") 基于增量K均值分段HMM的識(shí)別算法在微機(jī)器人控制系統(tǒng)中的應(yīng)用
基于增量K均值分段HMM的識(shí)別算法在微機(jī)器人控制系統(tǒng)中的應(yīng)用
引言
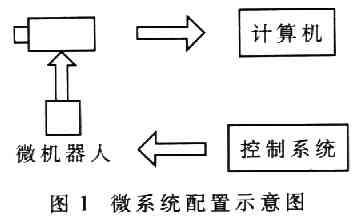
據(jù)統(tǒng)計(jì),人類日常生活中的溝通大約有75%左右是通過(guò)語(yǔ)言來(lái)完成的。語(yǔ)言作為人類特有的功能,不但是相互傳遞信息的主要手段,也是人們最理想的人機(jī)交互方式之一。在現(xiàn)代社會(huì)機(jī)器人這個(gè)詞語(yǔ)已經(jīng)不再新鮮。有些機(jī)器人已經(jīng)走進(jìn)了我們的生活,成為我們生活的組成部分。在下文我們要講的是基于毫米級(jí)全方位無(wú)回轉(zhuǎn)半徑移動(dòng)機(jī)器人課題。我們微系統(tǒng)配置示意圖如圖1所示。主要由主機(jī)Host(配有圖像采集卡)、兩個(gè)CCD攝像頭(其中一個(gè)為顯微攝像頭)、微移動(dòng)裝配平臺(tái)、微機(jī)器人本體和系統(tǒng)控制電路板等組成。計(jì)算機(jī)和攝像機(jī)組用于觀察微機(jī)器人的方位,控制系統(tǒng)控制微機(jī)器人的移動(dòng)。
與機(jī)器進(jìn)行語(yǔ)音交流,讓機(jī)器明白你說(shuō)什么,這是人們長(zhǎng)期以來(lái)夢(mèng)寐以求的事情。語(yǔ)音識(shí)別技術(shù)就是讓機(jī)器通過(guò)識(shí)別和理解過(guò)程把語(yǔ)音信號(hào)轉(zhuǎn)變?yōu)橄鄳?yīng)的文本或命令的高技術(shù)。語(yǔ)音識(shí)別技術(shù)主要包括特征提取技術(shù)、模式匹配準(zhǔn)則及模型訓(xùn)練技術(shù)三個(gè)方面。 本文在系統(tǒng)控制電路中嵌入式實(shí)現(xiàn)語(yǔ)音識(shí)別算法,通過(guò)語(yǔ)音控制微機(jī)器人。也就是說(shuō)可以通過(guò)你的話微型機(jī)器人做出相應(yīng)的動(dòng)作。
微機(jī)器人控制系統(tǒng)的資源有限,控制方法比較復(fù)雜,并且需要有較高人的實(shí)時(shí)性,因此本文采用的語(yǔ)音識(shí)別算法必須簡(jiǎn)單、識(shí)別率高、占用系統(tǒng)資源少。畢竟微型機(jī)器人里面能放的東西有限,放多了東西雖然提高了語(yǔ)音識(shí)別率或者工作效率,但是也加大了微型機(jī)器人的體積,說(shuō)不定就不能做有些工作。
隱馬爾可夫模型(Hidden Markov Model,HMM)作為一種統(tǒng)計(jì)分析模型,創(chuàng)立于20世紀(jì)70年代。80年代得到了傳播和發(fā)展,成為信號(hào)處理的一個(gè)重要方向,現(xiàn)已成功地用于語(yǔ)音識(shí)別,行為識(shí)別,文字識(shí)別以及故障診斷等領(lǐng)域。HMM(隱馬爾可夫模型)的適應(yīng)性強(qiáng)、識(shí)別率高,是當(dāng)前語(yǔ)音識(shí)別的主流算法。使用基于HMM非特定人的語(yǔ)音識(shí)別算法雖然借助模板匹配減小了識(shí)別所需的資源,但是前期的模板儲(chǔ)存工作需要大量的計(jì)算和存儲(chǔ)空間,因此移植到嵌入式系統(tǒng)還有一定的難度,所以很多嵌入式應(yīng)用平臺(tái)的訓(xùn)練部分仍在PC機(jī)上實(shí)現(xiàn)。
