 OpenEM的應用原理、使用效率和局限的研究
OpenEM的應用原理、使用效率和局限的研究
1、OpenEM 簡介
OpenEM 的全稱是 Open Event Machine。它是 TI 開發的可應用于 Keystone 多核 DSP 的multicore runtime system library。OpenEM 的目的是在多核上有效的調度,分發任務,實現動態的負載平衡。基于 OpenEM,用戶可以很容易的把原來的單核應用移植到 Keystone 多核芯片。需要注意的是 OpenEM 目前只能把任務調度分發到同一個 DSP 的多個核上,不能跨 DSP 調度分發。 OpenEM不依賴于 BIOS。它可以在芯片上裸跑,代碼精簡,效率高。而且,OpenEM不同于業界已經有 OpenMP 和 OpenCL 等開放式的 multi-core runtime systems。它是針對嵌入式系統的設計,更能滿足嵌入式設計的實時性要求。TI 的 keystone 架構多核芯片中有 Multicore Navigator。它由 Queue Manager(簡稱為 QMSS)和一系列 Packet DMA engine 構成。OpenEM就是基于這套硬件系統構建的。例如,OpenEM 的 scheduler 是運行在 QMSS 的 PDSP(QMSS內部的 RISC 處理器)上的。OpenEM的 preload 功能是通過 QMSS 的 packet DMA 實現的。熟悉QMSS 的編程對學習 OpenEM 很有幫助。OpenEM 是 MCSDK 的一個組件。它還在不斷的發展改進中。本文對 OpenEM 的介紹以及演示用例都是基于 BIOS MCSDK 2.01.02 的 OpenEM 1.0.0.2。
1.1 OpenEM 的軟件對象
下面通過列表和圖示介紹了 OpenEM的主要軟件對象。表 1 是 OpenEM 的主要軟件對象的列表。
需要注意的是,本文介紹的 OpenEM 的運行模式是:Scheduler 運行在 PDSP,Dispatcher 是“run to completion ”模式。
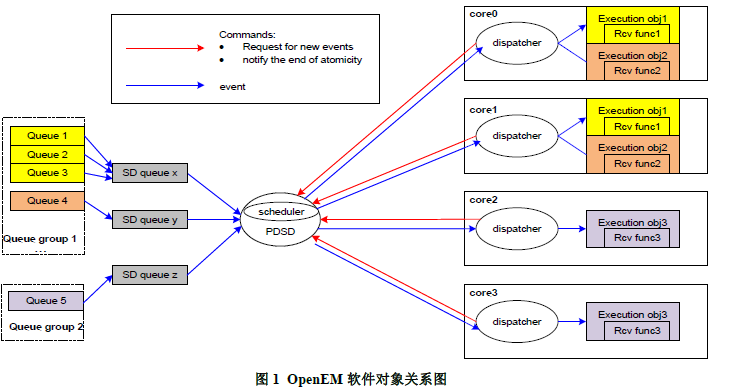
圖 1 是一個軟件對象關系圖,顯示出了表 1 中列舉的軟件對象。定義了 2 個 queue group,5 個queue 和 3 個 execution object。Queue group1 的 core mask 對應核 0 和 1。所以來自 queue1,2,3,4 的 event 只能在核 0 和核 1 上執行,因為這些 queue 屬于 queue group1。Queue group2 的 core mask 對應核 2 和 3。所以來自 queue5 的 event 只能在核 2 和核 3 上執行,因為queue5 屬于 queue group2。execution object 1 和 queue 1,2,3 映射關聯。execution object 2 和queue 4 映射關聯。execution object 3 和 queue 5 映射關聯。圖中的藍線表示了 event 的行徑,紅線表示 command 的行徑。圖中的 SD queue 是 hardware queue,它不是一個軟件對象而是OpenEM內部的組件。
1.2 OpenEM 的兩個重要概念
OpenEM中有兩個容易混淆的重要概念:prefetch 和 preload。
? Prefetch 是指每個 DSP 核向 scheduler 發命令,告訴 scheduler“本核已經空閑了,可以分配新的工作給本核了”。只有收到一個核的 prefetch 命令,scheduler 才會調度新的 event 給這個核。如果 DSP 核不發出 prefetch 命令,它就不會被分派任務。這是 OpenEM 的 scheduler的基本調度原則。
? Preload 和 event 的屬性有關。通常,event 的數據是位于 DDR 的。如果 DSP 核直接訪問DDR 效率會比較低。所以,OpenEM 可以把 event 的數據通過 QMSS 的 packet DMA 搬到DSP 核的 local L2。這個搬移的過程就是 preload。每個 event 的數據是否做 preload 是可配的。每個 event 在創建的時候都可以指定一個 preload 屬性。Event 的 preload 屬性可以是:
– Preload disable, 即不做預搬移
– Preload up to sizeA,即做預搬移,但是最多只搬 sizeA bytes
– Preload up to sizeB,即做預搬移,但是最多只搬 sizeB bytes
– Preload up to sizeC,即做預搬移,但是最多只搬 sizeC bytes
