") B+樹索引如何對Mysql單表數(shù)據(jù)量造成影響
B+樹索引如何對Mysql單表數(shù)據(jù)量造成影響
Mysql 單表適合的最大數(shù)據(jù)量是多少?
我們說 Mysql 單表適合存儲的最大數(shù)據(jù)量,自然不是說能夠存儲的最大數(shù)據(jù)量,如果是說能夠存儲的最大量,那么,如果你使用自增 ID,最大就可以存儲 2^32 或 2^64 條記錄了,這是按自增 ID 的數(shù)據(jù)類型 int 或 bigint 來計算的;如果你不使用自增 id,且沒有 id 最大值的限制,如使用足夠長度的隨機字符串,那么能夠限制單表最大數(shù)據(jù)量的就只剩磁盤空間了。顯然我們不是在討論這個問題。
影響 Mysql 單表的最優(yōu)最大數(shù)量的一個重要因素其實是索引。
我們知道 Mysql 的主要存儲引擎 InnoDB 采用 B+樹結(jié)構(gòu)索引。(至于為什么 Mysql 選擇 b+樹而不是其他數(shù)據(jù)結(jié)構(gòu)來組織索引,不是本文討論的話題,之后的文章會講到。)那么 B+樹索引是如何影響 Mysql 單表數(shù)據(jù)量的呢?
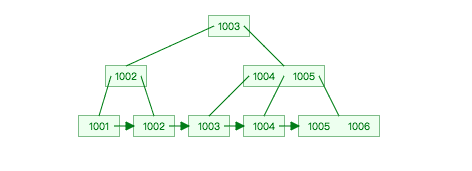
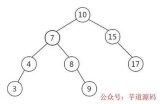
B+樹
一棵 B+樹如下所示:
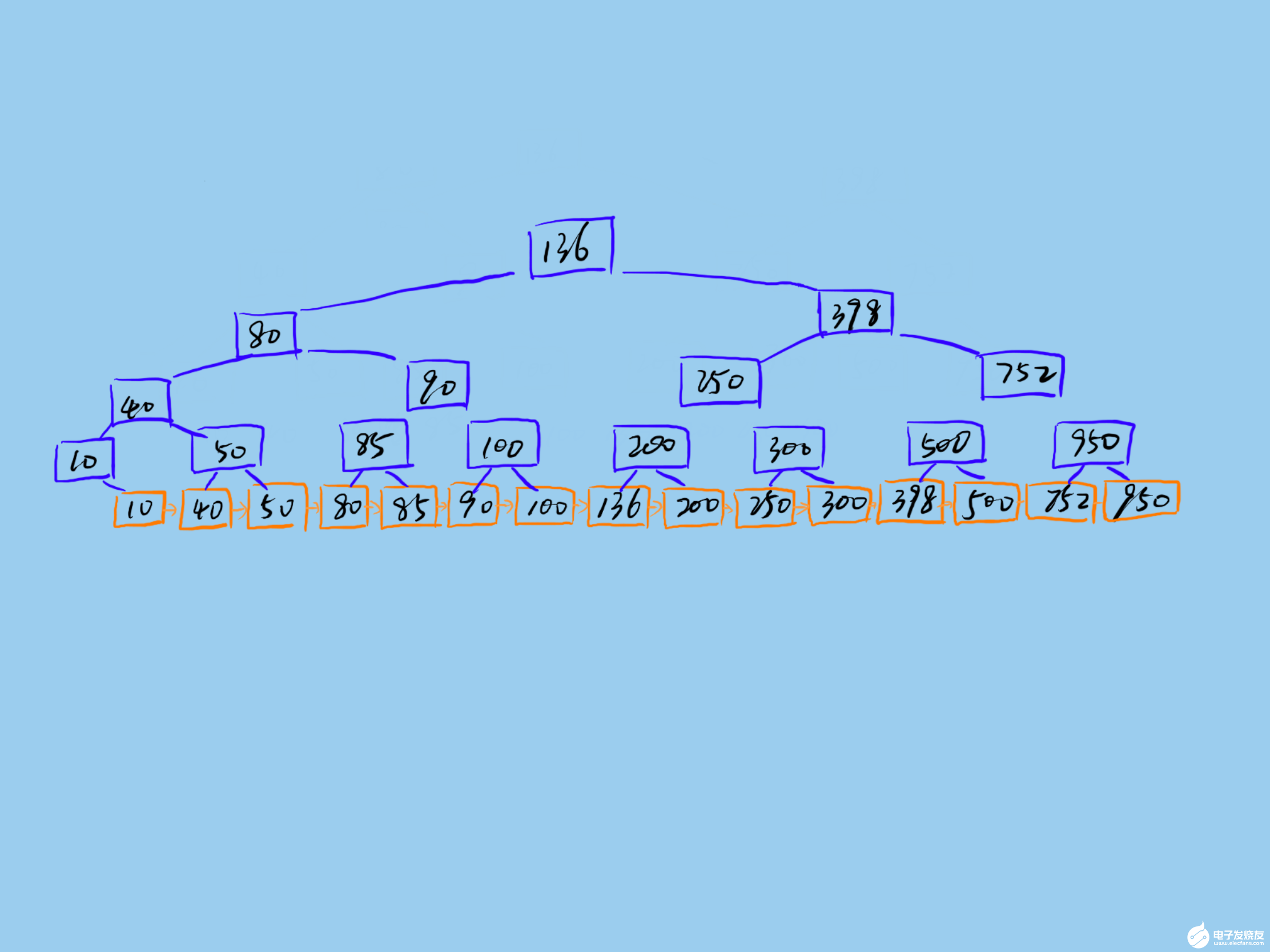
Mysql 的 B+樹索引存儲在磁盤上,Mysql 每次讀取磁盤 Page 的大小是 16KB,為了保證每次查詢的效率,需要保證每次查詢訪問磁盤的次數(shù),一般設(shè)計為 2-3 次磁盤訪問,再多性能將嚴重不足。Mysql B+樹索引的每個節(jié)點需要存儲一個指針(8Byte)和一個鍵值(8Byte)。因此計算16KB/(8B+8B)=1K 16KB 可以存儲 1K 個節(jié)點,3 次磁盤訪問(即 B+樹 3 的深度)可以存儲 1K _ 1K _ 1K 即 10 億數(shù)據(jù)。