為了使訓(xùn)練和識(shí)別都在嵌入式系統(tǒng)上實(shí)現(xiàn),本文給出了一種基于K均值分段HMM模型的實(shí)時(shí)學(xué)習(xí)語(yǔ)音識(shí)別算法,不僅解決了上述問(wèn)題,而且做到了智能化,實(shí)現(xiàn)了真正意義上的自動(dòng)語(yǔ)音識(shí)別。
1 增量K均值分段HMM的算法及實(shí)現(xiàn)
由于語(yǔ)音識(shí)別過(guò)程中非特定的因素較多,為了提高識(shí)別的準(zhǔn)確率,針對(duì)本系統(tǒng)的特點(diǎn),采用動(dòng)態(tài)改變識(shí)別參數(shù)的方法提高系統(tǒng)的識(shí)別率。
語(yǔ)音識(shí)別方法主要是模式匹配法。 在訓(xùn)練階段,用戶將詞匯表中的每一詞依次說(shuō)一遍,并且將其特征矢量作為模板存入模板庫(kù)。 在識(shí)別階段,將輸入語(yǔ)音的特征矢量依次與模板庫(kù)中的每個(gè)模板進(jìn)行相似度比較,將相似度最高者作為識(shí)別結(jié)果輸出。
訓(xùn)練算法是HMM中運(yùn)算量最大、最復(fù)雜的部分,訓(xùn)練算法的輸出是即將存儲(chǔ)的模型。目前的語(yǔ)音識(shí)別系統(tǒng)大都使用貝斯曼參數(shù)的HMM模型,采取最大似然度算法。這些算法通常是批處理函數(shù),所有的訓(xùn)練數(shù)據(jù)要在識(shí)別之前訓(xùn)練好并存儲(chǔ)。因此很多嵌入式系統(tǒng)因?yàn)橘Y源有限不能達(dá)到高識(shí)別率和實(shí)時(shí)輸出。
本系統(tǒng)采用了自適應(yīng)增量K均值分段算法。在每次輸入新的語(yǔ)句時(shí)都連續(xù)地計(jì)算而不對(duì)前面的數(shù)據(jù)進(jìn)行存儲(chǔ),這可以節(jié)約大量的時(shí)間和成本。輸入語(yǔ)句時(shí)由系統(tǒng)的識(shí)別結(jié)果判斷輸入語(yǔ)句的序號(hào),并對(duì)此語(yǔ)句的參數(shù)動(dòng)態(tài)地修改,真正做到了實(shí)時(shí)學(xué)習(xí)。
K均值分段算法是基于最佳狀態(tài)序列的理論,因此可以采用Viterbi算法得到最佳狀態(tài)序列,從而方便地在線修改系統(tǒng)參數(shù),使訓(xùn)練的速度大大提高。
為了達(dá)到本系統(tǒng)所需要的功能,對(duì)通常的K均值算法作了一定的改進(jìn)。在系統(tǒng)無(wú)人監(jiān)管的情況下,Viterbi解碼計(jì)算出最大相似度的語(yǔ)音模型,根據(jù)這個(gè)假設(shè)計(jì)算分段K均值算法的輸入?yún)?shù),對(duì)此模型進(jìn)行參數(shù)重估。首先按照HMM模型的狀態(tài)數(shù)進(jìn)行等間隔分段,每個(gè)間隔的數(shù)據(jù)段作為某一狀態(tài)的訓(xùn)練數(shù)據(jù),計(jì)算模型的初始參數(shù)λ=f(a,A,B)。采用Viterbi的最佳狀態(tài)序列搜索,得到當(dāng)前最佳狀態(tài)序列參數(shù)和重估參數(shù)θ,其中概率密度函數(shù)P(X,S|θ)代替了最大似然度算法中的P(X,θ),在不同的馬爾科夫狀態(tài)和重估之間跳轉(zhuǎn)。基于K均值算法的參數(shù)重估流程如下:

