 基于MC9S08JM60的新型編程調試器提高通信速度
基于MC9S08JM60的新型編程調試器提高通信速度
引 言
目前市場上影響力較大的針對S12的集成開發環境CodeWarrior HCS12,功能完善、性能穩定,但是價格昂貴,不利于嵌入式領域的教學和開發。在國內由清華大學開發的S12BDM調試頭,目前可支持的目標CPU外部晶振頻率不高于19 MHz,它的軟件部分由飛思卡爾半導體公司提供。蘇州大學2005年研制了針對S12系列MCU的編程調試器,采用MC68HC908JB8(以下簡稱 JB8)作為編程調試器芯片;但是隨著芯片制造技術的更新,S12系列MCU的品種越來越多,性能越來越好,典型的S12系列MCU總線頻率為25 MHz,而JB8的總線頻率只有3 MHz,可適用目標芯片的型號有限,且JB8只有256字節的RAM空間,可用于接收數據的緩存太小,影響通信速度。因此更加迫切地需要一款功能更加強大并且具有通用性的編程調試器來滿足S12系列MCU的需求。
本文在分析了S12系列MCU編程調試器MC68HC908JB8的基礎上,設計了基于MC9S08JM60(以下簡稱JM60)的新型編程調式器,主要解決JB8在通信速率上存在的不足和在通用性方面存在的問題。
1 總體概述
本文所說的編程系統包括編程調試器和PC方的通信,以及編程調試器和目標芯片的通信。圖1是編程系統的基本架構。在編程系統中,JM60通過USB2.O和PC方進行交互,接收來自PC方的命令并執行相應的操作,然后通過BDM接口將命令和數據發送到目標芯片,完成對目標芯片的操作。

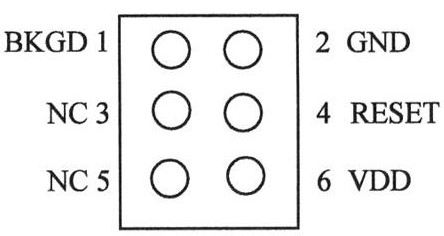
BDM是飛思卡爾半導體公司推出的一種單線調試方式。圖2是BDM接口引腳圖,所有命令和參數均通過BKGD專用引腳進行傳輸,不占用其他任何資源;而且 BDM子模塊獨立于CPU,有獨立的狀態機來處理單線接口。與通常的開發手段相比,BDM子模塊能利用CPU的空閑周期與CPU打交道,不需要停止處理器即可訪問存儲器資源。
本編程系統中,作為編程調試器芯片的JM60所擁有的USB2.O全速設備較之串口和USBl.1,它和PC方通信速率非常快。JM60可達24 MHz的總線頻率以及充足的RAM空間使得通信流程可以得到進一步改進;同時,JM60的高總線頻率也解決了以往采用JB8作為編程調試器芯片但由于 JB8自身總線頻率低而限制目標芯片通信頻率的瓶頸,使得編程系統的通用性得到提高。
2 通信系統的改進
2.1 通信流程的改進
編程系統的通信由PC機、編程調試器和目標芯片的交互來完成,因而編程系統通信流程的高效與否直接影響著整個編程系統的通信速率。編程系統的通信過程如下:
①PC發送進入BDM命令,目標芯片進入BDM模式;
②PC發送完全擦除命令,擦除目標芯片Flash并進行空白校驗,返回校驗碼;
③PC發送命令將寫入子程序的目標代碼發送到目標芯片內存中,寫入子程序的功能是將存放在目標芯片內存上的用戶目標代碼寫入Flash中;
④PC分析S19文件,提取需要發送的目標代碼,以512字節組合成一頁,分頁發送到目標芯片內存中,然后運行已發送目標芯片中的寫入子程序,將用戶目標代碼寫入目標芯片Flash中;
⑤PC判斷是否需要發送下一頁,并接收校驗碼判斷一頁數據發送是否正確。
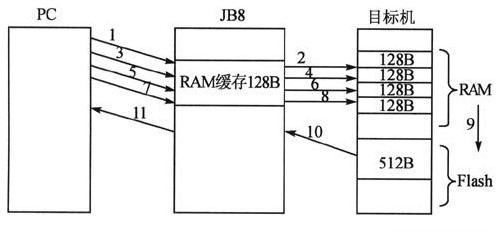