– 其中 SizeA,SizeB 和 SizeC 是常數,在 OpenEM 初始化的時候可以配置。
1. 3 OpenEM 的常用 API cycle 數
OpenEM的附帶開銷是應用最關注特性之一。所以我們實測了 OpenEM 常用 API 的 cycle 數如表2。需要注意的是:由于 OpenEM會負責 cache 一致性的維護,而有些 API 的處理過程中含有cache 一致性的維護操作。所以這些 API 的調用 cycle 數很大程度上取決于它對多大的數據緩沖區做了 cache 一致性的維護。本文測試這些 cycle 的場景使用的數據緩沖區的大小是是 4096 words(32bit)。
2、基于 OpenEM 的大矩陣乘實現
大矩陣相乘的目的是計算 X*Y = Z
矩陣 X 是(100 × 2048 )的浮點實數矩陣。
矩陣 Y 是(2048 × 2048 )的浮點實數矩陣。
矩陣 Z 是(100 × 2048 )的浮點實數矩陣。
由于矩陣 Y 的數據量很大,所以在多核 DSP 上可以把它拆分成多個子塊,交給多個 DSP 核并行計算。如圖 2 所示。
2.1 基于 OpenEM 的大矩陣乘方案設計
2.1.1 Memory 使用
Shannon DSP (6678)的內存系統包括片內的 LL2(local L2)和 SL2(shared L2)。加上片外的 DDR。LL2 的 size 是 512 Kbytes,每個核有一份 LL2。 SL2 的 size 是 4Mbytes,8 個核共享 SL2。DDR size 和硬件板卡設計有關,一般在 1G bytes 以上。 C66x 核對 LL2 的訪問效率最高,對 SL2 的訪問效率稍差,對 DDR 的訪問效率最低。基于多種存儲區間的不同特性,我們對數據存儲位置按如下規劃(參見圖 3):
– 矩陣 X 的 size 是 800 Kbytes,存儲是 shared L2
– 矩陣 Y 的 size 是 16 Mbytes,存儲是 DDR
– 矩陣 Z 的 size 是 800 Kbytes,存儲是 shared L2
雖然矩陣 Y 存儲在 DDR,但是我們啟用了 OpenEM 的 preload 功能。Preload 就是通過 QMSS 的 packet DMA 把待處理的 event 數據(通常位于 DDR)搬到被調度 core 的 LL2。所以 DSP 核運行的時候不直接從 DDR 取數。這保證了 DSP 核的數據訪問效率。
2.1.2 處理流程
OpenEM中要有一個 DSP 核作為主核,其他核就是從核,主核要完成的工作較多。本文的演示用例中,核 0 是主核,核 1~7 是從核。主從核的分工差異如圖 4:
1. 初始化 QMSS 和 free pool。
2. OpenEM 的 global 初始化和 local 初始化。global 初始化是主核執行。local 初始化是每個核各自執行。Local 初始化要等 global 初始化完成才能開始。所以,中間需要加一個barrier。Barrier 可以理解成一個同步點,所有 DSP 核在這個點完成一次同步再繼續向下執行。本演示用例的 Barrier 是通過共享內存的軟件信號量實現的。
3. 主核構造生產者/消費者場景并產生待處理的 event。生產者在 OpenEM 中不是一個軟件對象。我們可以把產生 event 并發送到 queue 的函數認為是生產者。消費者就是 execution object,溝通生產者和消費者的管道就是 queue。構造生產者/消費者場景就是創建execution object 和 queue 并且把它們關聯起來。
4. 主核和從核進入 event 處理的過程。
5. 主核檢測到所有 event 都處理完成后為每個 DSP 核(包括它自己)產一個 exit job。
6. 主核和從核處理 exit job。從核直接調用 exit(0)退出。主核先做結果驗證然后調用 exit(0)退出。
本文演示用例實現的幾個特點是:
? OpenEM 的 free pool 是由用戶初始化的。在初始化 free pool 的時候 event 描述符不指向數據緩沖區。等分配了一個 event 的時候再在這個 event 對應的描述符上掛數據緩沖區。這樣可以避免不必要的數據拷貝(從 global buffer 拷貝到 event buffer)。
? 主核通過查詢 free pool 中的 event 個數是否恢復回初始值來判斷是否所有“矩陣乘 event”都處理。因為:
– Free pool 在初始化以后有 N 個 free event,
– 從中分配了若干個 event 后,free event 就減少了相應的個數,