如果查詢依賴非主鍵索引,那么還涉及二級索引。這樣數(shù)據(jù)量將更小。
拆分
分而治之——沒有什么問題不能通過拆分一次來解決,不行就拆多次。
Mysql 單表存儲的數(shù)據(jù)量有限。一個解決大數(shù)據(jù)量存儲的辦法就是分庫分表。說白了就是一個數(shù)據(jù)庫一張表放不下那么多數(shù)據(jù),那就分多個數(shù)據(jù)庫多張表存儲。
拆分可分為垂直拆分和水平拆分。
垂直拆分是按照不同的表(或者 Schema)來切分到不同的數(shù)據(jù)庫(主機)之上,水平拆分則是根據(jù)表中的數(shù)據(jù)的邏輯關(guān)系,將同一個表中的數(shù)據(jù)按照某種條件拆分到多臺數(shù)據(jù)庫(主機)上面或多張相同 Schema 的不同表中。
垂直拆分的最大特點就是規(guī)則簡單,實施也更為方便,尤其適合各業(yè)務(wù)之間的耦合度非常低,相互影響很小,業(yè)務(wù)邏輯非常清晰的系統(tǒng)。在這種系統(tǒng)中,可以很容易做到將不同業(yè)務(wù)模塊所使用的表分拆到不同的數(shù)據(jù)庫中。根據(jù)不同的表來進行拆分,對應(yīng)用程序的影響也更小,拆分規(guī)則也會比較簡單清晰。
水平拆分與垂直切分相比,相對來說稍微復(fù)雜一些。因為要將同一個表中的不同數(shù)據(jù)拆分到不同的數(shù)據(jù)庫中,對于應(yīng)用程序來說,拆分規(guī)則本身就較根據(jù)表名來拆分更為復(fù)雜,后期的數(shù)據(jù)維護也會更為復(fù)雜一些。
垂直拆分最直接的就是按領(lǐng)域拆分服務(wù),隔離領(lǐng)域數(shù)據(jù)庫。如此每個庫所承擔的數(shù)據(jù)壓力就減少了。
水平拆分就是將同一個 Schema 的數(shù)據(jù)拆分到不同的庫或不同的表中,這樣每個表的數(shù)據(jù)量也將減小,查詢效率將更高效。水平拆分就涉及到表的分片規(guī)則問題。
幾種典型的分片規(guī)則包括:
按照用戶 ID 求模,將數(shù)據(jù)分散到不同的數(shù)據(jù)庫,具有相同數(shù)據(jù)用戶的數(shù)據(jù)都被分散到一個庫中。
按照日期,將不同月甚至日的數(shù)據(jù)分散到不同的庫中。
按照某個特定的字段求摸,或者根據(jù)特定范圍段分散到不同的庫中。
實現(xiàn)
門面模式——沒有什么問題不能通過添加一個中間層來解決。
垂直拆分的一個方案就是在應(yīng)用層使用多個數(shù)據(jù)源,按業(yè)務(wù)訪問不同的數(shù)據(jù)源。另外更好方案其實就是微服務(wù)化。按不同的業(yè)務(wù)領(lǐng)域來拆分微服務(wù),明確領(lǐng)域邊界,隔離領(lǐng)域數(shù)據(jù)庫。這樣將對數(shù)據(jù)的存取內(nèi)聚到獨立的服務(wù)之中,對外提供統(tǒng)一的接口。在需要同時依賴多個服務(wù)時,我們可以通過添加門面應(yīng)用來組合底層服務(wù)的數(shù)據(jù),以提供更符合上層業(yè)務(wù)需求的接口,這些服務(wù)往往更接近真實的業(yè)務(wù)。而底層的服務(wù)則是更加內(nèi)聚的資源服務(wù)。
代理模式——沒有什么問題不能通過添加一個中間層來解決。
對于水平拆分應(yīng)該盡量屏蔽拆分帶來的數(shù)據(jù)訪問困惱,為了讓上層業(yè)務(wù)無需關(guān)心下層數(shù)據(jù)組織方式。水平拆分往往通過添加一個代理層來做這些事情,代理層對上提供虛擬表,這些虛擬表就像我們在單庫上設(shè)計的單表一樣;代理層對下解析和拆分執(zhí)行 sql,然后按相應(yīng)規(guī)則在不同的庫和表執(zhí)行相應(yīng)的 sql 請求,再合并數(shù)據(jù),并將合并后的結(jié)果返回給上層調(diào)用者。
一般代理方式分為如下兩種:
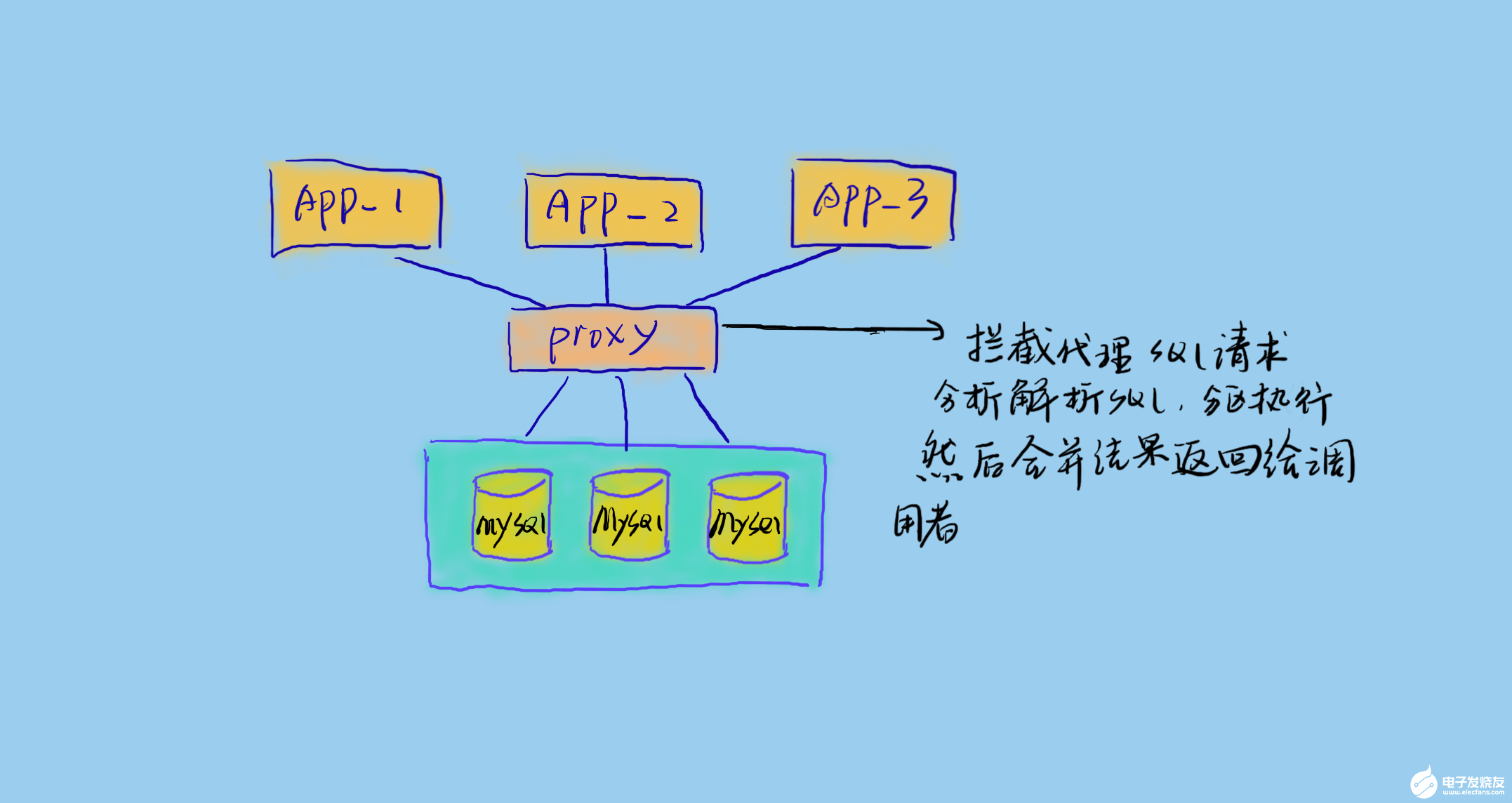
進程內(nèi)代理
