領域,也有統計學和數學優化方面的根基。機器學習涵蓋了有監督學習和無監督學習領域的技術,可用于預測、分析和數據挖掘。機器學習不限于深度學習這一種。但在這一節,我會介紹幾種使得深度學習變得如此高效的算法。
圖 7:機器學習方法的時間線
反向傳播
神經網絡的強大力量源于其多層的結構。單層感知器的訓練是很直接的,但得到的網絡并不強大。那問題就來了:我們如何訓練多層網絡呢?這就是反向傳播的用武之地。
反向傳播是一種用于訓練多層神經網絡的算法。它的工作過程分為兩個階段。第一階段是將輸入傳播通過整個神經網絡直到最后一層(稱為前饋)。第二階段,該算法會計算一個誤差,然后從最后一層到第一層反向傳播該誤差(調整權重)。

圖 8:反向傳播示意圖
在訓練過程中,該網絡的中間層會自己進行組織,將輸入空間的部分映射到輸出空間。反向傳播,使用監督學習,可以識別出輸入到輸出映射的誤差,然后可以據此調整權重(使用一個學習率)來矯正這個誤差。反向傳播現在仍然是神經網絡學習的一個重要方面。隨著計算資源越來越快、越來越便宜,它還將繼續在更大和更密集的網絡中得到應用。
卷積神經網絡
卷積神經網絡(CNN)是受動物視覺皮層啟發的多層神經網絡。這種架構在包括圖像處理的很多應用中都有用。第一個 CNN 是由 Yann LeCun 創建的,當時 CNN 架構主要用于手寫字符識別任務,例如讀取郵政編碼。
LeNet CNN 由好幾層能夠分別實現特征提取和分類的神經網絡組成。圖像被分為多個可以被接受的區域,這些子區域進入到一個能夠從輸入圖像提取特征的卷積層。下一步就是池化,這個過程降低了卷積層提取到的特征的維度(通過下采樣的方法),同時保留了最重要的信息(通常通過最大池化的方法)。然后這個算法又執行另一次卷積和池化,池化之后便進入一個全連接的多層感知器。卷積神經網絡的最終輸出是一組能夠識別圖像特征的節點(在這個例子中,每個被識別的數字都是一個節點)。使用者可以通過反向傳播的方法來訓練網絡。
圖 9.LeNet 卷積神經網絡架構
對深層處理、卷積、池化以及全連接分類層的使用打開了神經網絡的各種新型應用的大門。除了圖像處理之外,卷積神經網絡已經被成功地應用在了視頻識別以及自然語言處理等多種任務中。卷積神經網絡也已經在 GPU 上被有效地實現,這極大地提升了卷積神經網絡的性能。
長短期記憶(LSTM)
記得前面反向傳播中的討論嗎?網絡是前饋式的訓練的。在這種架構中,我們將輸入送到網絡并且通過隱藏層將它們向前傳播到輸出層。但是,還存在其他的拓撲結構。我在這里要研究的一個架構允許節點之間形成直接的回路。這些神經網絡被稱為循環神經網絡(RNN),它們可以向前面的層或者同一層的后續節點饋送內容。這一特性使得這些網絡對時序數據而言是理想化的。
在 1997 年,一種叫做長短期記憶(LSTM)的特殊的循環網絡被發明了。LSTM 包含網絡中能夠長時間或者短時間記憶數值的記憶單元。
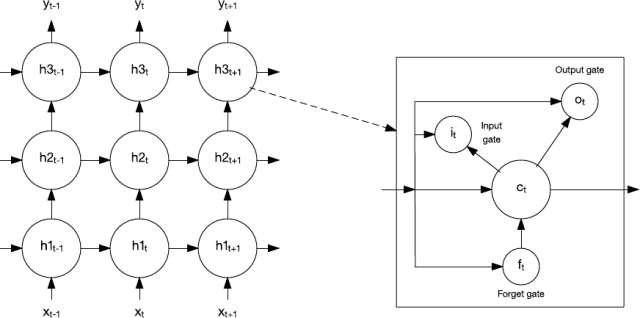
圖 10. 長短期記憶網絡和記憶單元
記憶單元包含了能夠控制信息流入或者流出該單元的一些門。輸入門(input gate)控制什么時候新的信息可以流入記憶單元。遺忘門(forget gate)控制一段信息在記憶單元中存留的時間。最后,輸出門(output gate)控制輸出何時使用記憶單元中包含的信息。記憶單元還包括控制每一個門的權重。訓練算法(通常是通過時間的反向傳播(backpropagation-through-time),反向傳播算法的一種變體)基于所得到的誤差來優化這些權重。