為了使參數(shù)能更快地收斂,在每幀觀察語(yǔ)音最佳狀態(tài)序列的計(jì)算結(jié)束后,加入一個(gè)重估過(guò)程,以求更快地響應(yīng)速度。

可以看到,增量K均值算法的特點(diǎn)為:在每次計(jì)算完觀察值最佳狀態(tài)序列后,插入一個(gè)重估過(guò)程。隨時(shí)調(diào)整參數(shù)以識(shí)別下一個(gè)句子。
由于采用混合高斯密度函數(shù)作為輸出概率分布可以達(dá)到較好的識(shí)別效果,因此本文采用M的混合度對(duì)數(shù)據(jù)進(jìn)行訓(xùn)練。
對(duì)λ重估,并比較收斂性,最終得到HMM模型參數(shù)訓(xùn)練結(jié)果。
可見(jiàn),用K均值法在線修改時(shí),一次數(shù)據(jù)輸入會(huì)有多次重估過(guò)程,這使系統(tǒng)使用最近的模型估計(jì)后續(xù)語(yǔ)句的最佳狀態(tài)序列成為可能。但是對(duì)于在線修改參數(shù)要求,快速收斂是很重要的。為了得到更好的Viterbi序列,最佳狀態(tài)序列使用了漸增的算法模型,即快速收斂算法。
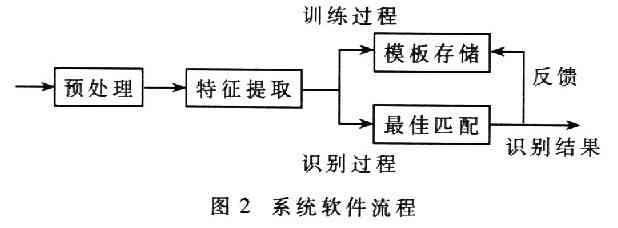
語(yǔ)音識(shí)別的具體實(shí)現(xiàn)過(guò)程為:數(shù)字語(yǔ)音信號(hào)通過(guò)預(yù)處理和特征向量的提取,用戶通過(guò)按鍵選擇學(xué)習(xí)或者識(shí)別模式;如果程序進(jìn)入訓(xùn)練過(guò)程,即用戶選擇進(jìn)行新詞條的學(xué)習(xí),則用分段K均值法對(duì)數(shù)據(jù)進(jìn)行訓(xùn)練得到模板;如果進(jìn)入識(shí)別模式,則從Flash中調(diào)出聲音特征向量,進(jìn)行HMM算法識(shí)別。在識(shí)別出結(jié)果后,立即將識(shí)別結(jié)果作為正確結(jié)果與前一次的狀態(tài)做比較,得到本詞條更好的模板,同時(shí)通過(guò)LED數(shù)字顯示和語(yǔ)音輸出結(jié)果。系統(tǒng)軟件流程如圖2所示。
對(duì)采集到的語(yǔ)音進(jìn)行16kHz、12位量化,并對(duì)數(shù)字語(yǔ)音信號(hào)進(jìn)行預(yù)加重:

L選擇為320個(gè)點(diǎn),用短時(shí)平均能量和平均過(guò)零率判斷起始點(diǎn),去除不必要的信息。
對(duì)數(shù)據(jù)進(jìn)行FFT運(yùn)算,得到能量譜,通過(guò)24通道的帶通濾波輸出X(k),然后再通過(guò)DCT運(yùn)算,提取12個(gè)MFCC系數(shù)和一階二階對(duì)數(shù)能量,提取38個(gè)參數(shù)可以使系統(tǒng)識(shí)別率得到提高。