PC發送一頁數據到目標芯片內存之前,先將數據發送到編程調試器內存,和一次向S12系列芯片Flash寫入512字節相比較。JB8的RAM只有有限的 256字節,并且堆棧也在RAM區域,可用于接收一頁數據的RAM緩存太小,因而每次寫入的數據量就會受到限制,要分多次寫入。這就增加了PC和編程調試器之間的通信次數以及編程調試器和目標芯片的通信次數,從而影響了編程的速度。圖3中,JB8以串行的方式接收和發送數據,先從PC方接收一頁128字節用戶目標代碼(1,3,5,7過程),然后將數據發送到目標芯片內存(2,4,6,8過程)。經過4次的接收之后,目標芯片將RAM空間的512字節數據一次寫入Flash空間,返回校驗碼。
而JM60作為編程調試器則擁有4 KB的RAM,可以直接開辟512字節作為緩沖。在整個編程系統通信流程的設計上,就可以借鑒指令流水線操作的思想,充分考慮可作預取的操作,利用編程調試器和目標芯片之間通信的時間完成PC方單獨的操作,以及利用目標芯片自身進行操作的時間來完成PC方和編程調試器之間的操作,提高編程系統的運行速率,盡量減少空等待操作。
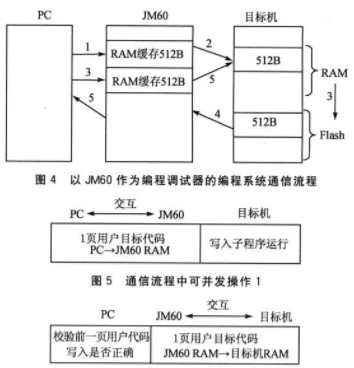
在圖4所示的以JM60作為編程調試器的編程系統通信流程中,首先PC發送第1頁用戶目標代碼到JM60內存(過程1),然后發送到目標芯片內存(過程 2),目標芯片執行寫入子程序將數據寫入Flash。寫入子程序執行過程中,字寫入命令時間t=9×(1÷fNMVOP)+25×(1÷fbus)。 fNMVOP指Flash操作頻率,fbus指總線頻率。S12系列芯片Flash的操作頻率范圍限制在150~200 kHz,取fNMVOP=200 kHz,fbus=40 MHz,計算得1個字寫入時間在最小情況下為t=0.045 625 ms,寫入512字節需要時間為11.68 ms,而PC發送1頁數據的時間為512×8÷12Mbps=0.341 ms。因此PC和JM60可以利用目標芯片寫入1頁數據的時間進行交互,將下一頁數據提前發送到JM60,完成從PC→JM60內存,如圖5所示。 JM60和目標芯片也可以在PC對前一頁數據進行校驗的同時,將1頁數據從JM60發送到目標芯片,如圖6所示。
在實現以上思想的同時也充分考慮了寫入過程出錯的情況,如圖4在JM60內存區域開辟了可存放2頁數據的緩沖區用于接收用戶目標代碼。若前一頁數據寫入錯誤,則將這頁數據在Flash的塊寫入首地址傳遞給塊擦除程序,重新進行擦除,等待當前頁發送完畢,作為下一頁數據參與整個流程進行寫入。
2.2 通信子程序的改進
2.2.1 優化通信子程序代碼
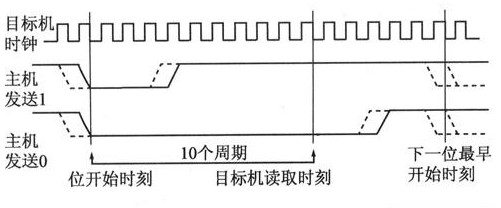
通信流程的改進提高了整個編程系統的通信速率。進一步分析編程系統,從JM60發送數據到目標芯片,內存需要的時間在整個程序下載過程中占用比例比較大;而在1位發送過程中,如圖7所示,從位開始時刻到目標芯片讀取時刻的周期間隔是固定的10~13個目標周期,但位與位之間的發送存在時隙。
在原有編程系統的字節發送代碼中,發送位1和位0是兩個單獨的子程序,需要通過判斷來分別調用兩個子程序。所使用的BCC、JSR、BRA都是周期較長的指令,且每發送1位就調用1次JSR指令,就有一次RTS指令返回,需要周期較多。在改進編程系統的字節發送代碼中,將位1和位0的發送代碼很好地結合在 1個子程序之內,縮短了位與位之間發送的時隙。
編程系統通過BDM硬件命令WRITE_WORD發送1個字,需要調用5次字節發送程序。發送的5字節分別是1字節的命令操作碼、2字節的內存地址、2字節的數據,同時硬件命令WRTE_WORD的完成還需要延遲150個編程調試器時鐘周期。所以假如從編程調試器發送100 KB的數據到目標芯片內存,其所需要花費的時間計算如下:
在JB8的編程系統中,發送1個字節的周期為:2+(1+3+5+4+4+4+3+3+4+7)×8+4=310,100 KB的數據需要(100×1024÷2)個字×(5×310+150)個周期÷(3×106)=29.01 s。