LSTM 已經被應用在語音識別、手寫識別、語音合成、圖像描述等各種任務中。下面我還會談到 LSTM。
深度學習
深度學習是一組相對新穎的方法集合,它們從根本上改變了機器學習。深度學習本身不是一種算法,但是它是一系列可以用無監督學習實現深度網絡的算法。這些網絡是非常深層的,所以需要新的計算方法來構建它們,例如 GPU,除此之外還有計算機集群。
本文目前已經介紹了兩種深度學習的算法:卷積神經網絡和長短期記憶網絡。這些算法已經被結合起來實現了一些令人驚訝的智能任務。如下圖所示,卷積神經網絡和長短期記憶已經被用來識別并用自然語言描述圖片或者視頻中的物體。
圖 11. 結合卷積神經網絡和長短期記憶來進行圖像描述
深度學習算法也已經被用在了人臉識別中,也能夠以 96% 的準確率來識別結核病,還被用在自動駕駛和其他復雜的問題中。
然而,盡管運用深度學習算法有著很多結果,但是仍然存在問題需要我們去解決。一個最近的將深度學習用于皮膚癌檢測的應用發現,這個算法比經過認證的皮膚科醫生具有更高的準確率。但是,醫生可以列舉出導致其診斷結果的因素,卻沒有辦法知道深度學習程序在分類的時候所用的因素。這被稱為深度學習的黑箱問題。
另一個被稱為 Deep Patient 的應用,在提供病人的病例時能夠成功地預測疾病。該應用被證明在疾病預測方面比醫生還做得好——即使是眾所周知的難以預測的精神分裂癥。所以,即便模型效果良好,也沒人能夠深入到這些大型神經網絡去找到原因。
認知計算
人工智能和機器學習充滿了生物啟示的案例。盡管早期的人工智能專注于建立模仿人腦的機器這一宏偉目標,而現在,是認知計算正在朝著這個目標邁進。
認知計算建立在神經網絡和深度學習之上,運用認知科學中的知識來構建能夠模擬人類思維過程的系統。然而,認知計算覆蓋了好多學科,例如機器學習、自然語言處理、視覺以及人機交互,而不僅僅是聚焦于某個單獨的技術。
認知學習的一個例子就是 IBM 的 Waston,它在 Jeopardy 上展示了當時最先進的問答交互。IBM 已經將其擴展在了一系列的 web 服務上了。這些服務提供了用于一些列應用的編程接口來構建強大的虛擬代理,這些接口有:視覺識別、語音文本轉換(語音識別)、文本語音轉換(語音合成)、語言理解和翻譯、以及對話引擎。
繼續前進
本文僅僅涵蓋了關于人工智能歷史以及最新的神經網絡和深度學習方法的一小部分。盡管人工智能和機器學習經歷了很多起起伏伏,但是像深度學習和認知計算這樣的新方法已經明顯地提升了這些學科的水平。雖然可能還無法實現一個具有意識的機器,但是今天確實有著能夠改善人類生活的人工智能系統。
-
人工智能
+關注
關注
1791文章
47206瀏覽量
238279 -
機器學習
+關注
關注
66文章
8408瀏覽量
132572
原文標題:IBM長文解讀人工智能、機器學習和認知計算
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
嵌入式和人工智能究竟是什么關系?
具身智能與機器學習的關系
人工智能、機器學習和深度學習存在什么區別






 工商網監
工商網監
評論