– 每個 core 每處理完一個 event 就把這個 event 回收到 free pool,free pool 的 event 個數就加一。當 free pool 的 event 個數恢復回 N,就說明所有 event 都處理完了。
2.2 基于 OpenEM 的大矩陣乘實現
在初始化 OpenEM之前首先要做 multicore Navi
gator 的初始化。包括:PDSP firmware 的download, Link RAM 的初始化, Memory region 的初始化還有 free pool (也就是 free descriptorqueue)的初始化。這不屬于本文介紹的范疇,本文直接介紹 OpenEM的初始化。
2.2.1 OpenEM 的 Global 初始化
OpenEM的 global 初始化通過調用 API 函數 ti_em_init_global()完成的。這個 API 的入參是下面所示的結構體。其中所列的參數是本文的演示用例使用的配置參數。本文針對每個參數的作用做了注釋。了解了參數了含義,就能了解 OpenEM 的 global 初始化的大致做了些什么。
注釋:
1. OpenEM要使用 hardware queue 資源。hw_queue_base_idx 用來指定 OpenEM 從哪個hardware queue 開始可用。
2. OpenEM 的少量操作需要多 DSP 核訪問共享的數據結構。是通過 hardware semaphore 實現多核lock/unclock 的。所以通過 hw_sem_idx 告訴 OpenEM該使用哪一個 hardware semaphore。
3. 指定 preload 使用的 QMSS packet DMA 的通道的起始索引。QMSS packet DMA 有 32 個 RX/TX channel。在 OpenEM 中,每個 DSP core 要占用一個 TX/RX channel。
4. 指定 preload 使用的 QMSS Tx queues 的起始索引。要和 dma_idx 對應起來。QMSS 有 32 個 TX queue,索引是 800~831。對應 QMSS packet DMA 的 TX channel 0~31。所以,如果前面配置的 dma_idx 是 0,那么這里配置的 dma_queue_base_idx 應該是 800。
5. 指定 OpenEM local free pool 對應的 free queue index。Local free pool 是和 preload 相關的。local free pool 在物理上是一個 free descriptor queue。里面存儲著 2 個 host 描述符。每個描述符對應一個 local L2 buffer。如果發生 preload,packet DMA 就從 free descriptor queue pop 描述符,然后把數據傳到描述符指向的 local L2 buffer。每個 DSP 核有一個 local free pool。例如,在我們的演示用例中 core0~7 對應的 free descriptor queue 索引是 2050~2057。
6. 指定 OpenEM global free pool 的個數。每個 global free pool 包括 4 個初始化參數,例如{ globalFreePoolFdqIdx, TI_EM_COH_MODE_ON,TI_EM_BUF_MODE_GLOBAL_TIGHT,0}。參數 1是這個 global free pool 對應的 free queue index。接下來幾項是這個 pool 中的 buffer 的屬性。Global free pool 是用來從中分配 free event 的。調用 em_alloc()的入參之一就是 free pool index。
7. 配置 preload 門限,參見本文 1.2 節的敘述。
2.2.2 創建生產者/消費者場景
前面介紹過,在 OpenEM 中,消費者就是 execution object,溝通生產者和消費者的管道就是queue。本小節介紹怎樣創建 execution object 和 queue 以及怎樣把它們關聯起來。 關于怎樣產生 event,本文在下一小節描述。OpenEM 有下列 API 供應用調用:
? 調用 em_eo_create()可以創建 execution object
? 調用 em_queue_create()可以創建 queue
? 調用 em_eo_add_queue()可以把 queue 和 execution object 映射起來
本演示用例通過參數配置表列出 execution object, queue group object 和 queue object 的參數,然后通過解析函數解析配置表再調用 OpenEM的 API,這樣各個軟件對象的參數在配置表中一目了然,代碼的可讀性較好。圖 5 是本演示用例的映射關系。
