 PCI標準的局限性及PCI Express系統的解決方案分析
PCI標準的局限性及PCI Express系統的解決方案分析
基于ISA(工業標準架構)總線的首個擴展卡最初在1978年問世,由于要求提升系統整體性能,MCA(微通道架構)等總線系統或是擴展的ISA總線隨后也相繼出現。鑒于數據通道寬度(主要是8或16位)和總線架構的速度問題,許多標準都限制了帶寬。此外,萬一錯誤配置了總線,很難確定差錯在哪里,因此調試這個系統時就會遇到各種問題。根據這些舊的總線標準的經驗,新的標準PCI(外設部件互連)最終得以確定。本文將探討PCI標準的局限性,以及下一代PCI Express是如何以節約成本的方式得以實現的。
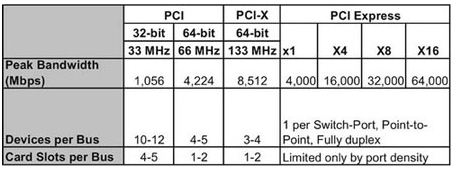
為了克服舊標準的上述局限,1992年人們建立了PCI。其目的是構建一個更高帶寬的標準,有即插即用功能和更穩健的協議。PCI協議支持差錯校驗,通過與計算機的BIOS(基本輸入輸出系統)通信實現即插即用功能,并通過標準的控制/狀態軟件接口就地址范圍或PCI插卡功能等信息進行交換。如果出現地址范圍重疊等差錯,計算機本身可以提供一些反饋。一個基本的32位33MHz的PCI系統,可支持的傳輸速率高達132MBps。但是,這個架構也有一些限制因素。總線是單向的(發起方和被請求的目標設備不能在同一時間進行通信),且幾個卡要共享一條總線。如果一張卡正在傳輸數據,所有其他的可訪問總線的部件必須等待。此外,在系統中無法處理PCI帶寬的低性能卡將進行“重試”請求,以確保有更多時間來處理數據。這就大大降低了整個系統的帶寬。PCI的另一個限制是各種應用對所需求帶寬不斷增加,特別是在視頻、通信和總線領域。圖1列出的一些應用,已經接近或超過了理論上的PCI帶寬132MBps。

圖1:各種應用的帶寬需求對比理論上PCI提供的132MBps。
PCI還有其他一些缺點,如限制只能有5個部件訪問總線。由于PCI總線特殊的無端接總線的反射,電路板的設計也更加困難。數據路徑寬度為32或64位的并行線也對時序有苛刻的要求。
根據以往經驗,PCI-SIG(PCI特別興趣小組)與行業內的領先公司合作,定義了PCI的下一代標準。新標準最初被稱為3G IO(第三代輸入輸出),后來改名為大家熟悉的PCI Express。PCI Express的首個規范于2002年4月公布,其解決了原有PCI標準的所有限制因素。為了克服無端接的大量并行總線并增加帶寬,PCI Express轉變為運行速率2.5Gbps的串行鏈路,提供兩個方向同時進行的2Gbps的原始數據率。為了滿足更高的帶寬要求,規范允許使用幾個并行的“通道”。因此對于目前計算機的低帶寬應用,有很多x1和x4通道;對于有高帶寬的要求,例如顯卡,則有x16的插槽。
由于PCI Express規范使用基于層的協議,類似于OSI的層次模型,它很容易改變物理層和保留上層協議。這種做法已被最近發布的PCI Express 2.0規范所采納,使得鏈路速度高達5Gbps。然而,大多數新的設計開始仍然是基于PCI Express 1.1版本的2.5Gbps。
一個PCI Express系統可以用幾個部件組成。所有的系統都需要有一個根聯合體(Root Complex)對整個系統進行管理。交換設備(Switch)是用來將幾個卡連接到另一個PCI Express鏈路,“端設備”則代表了用戶應用。橋接是端設備的特殊形式,可以將舊的PCI應用連接至PCI Express總線。FPGA主要用于端設備或橋接應用。
在PCI Express應用中FPGA起著重要的作用,主要有三種設計方法:
*PCI-Express至PCI橋和FPGA
*外部的PCI-Express PHY和FPGA
*PCI-Express的PHY集成在FPGA之中
第一種使用PCI-Express至PCI橋的方法,優點是可以重用舊的PCI設計,但由于額外的橋接單元,成本很高。在橋和FPGA之間,這個應用仍然被PCI的缺點所限制,在成本方面處于不利地位。
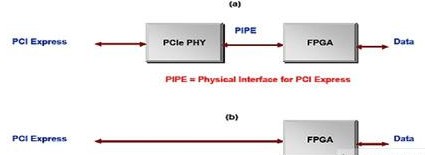
圖2A和2B
當僅需純粹的PCI Express接口,而不需要其它邏輯時,外部的PCI Express PHY和FPGA(圖2A)相結合可能極具吸引力。利用被稱為PIPE的并行接口,PCI Express PHY可以連接到FPGA。雖然PIPE接口被認為是一個標準,但不同廠商在實現方面有著細微的差別,因此物理層芯片就不容易互換。此外,工業級的外部PCI Express PHY芯片也不太容易買到,要不就是價格昂貴。此外,許多應用程序使用領先的器件,可用的領先的PCI Express PHY芯片也是很有限的。
因此,如果只有一個PCI Express接口鏈路,而且在FPGA中只要少量的額外邏輯(除了溫度范圍的限制,以及可用的領先器件),這種做法頗有意義。對于所有其他應用,最好是考慮一個整合的解決方案,如圖2B所示。