為了進(jìn)行連接詞識(shí)別,需要由訓(xùn)練數(shù)據(jù)得到單個(gè)詞條的模型。方法為:首先從連接詞中分離出每個(gè)孤立的詞條,然后再進(jìn)行孤立詞條的模型訓(xùn)練。對(duì)于本系統(tǒng)不定長(zhǎng)詞條的情況,每個(gè)詞條需要有一套初始的模型參數(shù),然后按照分層構(gòu)筑的HMM算法將所有詞串分成孤立的詞條。對(duì)每個(gè)詞條進(jìn)行參數(shù)的重估,判斷是否收斂。如果差異小于某個(gè)域值就判斷為收斂;否則將得到的參數(shù)作為新的初始參數(shù)再進(jìn)行重估,直到收斂。
當(dāng)然本系統(tǒng)還要對(duì)語(yǔ)音進(jìn)行前端處理工作。主要是指在特征提取之前,先對(duì)原始語(yǔ)音進(jìn)行處理,部分消除噪聲和不同說(shuō)話人帶來(lái)的影響,使處理后的信號(hào)更能反映語(yǔ)音的本質(zhì)特征。最常用的前端處理有端點(diǎn)檢測(cè)和語(yǔ)音增強(qiáng)。端點(diǎn)檢測(cè)是指在語(yǔ)音信號(hào)中將語(yǔ)音和非語(yǔ)音信號(hào)時(shí)段區(qū)分開(kāi)來(lái),準(zhǔn)確地確定出語(yǔ)音信號(hào)的起始點(diǎn)。經(jīng)過(guò)端點(diǎn)檢測(cè)后,后續(xù)處理就可以只對(duì)語(yǔ)音信號(hào)進(jìn)行,這對(duì)提高模型的精確度和識(shí)別正確率有重要作用。語(yǔ)音增強(qiáng)的主要任務(wù)就是消除環(huán)境噪聲對(duì)語(yǔ)音的影響。目前通用的方法是采用維納濾波,該方法在噪聲較大的情況下效果好于其它濾波器。
2 實(shí)驗(yàn)結(jié)果
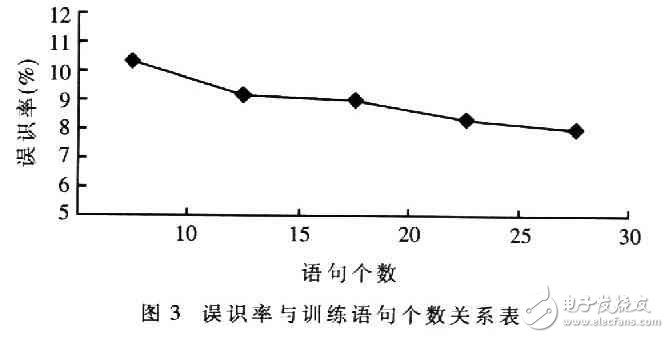
實(shí)驗(yàn)采用30個(gè)人(15男,15女)的聲音模型進(jìn)行識(shí)別。首先由10人(5男,5女)對(duì)5個(gè)命令詞(前進(jìn)、后退、左移、右移、快速)分別進(jìn)行初始數(shù)據(jù)訓(xùn)練,每人每詞訓(xùn)練10次,得到訓(xùn)練模板。然后再由這30人隨機(jī)進(jìn)行非特定人語(yǔ)音識(shí)別。采用6狀態(tài)的HMM模型,高斯混合度選為14,得到圖3的實(shí)驗(yàn)結(jié)果。
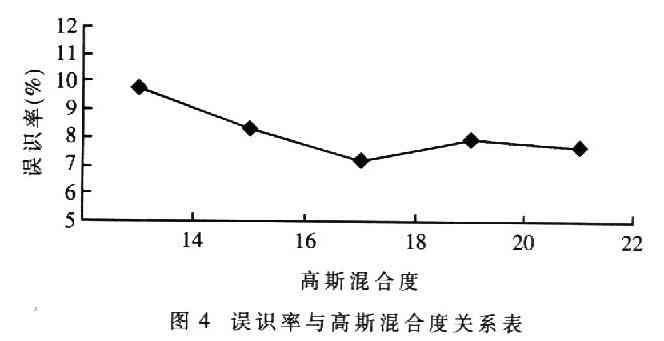
逐步增加高斯混合度數(shù)目,可以得到圖4的實(shí)驗(yàn)結(jié)果。可見(jiàn)高斯混合度在18的時(shí)候達(dá)到較好的識(shí)別效果,混合度太高識(shí)別率反而會(huì)有所下降,這是由于嵌入式系統(tǒng)的資源有限,運(yùn)算復(fù)雜度的增長(zhǎng)超過(guò)了嵌入式設(shè)備的限制所造成的。
為了使微機(jī)器人能夠正確地執(zhí)行人的聲音指令,本文將語(yǔ)音識(shí)別的過(guò)程嵌入微機(jī)器人的控制系統(tǒng)中,根據(jù)微機(jī)器人控制系統(tǒng)資源有限、對(duì)實(shí)時(shí)性要求高的特點(diǎn),使用增量K均值分段HMM的算法,簡(jiǎn)化計(jì)算節(jié)省了所需的硬件資源,實(shí)現(xiàn)了實(shí)時(shí)學(xué)習(xí)的語(yǔ)音識(shí)別,能方便地對(duì)微機(jī)器人進(jìn)行控制。
本系統(tǒng)的識(shí)別率達(dá)到了較高的標(biāo)準(zhǔn),又由于加入了智能化的用戶選擇部分,用戶可隨時(shí)選擇學(xué)習(xí)新的語(yǔ)句,使其有更廣闊的應(yīng)用前景。