進程內(nèi)代理即將代理層嵌入到業(yè)務(wù)服務(wù)內(nèi)部,攔截 sql 請求并做相應(yīng)的處理。這樣的好處是簡單,但是侵入性大,且不夠靈活。
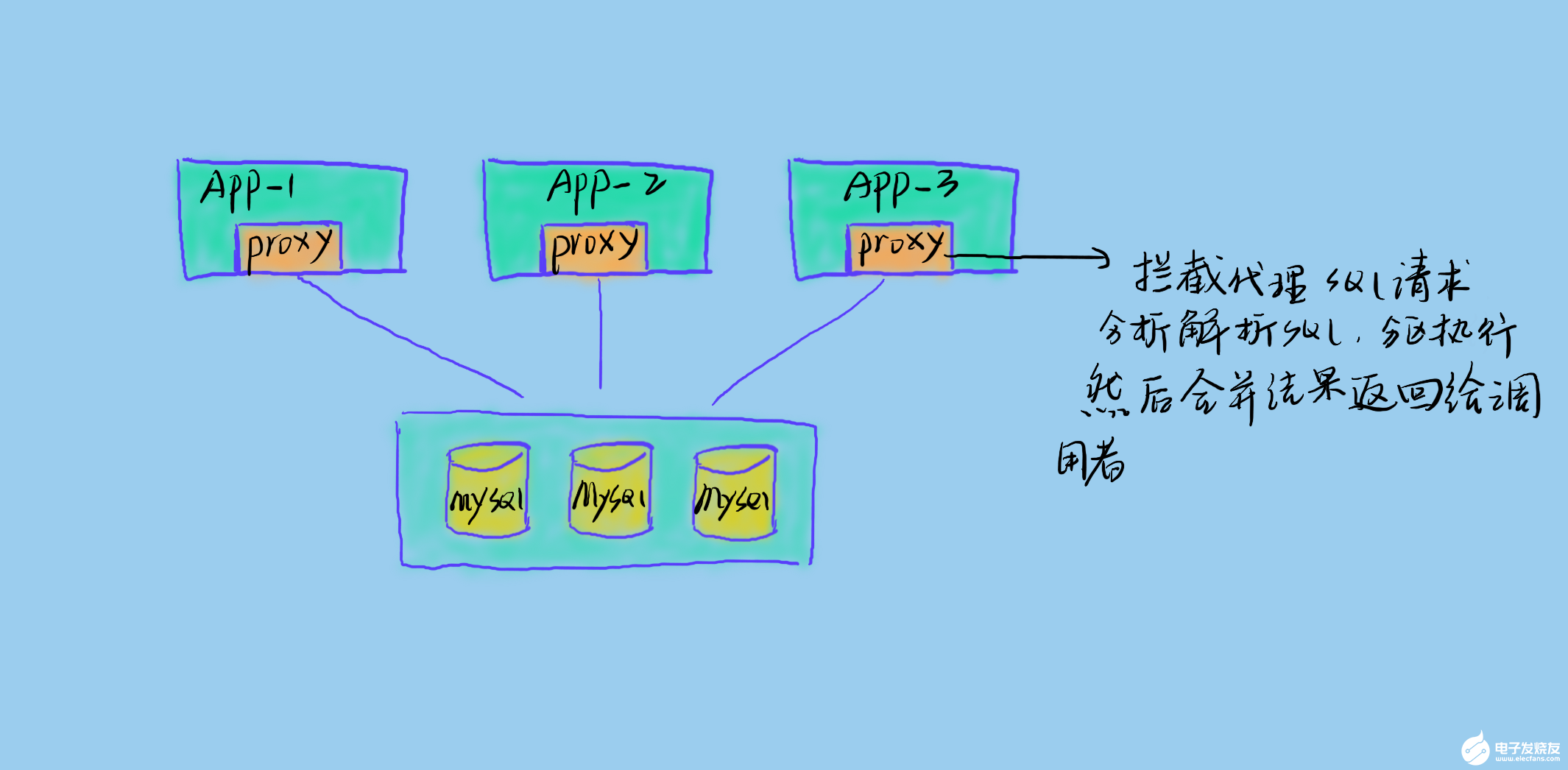
進程外代理
進程外代理即將代理獨立成服務(wù),代理真實業(yè)務(wù)服務(wù)和數(shù)據(jù)庫之間的請求。這樣是比較復(fù)雜的,需要高可用的代理服務(wù)架構(gòu)。但是這樣對業(yè)務(wù)的侵入性低,且易于升級擴展。
問題
分布式事務(wù)問題
什么是分布式事務(wù)?本地事務(wù)的定義就是一系列相關(guān)的數(shù)據(jù)庫操作完成后要滿足 ACID 四大特性,而分布式事務(wù)就是將同一進程的操作放到不同的微服務(wù)進程中,即不同微服務(wù)應(yīng)用進程的數(shù)據(jù)庫操作滿足事務(wù)要求,或者對不同數(shù)據(jù)庫的一系列操作需滿足事務(wù)要求。
這里就有兩個問題需要解決。一個是因為應(yīng)用的分布式造成的,一個是因為數(shù)據(jù)庫本身的分布式造成的。數(shù)據(jù)庫本身的分布式事務(wù)問題一般由數(shù)據(jù)庫自身解決,大多數(shù)分布式數(shù)據(jù)庫都可以做到一定的數(shù)據(jù)一致性保證,如 HBase 保證的強一致性,Cassandra 保證的最終一致性。
應(yīng)用數(shù)據(jù)的一致性事務(wù)方案我們也可以參考分布式數(shù)據(jù)庫的實現(xiàn)原理來實現(xiàn)。業(yè)界也有很多分布式事務(wù)的解決思路,如:
XA 方案
TCC 方案
本地消息表
可靠消息最終一致性方案
最大努力通知方案
多表 Join 問題
通過分析 Join sql,將 sql 拆分成獨立的查詢請求,然后分別執(zhí)行,并將結(jié)果合并計算返回給調(diào)用者。這個地方會涉及到很多執(zhí)行優(yōu)化的問題。
數(shù)據(jù)統(tǒng)計問題