在改進的編程系統中,發送1個字節的周期為:2+2+4+3+1+1+2+4+(1+3+6+88)×8+2+4=809,100 KB的數據需要(100×1024÷2)個字×(5×809+150)個周期÷(24×105)=8.95 s。
而JM60緩存中的數據是以連續存放的形式寫入目標芯片內存的,因此可以選用BDM固件命令WRITE_NEXT,每次執行命令時寄存器X的值會先自動加 2,然后將1個字寫入到X所指向的地址。所以只需要在寫入開始時,對寄存器X進行一次地址賦值操作,將目標芯片內存地址減2處的地址值賦給X即可,后續數據可以直接調用WRITE_NEXT命令寫入,不需要再發送地址信息。采用WRITE_NEXT寫1個字需要發送3個字節(1個字節的命令操作碼、2個字節的數據),它的完成需要延遲32個編程調試器時鐘周期。因而從編程調試器發送100 KB的數據到目標芯片內存需要花費的時間計算如下:
(100×1024÷2)個字×(3×809+32)個周期÷(24×106)=5.25 s
改進后的編程系統在編程調試器內存與目標芯片內存的數據通信速度上提高了5.5倍,大大提高了編程調試器的工作效率。
2.2.2 編寫目標芯片接收程序
優化通信子程序代碼之后,從編程調試器內存向目標芯片內存發送數據的時間大大減少,但是使用BDM命令,除了發送2個字節的用戶數據之外,還需要發送額外的字節,并且命令的完成都需要較長的延遲時間。由于BDM采用單線引腳串行通信,因此可以自己編寫一段模擬BDM串行通信的程序,目標芯片只從編程調試器接收用戶目標代碼,提高通信速度。
另外將JM60的引腳PTBD.O與目標芯片PTA.0引腳相連來傳送數據,以便數據通信過程不影響BKGD引腳。過程如下:
①按照編程調試器發送1位時序,在編程調試器方編寫以PTBD.0為發送引腳的字節發送代碼;
②按照目標芯片接收1位的過程,編寫目標芯片以PTA.0為接收引腳的字節接收代碼,進而編寫好目標芯片接收程序;
③將自定義的目標芯片接收程序編譯成目標代碼,通過基本的BDM命令發送到目標芯片內存;
④執行目標芯片中自定義的接收程序,將接收到的字節寫入目標芯片指定的內存空間。
由于目標芯片的接收程序是自己定義的,因此編程調試器不需要發送操作碼與地址信息,也無需等待命令完成延遲時間。自定義的目標芯片接收程序代碼量少于50字節,這部分時間很短。因而假如從編程調試器發送100KB的數據到目標芯片內存,需要花費的時間計算如下:
(100×1024)個字節×809個周期÷(24×106)=3.45 s
使用自定義目標芯片接收程序,在原有系統編程調試器內存與目標芯片內存的數據通信速度上提高了8倍多。
3 編程系統的通用性設計
編程系統的通用性在于兩點:一是可以根據不同型號的目標芯片獲取相應的MCU參數進行操作;二是可以根據不同型號MCU的總線頻率調用相應的發送接收代碼。
3.1 MCU信息的存儲
S12系列MCU有很多型號,而且未來還會推出更多新型號。表1給出了數據庫中MCU的信息。不同型號MCU屬性參數不同,包括內部RAM及Flash的大小和起始地址。這些參數在對目標芯片進行擦除、寫入及調試操作時極為重要。為了便于通用性方面的設計,在PC方數據庫中保存了每款MCU的相關信息,在用戶建立工程的時候就可以獲取這些字段信息,對目標芯片進行正確的操作。
2.2 通信子程序的改進
2.2.1 優化通信子程序代碼
通信流程的改進提高了整個編程系統的通信速率。進一步分析編程系統,從JM60發送數據到目標芯片,內存需要的時間在整個程序下載過程中占用比例比較大;而在1位發送過程中,如圖7所示,從位開始時刻到目標芯片讀取時刻的周期間隔是固定的10~13個目標周期,但位與位之間的發送存在時隙。