需要注意的是 coremask 總共有 64 個比特,但是目前 6678 最多也只有 8 個 DSP 核。所以大量 mask 比特是用不到的,目前。核 0~7 對應的 mask 比特是位于 byte[4]的 bit0:7
需要注意的是 queue 到 execution object 的映射是通過 receiver 函數關聯起來,如紅色高亮顯示部分。
初始化job的偽代碼如下:
2.2.3 產生 event
本文的演示用例把 matrix Y 切分成了 128 個 2048*16 的子塊,每個 event 對應一個子塊。Event被發送給 execution object 以后,receive 函數計算 Matrix X 乘與 matrix Y block,即 100*2048 ×2048*16 的矩陣乘,產生 100*16 個輸出。event 的產生包括下面幾個簡單步驟:
? 調用 em_alloc 函數,從 public pool 獲取 free 的 event 描述符并且 enable preloading。
? 把待處理的數據緩沖區掛到描述符上,也就是把描述符的 buffer 指針指向這個數據緩沖區。
? 在描述符的 software info 域填上 job index。
? 調用 em_send,把 event 發送到對應的 queue,也就是 proc queue。
下面是產生 event 的代碼:
需要注意的是 Event 產生的時候,它被哪一個 execution object 處理還沒有確定。因為 execution object 只是和 queue 關聯的。當把 event 發送到一個 queue 的時候,負責處理 event 的 execution object 就確定了。所以在調用 em_send()發送 event 到 queue 的時候參數之一就是要發送到的queue 的 handler。
2.2.4 運行和 exit
如前所述,“矩陣乘 event”是通過 proc queue 發給 scheduler 的,所以它被 proc queue 映射到mat_mpy calc 這個 execution object 上。Dispatcher 收到這個 event 后就調用“mat_mpy calc”對應的 receiver 函數計算矩陣相乘。因為 proc queue 所屬的 queue group 是映射到所有 DSP 核的,所以 128 個“矩陣乘 event”是在所有核上并行處理的。每個核處理完 event 后就把它釋放回global free pool。這樣這個 event 又成為一個 free 的 event。
如 2.2.3 節所述,主核可以通過查詢 global free pool 的描述符個數是否恢復來判斷是否所有“矩陣乘 event”已經處理完。
當所有“矩陣乘 event”處理完后,主核再產生 8 個“exit event”發送到 exit queue。理論上scheduler 可以把 exit job 調度給任意一個核,而不會保證每個核一個 exit job。所以 exit job 中的處理比較特殊。exit job 的 receiver 函數直接執行系統調用 exit(0)。這樣就不會返回到 Dispatcher,也不會再發出 prefetch command。而另一方面,scheduler 是在收到 DSP 核的 prefetch command 以后才把 event 調度給這個核的。這個機制保證了每個核收到且僅收到一個“exit event”。
在 exit job 的 receiver 函數中,主核執行的分支稍有差異。主核需要先做完結果的校驗再執行系統調用 exit(0)。所以在板上運行是會觀察到其他核很快(小于 1s)就從 run 狀態轉換到 abort 狀態,而主核保持 run 了很長時間(大約 50s)才進入 abort 狀態。原因是:在主核上執行結果驗證工作時產生校驗結果的函數計算耗時比較長。
下面是 exit job 的 receiver 函數的代碼主干:
2.3 基于 OpenEM 的大矩陣乘性能測試結果
2.3.1 算法代碼和 cycle 數的理論極限
設 r1 是 X 矩陣的行數,c1 是 X 矩陣的列數,c2 是 Y 矩陣的列數。在我們的演示用例中 r1 =100, c1 = 2048, c2 = 2048。如前所述,Receiver 函數要計算 100*2048 × 2048*16 的矩陣乘,對應下面的偽代碼:
循環內核是 4 個 cycle。 如果只考慮循環內核消耗的 cycle 數,計算 100*2048 × 2048*16 的矩陣乘需要的 cycle 數是 100/2*16/2*2048/4*4 = 819,200 cycle。整個 X*Y=Z 包括計算 128 個這樣的矩陣乘。所以總的 cycle 數是 819,200*128 = 104,857,600 cycles。在 1Ghz 的 C66 核上這相當于104.8ms。但是我們的上述理論計算沒有考慮循環的前后綴消耗的 cycle 數,也沒有考慮 cache miss stall 的等待時間。在 6678EVM 板的單個 DSP 核上實測,計算 X*Y=Z 消耗的實際時間是190,574,214 cycles。相當于 190ms。
2.3.2 基于 OpenEM 的性能測試結果
基于 OpenEM的演示用例實現過程中,DSP 代碼中嵌入了少量測試代碼收集運行的 cycle 信息。每個核把自己處理每個 event 的起始和結束時間記錄在內存(我們通過一個全局 timer 來保證所有DSP 核記錄的時間戳在時間軸上是同步的)。這些時間戳用 CCS 存到主機做后處理分析。通過分析,我們可以得到 8 個 DSP 核并行處理消耗的時間。還可以分析每個 DSP 核的忙/閑區間。
測試結果是,從第一個 event 開始處理到最后一個 event 處理完,總時間是 31,433,438 cycle,也就是 31.4ms。也就是說,通過 OpenEM把單 DSP 核的工作負載平衡到 8 個 DSP 核上能達到的DSP 核利用率是 190,574,214/(31,433,438*8)= 76%。
通過對時間戳的處理我們得到下面的運行圖,“-”表示 receiver 函數處理 event 的區間,本文稱之為有效時間。“#”表示 receiver 之外的區間(也就是代碼在 dispatcher 中執行的區間),本文稱之為調度開銷。每個“-”和“#”刻度表示 100,000 CPU cycle。
從上面的執行圖看,調度開銷不小,占了大約 15~20%的時間。但是這只是表面的現象。實際上,調度開銷的大部分時間里,Dispatcher 是在查詢 hardware queue,等待新的 event。這是因為preload 沒能及時完成導致的。因為同時給 8 個核做 preload 需要很大的數據搬移的流量。根據以往的測試結果。使用 QMSS 的 packet DMA 從 DDR3 輸入數據到 local L2 的流量大約是 4G bytes 每秒。那么 preload 8 個 event 總的數據量是 4byte * 2048 rows * 16 columns * 8 core = 1M bytes,需要的時間是 1/4 ms。因為每個“-”和“#”刻度表示 100,000 CPU cycle,運行圖中紅線長度就代表 preload 8 個 event 的時間,它非常接近 250,000 cycle。理論計算和實際值基本吻合,所以我們認為調度延遲是 packet DMA 的傳輸流量不足導致的。
我們也測試了不使用 pre-load 的場景。觀測到 scheduler 調度一個 event 的延遲大約是 1200 個C66 CPU cycle。但是 DSP 核處理一個 event 的耗時增大到原來的 10 倍。所以,pre-load 雖然會導致 QMSS packet DMA 流量不足成為凸顯的瓶頸,但是從總體效率來看還是非常必要的。
細心的讀者可能會發現 76% + 20% = 96%,并不是 100%。我們分析時間戳發現,8 個 DSP 核同時運行的場景下,每個核處理一個 100*2048 × 2048*16 的矩陣乘的時間比只有一個 DSP 核運行的場景下的時間稍長。原因是: 我們的演示用例中 X 矩陣和 Z 矩陣是存儲在 shared L2 的, 8 個核同時運行就會同時讀寫這兩個 buffer,導致產生 shared L2 的 bank 沖突。 所以性能下降了。
3、總結
OpenEM具有使用簡單,功能實用,執行高效的特點。能在 KeyStone 多核 DSP 上實現動態的負載平衡。它一方面提供了強大的功能,另一方面也給應用留出了很大的靈活性。例如,通過讓應用初始化 free pool 方便了 buffer 的管理。OpenEM 的現有功能已經能夠支持基本的應用。隨著版本更新功能還將不斷完善。
責任編輯:gt
-
處理器
+關注
關注
68文章
19404瀏覽量
230791 -
嵌入式
+關注
關注
5090文章
19176瀏覽量
306900 -
ti
+關注
關注
112文章
7987瀏覽量
212787
發布評論請先 登錄
相關推薦

34063的局限性
BGA封裝設計規則和局限性
多核嵌入式系統存在的局限性?怎么解決這些問題?
Web服務結構模型的研究與實現
基于微控制器的LED驅動器拓撲、權衡和局限
OpenEM的原理簡單的介紹和利用大矩陣乘的演示詳細介紹OpenEM的使用
ChatGPT的潛力和局限





 工商網監
工商網監
評論