當數(shù)據(jù)被分片到不同的數(shù)據(jù)庫或不同的表中時,要對數(shù)據(jù)做一些全局的或涉及大量數(shù)據(jù)的統(tǒng)計時便會遇到一些問題。如求 Max,Min,Sum 等聚合問題。如果統(tǒng)計的數(shù)據(jù)有一定的業(yè)務(wù)規(guī)則,如只會按用戶維度去統(tǒng)計,如統(tǒng)計某個用戶的訂單量,那么對訂單表的分片,其實可以采用按用戶 id 來分片,如此就可以解決這類統(tǒng)計問題。但是這種方案不通用。很多分片代理服務(wù)都需要將 sql 分片到不同的節(jié)點上去執(zhí)行,然后再合并結(jié)果返回。
ID 問題
使用分庫分表之后,就無法使用 Mysql 的表自增作為 id,因為不同庫和表的自增將出現(xiàn)沖突的 id。解決這個問題就需要引入分布式 id 生成技術(shù)。
責任編輯:gt
-
引擎
+關(guān)注
關(guān)注
1文章
361瀏覽量
22547 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8882瀏覽量
137406
發(fā)布評論請先 登錄
相關(guān)推薦
MySQL數(shù)據(jù)庫索引的底層是怎么實現(xiàn)的
基于B+樹的動態(tài)數(shù)據(jù)持有性證明方案

基于KD樹和R樹的多維索引結(jié)構(gòu)

MySQL索引使用原則
MySQL索引的使用問題
關(guān)于MySQL ORDER BY的詳解
掌握這幾種方法 你的接口查詢速度將飛速提升
對 B+ 樹與索引在 MySQL 中的認識
Mysql索引為什么使用B+樹?
MySQL高級進階:索引優(yōu)化
MySQL為什么選擇B+樹作為索引結(jié)構(gòu)?
索引是什么意思 優(yōu)缺點有哪些
MySQL單表數(shù)據(jù)量限制:為何2000萬行成為瓶頸?

一文了解MySQL索引機制






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論