在原有編程系統的字節發送代碼中,發送位1和位0是兩個單獨的子程序,需要通過判斷來分別調用兩個子程序。所使用的BCC、JSR、BRA都是周期較長的指令,且每發送1位就調用1次JSR指令,就有一次RTS指令返回,需要周期較多。在改進編程系統的字節發送代碼中,將位1和位0的發送代碼很好地結合在 1個子程序之內,縮短了位與位之間發送的時隙。
編程系統通過BDM硬件命令WRITE_WORD發送1個字,需要調用5次字節發送程序。發送的5字節分別是1字節的命令操作碼、2字節的內存地址、2字節的數據,同時硬件命令WRTE_WORD的完成還需要延遲150個編程調試器時鐘周期。所以假如從編程調試器發送100 KB的數據到目標芯片內存,其所需要花費的時間計算如下:
在JB8的編程系統中,發送1個字節的周期為:2+(1+3+5+4+4+4+3+3+4+7)×8+4=310,100 KB的數據需要(100×1024÷2)個字×(5×310+150)個周期÷(3×106)=29.01 s。
在改進的編程系統中,發送1個字節的周期為:2+2+4+3+1+1+2+4+(1+3+6+88)×8+2+4=809,100 KB的數據需要(100×1024÷2)個字×(5×809+150)個周期÷(24×105)=8.95 s。
而JM60緩存中的數據是以連續存放的形式寫入目標芯片內存的,因此可以選用BDM固件命令WRITE_NEXT,每次執行命令時寄存器X的值會先自動加 2,然后將1個字寫入到X所指向的地址。所以只需要在寫入開始時,對寄存器X進行一次地址賦值操作,將目標芯片內存地址減2處的地址值賦給X即可,后續數據可以直接調用WRITE_NEXT命令寫入,不需要再發送地址信息。采用WRITE_NEXT寫1個字需要發送3個字節(1個字節的命令操作碼、2個字節的數據),它的完成需要延遲32個編程調試器時鐘周期。因而從編程調試器發送100 KB的數據到目標芯片內存需要花費的時間計算如下:
(100×1024÷2)個字×(3×809+32)個周期÷(24×106)=5.25 s
改進后的編程系統在編程調試器內存與目標芯片內存的數據通信速度上提高了5.5倍,大大提高了編程調試器的工作效率。
2.2.2 編寫目標芯片接收程序
優化通信子程序代碼之后,從編程調試器內存向目標芯片內存發送數據的時間大大減少,但是使用BDM命令,除了發送2個字節的用戶數據之外,還需要發送額外的字節,并且命令的完成都需要較長的延遲時間。由于BDM采用單線引腳串行通信,因此可以自己編寫一段模擬BDM串行通信的程序,目標芯片只從編程調試器接收用戶目標代碼,提高通信速度。
另外將JM60的引腳PTBD.O與目標芯片PTA.0引腳相連來傳送數據,以便數據通信過程不影響BKGD引腳。過程如下:
①按照編程調試器發送1位時序,在編程調試器方編寫以PTBD.0為發送引腳的字節發送代碼;
②按照目標芯片接收1位的過程,編寫目標芯片以PTA.0為接收引腳的字節接收代碼,進而編寫好目標芯片接收程序;
③將自定義的目標芯片接收程序編譯成目標代碼,通過基本的BDM命令發送到目標芯片內存;
④執行目標芯片中自定義的接收程序,將接收到的字節寫入目標芯片指定的內存空間。
由于目標芯片的接收程序是自己定義的,因此編程調試器不需要發送操作碼與地址信息,也無需等待命令完成延遲時間。自定義的目標芯片接收程序代碼量少于50字節,這部分時間很短。因而假如從編程調試器發送100KB的數據到目標芯片內存,需要花費的時間計算如下:
(100×1024)個字節×809個周期÷(24×106)=3.45 s