如果采用整合的解決方案,首個挑戰是尋找一個低成本的器件。在過去,PCI Express需要的串行鏈路一般只在高端昂貴的FPGA中才有。然而,今天許多應用需要較低成本的解決方案。中檔LatticeECP2M,或最近推出的LatticeECP3 FPGA系列,擁有適合這種應用的一些功能。這兩種器件都集成了可用于實現PCI Express x1或x4的串行通道。除了低成本優勢外,與高端FPGA解決方案相比,這兩類器件的功耗也非常低。該“節能方案”使系統工程師能夠降低功耗,因此只需要使用較小供電電源。圖3展示了近期推出的ECP3 FPGA系列的結構圖。
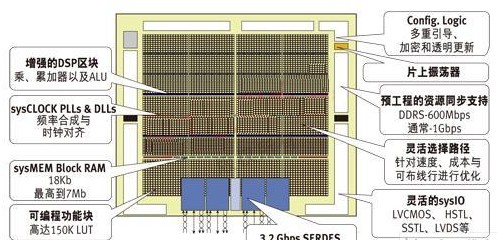
圖3:LatticeECP3中檔FPGA框圖,內有集成的SERDES模塊。
利用這些FPGA的另一個優點是它們能夠處理PCI Express使用的擴頻時鐘。許多其他的“單芯片”解決方案推薦使用外部的PLL和去除抖動來處理時鐘,這意味著電路板上會有兩到三個額外的器件。這些器件也可用在工業溫度范圍。
既然這些FPGA的串行鏈路只能實現物理層的SERDES部分,所以需要額外的邏輯來實現完整的PCS。這由軟IP核來完成,它可以配置成x1或x4 PCI Express端點。萊迪思的ispLEVER設計軟件包括一個稱為IPexpress的工具,通過GUI來配置功能,如PLL、存儲器等,還有軟IP。PCI Express核可從萊迪思網站上下載,使用IP Express進行配置并產生編程文件。即使沒有有效許可證,也可以運行這個應用數小時,從而獲得一個全面的系統*估。
為了符合系統的需要,配置PCI Express核的某些功能是非常重要的。例如, PCI Express提供不同的有效載荷大小。有效載荷的規模越大,核中需要的FIFO也越大。為了節約資源,可以通過IPexpress來選擇針對PCI Express核的正確有效載荷的大小。還有一些應加以調整的其他參數,以針對系統要求優化FPGA的利用率。
在許多項目開發中,只有在開發后期才能得到樣機電路板。為了熟悉PCI Express的協議,可從萊迪思獲取PCI Express設計套件。該套件包含了電路板,可用于x1或x4的插槽,并有一些演示配置:
* 基本方法
o 用戶訪問內存和寄存器
o 在電腦上運行演示與在電路板上的PCIe IP核之間提供簡單的互動
* 吞吐量
o 在PCIe核和SERDES之間演示和測量帶寬性能
o 使用DMA在PC機內存和PCI Express卡之間傳送數據
設計人員可以選擇使用其中一個準備好的編程文件,在30分鐘內構建一個完整的演示。套件不僅提供了硬件設計文件,而且還提供驅動程序和運行在PC上的應用程序,這樣就為設計人員的應用提供了一個良好的起點。圖4展示了萊迪思的一個完整的PCI Express演示設計。
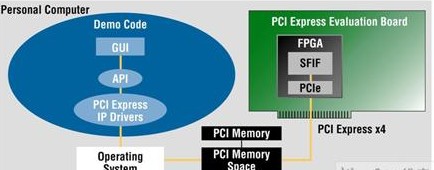
圖4:Lattice PCI Express的演示。
用協議分析儀和示波器可以調試系統。但是,利用功能或者RTL級仿真時,設計人員已經可以找到許多問題。
系統調試的三個主要方法:
* 串行環回
* 激勵發生器和測試器
* 總線功能模型
萊迪思的PCI Express核包含一個簡單的采用串行環回的測試平臺。借助一些來自測試平臺的互動建立PCI Express鏈路,并發送一些數據包。這是仿真設計的非常基本的方法。
一個更先進的方法是使用激勵發生器和測試器。FPGA中串行鏈路的仿真模型被一個模型所取代,后者生成數據包,并檢查FPGA內的邏輯響應。
最全面且成本昂貴的方法是建立總線功能模型。有幾個供應商提供PCI Express的仿真模型。根據總線功能模型,設計人員可以測試應用程序,以及FPGA的串行鏈路與整個系統的互動。
-
FPGA
+關注
關注
1630文章
21796瀏覽量
605204 -
PCI
+關注
關注
4文章
671瀏覽量
130413 -
總線
+關注
關注
10文章
2900瀏覽量
88291
發布評論請先 登錄
相關推薦
PCI Express標準技術性概述
針對可編程PCI Express解決方案的評估方法
PCI Express插槽,什么是PCI Express插槽
PCI-Express插槽
采用中檔FPGA設計面向PCI Express系統的解決方案
PCI Express總線
LSI推出PCI Express固態存儲解決方案樣片
PCI Express解決方案的介紹
如何創建和使用Xilinx的UltraScale PCI Express解決方案
PCI Express系統中DMA的基本功能介紹
WSN中LEACH協議局限性的分析與改進






 工商網監
工商網監
評論