結(jié)論
本文介紹了一種應(yīng)用于微機(jī)器人控制平臺(tái)的語(yǔ)音識(shí)別算法,可實(shí)現(xiàn)簡(jiǎn)單命令詞語(yǔ)的識(shí)別,控制微機(jī)器人的移動(dòng)。利用K均值分段法,在每次計(jì)算完觀察值最佳狀態(tài)序列后,插入一個(gè)重估過(guò)程,隨時(shí)調(diào)整參數(shù)以識(shí)別下一個(gè)句子。實(shí)驗(yàn)結(jié)果表明,這種實(shí)時(shí)學(xué)習(xí)的語(yǔ)音識(shí)別算法適合嵌入式應(yīng)用。當(dāng)然由于嵌入式平臺(tái)受到處理速度、存儲(chǔ)空間的限制,所以能夠?qū)ξC(jī)器人發(fā)出的指令十分有限,識(shí)別率還有待提高。因此,研究語(yǔ)音識(shí)別算法,比較各種算法的優(yōu)缺點(diǎn),進(jìn)而在嵌入式微機(jī)器人控制系統(tǒng)上實(shí)現(xiàn)大詞匯量非特定人的語(yǔ)音識(shí)別,實(shí)現(xiàn)真正意義上的人機(jī)交流是今后進(jìn)一步的工作。相信在科學(xué)技術(shù)的發(fā)展迅速社會(huì)背景下,這個(gè)語(yǔ)音控制微型機(jī)器人的技術(shù)會(huì)逐漸發(fā)展起來(lái),最終達(dá)到人機(jī)交流與人人交流一般。讓微型機(jī)器人的應(yīng)用更加廣泛。
-
控制系統(tǒng)
+關(guān)注
關(guān)注
41文章
6633瀏覽量
110680 -
機(jī)器人
+關(guān)注
關(guān)注
211文章
28496瀏覽量
207449 -
攝像頭
+關(guān)注
關(guān)注
60文章
4851瀏覽量
95885
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】2.具身智能機(jī)器人的基礎(chǔ)模塊
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】1.初步理解具身智能
《具身智能機(jī)器人系統(tǒng)》第1-6章閱讀心得之具身智能機(jī)器人系統(tǒng)背景知識(shí)與基礎(chǔ)模塊
編碼器在機(jī)器人技術(shù)中的應(yīng)用 編碼器在傳感器系統(tǒng)中的作用
如何使用PLC控制機(jī)器人
簡(jiǎn)述工業(yè)機(jī)器人控制系統(tǒng)的特點(diǎn)
機(jī)器人控制系統(tǒng)的基本單元有哪些
機(jī)器人控制系統(tǒng)按控制方法可哪些種類
工業(yè)機(jī)器人電氣控制系統(tǒng)的體系結(jié)構(gòu)主要有哪些
工業(yè)機(jī)器人控制系統(tǒng)的基本組成有哪些
工業(yè)機(jī)器人控制系統(tǒng)的主要功能
簡(jiǎn)述機(jī)器人控制系統(tǒng)的組成
基于FPGA EtherCAT的六自由度機(jī)器人視覺(jué)伺服控制設(shè)計(jì)
基于飛凌嵌入式RK3568J核心板的工業(yè)機(jī)器人控制器應(yīng)用方案
淺談海康機(jī)器人控制系統(tǒng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論