使用自定義目標芯片接收程序,在原有系統編程調試器內存與目標芯片內存的數據通信速度上提高了8倍多。
3 編程系統的通用性設計
編程系統的通用性在于兩點:一是可以根據不同型號的目標芯片獲取相應的MCU參數進行操作;二是可以根據不同型號MCU的總線頻率調用相應的發送接收代碼。
3.1 MCU信息的存儲
S12系列MCU有很多型號,而且未來還會推出更多新型號。表1給出了數據庫中MCU的信息。不同型號MCU屬性參數不同,包括內部RAM及Flash的大小和起始地址。這些參數在對目標芯片進行擦除、寫入及調試操作時極為重要。為了便于通用性方面的設計,在PC方數據庫中保存了每款MCU的相關信息,在用戶建立工程的時候就可以獲取這些字段信息,對目標芯片進行正確的操作。
3.2 目標芯片總線頻率的測定
不同型號的MCU總線頻率不一樣,因此編程系統的通用性還在于能使編程調試器自動獲取目標MCU的通信頻率,使之適應不同型號的MCU。
在HCS12中有一條比較特殊的BDM指令SYNC,它用于探測目標MCU的BDM接口的通信頻率。該指令沒有具體的操作碼,因此不要求知道具體的目標芯片BDM通信頻率。表2給出了使用SYNC指令探測目標芯片BDM通信頻率的過程。
編程調試器是通過拉低至少128個目標芯片時鐘周期來請求SYNC指令的,為了能夠測量所有的S12系列芯片BDM通信頻率,需要設置一個缺省計時參數。當目標芯片總線頻率低于1 MHz的時候,Flash的擦除寫入操作不能正常運行,因此可以設置目標芯片的最低BDM接口頻率為1 MHz。128個周期時長為128÷1 MHz=128μs。在這個延時時間內,可以向S12系列芯片成功請求SYNC指令。下面給出了測試目標芯片通信頻率的代碼。
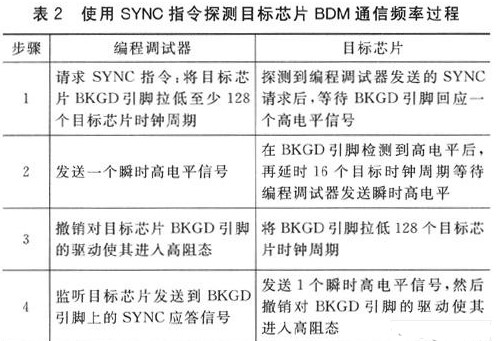

陰影部分是JM60在目標芯片發送128個周期低電平的時間所做的操作,花費的指令周期為count=5+1+6×A(寄存器A的計數次數),目標芯片的通信頻率就可以通過公式fBDM=128×fbus÷count計算得到。編程調試器只需要根據計算得到的目標芯片的通信頻率,調用在編程調試器方編寫的針對不同通信頻率段的收發子程序,就可以實現和不同型號目標芯片的正確通信。
結 語
編程系統的通信速率和通用性是衡量編程調試器性能的重要指標。在實際應用中,用戶需要不斷地修改、調試程序,程序的下載操作會頻繁發生,因此減少數據的通信時間,提高用戶目標代碼的寫入速度顯得尤為重要。本文針對S12新型編程系統的設計思想已經應用于SD-Pro-grammer For S12 V2中,通信速度提高了5倍多,能適應當前S12系列所有的MCU,對于新款MCU可以實現快速支持。文中給出的編程系統中提高通信速度的設計方法對類似于嵌入式系統的應用開發也有著很好的借鑒作用。
-
芯片
+關注
關注
455文章
50756瀏覽量
423335 -
半導體
+關注
關注
334文章
27320瀏覽量
218287 -
調試器
+關注
關注
1文章
304瀏覽量
23738
發布評論請先 登錄
相關推薦
MC9S08DZ60CLC
S9S08DZ60F1MLF
用于MC9S08JM60 S08微控制器的StarterTRAK USB開發系統
MC9S08JM16血糖監視儀解決方案
基于MC9S08JM60 MCU的觸摸傳感評估板
具有I/O功能的用于MC9S08DZ60微控制器
如何設計一款基于MC9S08JM60的新型編程調式器?
MC9S08JM60,8位USB微控制器
MC9S08JM60,MC9S08JM32,pdf,data
MC9S08AW60,pdf datasheet

MC9S08JM60開發USB設備模塊深度理解





 工商網監
工商網監
評論