 聊聊原子變量、鎖、內存屏障那點事(1)
聊聊原子變量、鎖、內存屏障那點事(1)
突然想聊聊這個話題,是因為知乎上的一個問題多次出現在了我的Timeline里:請問,多個線程可以讀一個變量,只有一個線程可以對這個變量進行寫,到底要不要加鎖?可惜的是很多高票答案語焉不詳,甚至有所錯漏。所以我想在這篇文章里斗膽聊聊這個水挺深的問題。受限于個人水平,文章若有錯漏,還望讀者不吝賜教。
首先約定,由于CPU的架構和設計浩如煙海,本文站在工程師的角度,只談IA32/AMD64(x86-64)架構,不討論其他架構的細節和差異。并且文章中主要引用Intel的文檔予以佐證,不關注AMD在實現細節上的差異。
眾所周知,當一個執行中的程序的數據被多個執行流并發訪問的時候,就會涉及到同步(Synchronization)的問題。同步的目的是保證不同執行流對共享數據并發操作的一致性。早在單核時代,使用鎖或者原子變量就很容易達成這一目的。甚至因為CPU的一些訪存特性,對某些內存對齊數據的讀或寫也具有原子的特性。
比如,在《Intel? 64 and IA-32 Architectures Software Developer’s Manual》的第三卷System Programming Guide的Chapter 8 Multiple-Processor Management里,就給出了這樣的說明:
也就是說,有些內存對齊的數據的訪問在CPU層面就是原子進行的(注意這里說的只是單次的讀或者寫,類似普通變量i的i++操作不止一次內存訪問)。此時,環形隊列(Ring buffer)這種數據結構在某些架構的單核CPU上,只有一個Reader和一個Writer的情況下是不需要額外同步措施的。原因就是read_index和writer_index的寫操作在滿足對齊內存訪問的情況下是原子的,不需要額外的同步措施。注意這里我加粗了單核CPU這個關鍵字,那么到了多核心處理器的今天,該操作就不是原子了嗎?不,依舊是原子的,但是出現了其他的干擾因素迫使可能需要額外的同步措施才能保證原本無鎖代碼的正確運行。
首先是現代編譯器的代碼優化和編譯器指令重排可能會影響到代碼的執行順序。編譯期指令重排是通過調整代碼中的指令順序,在不改變代碼語義的前提下,對變量訪問進行優化。從而盡可能的減少對寄存器的讀取和存儲,并充分復用寄存器。但是編譯器對數據的依賴關系判斷只能在單執行流內,無法判斷其他執行流對競爭數據的依賴關系。就拿無鎖環形隊列來說,如果Writer做的是先放置數據,再更新索引的行為。如果索引先于數據更新,Reader就有可能會因為判斷索引已更新而讀到臟數據。
那禁止編譯器對該類變量的優化,解決了編譯期的重排序就沒事了嗎?不,CPU還有亂序執行(Out-of-Order Execution)的特性。流水線(Pipeline)和亂序執行是現代CPU基本都具有的特性。機器指令在流水線中經歷取指、譯碼、執行、訪存、寫回等操作。為了CPU的執行效率,流水線都是并行處理的,在不影響語義的情況下。處理器次序(Process Ordering,機器指令在CPU實際執行時的順序)和程序次序(Program Ordering,程序代碼的邏輯執行順序)是允許不一致的,即滿足As-if-Serial特性。顯然,這里的不影響語義依舊只能是保證指令間的顯式因果關系,無法保證隱式因果關系。即無法保證語義上不相關但是在程序邏輯上相關的操作序列按序執行。從此單核時代CPU的Self-Consistent特性在多核時代已不存在,多核CPU作為一個整體看,不再滿足Self-Consistent特性。
簡單總結一下,如果不做多余的防護措施,單核時代的無鎖環形隊列在多核CPU中,一個CPU核心上的Writer寫入數據,更新index后。另一個CPU核心上的Reader依靠這個index來判斷數據是否寫入的方式不一定可靠。index有可能先于數據被寫入,從而導致Reader讀到臟數據。
所有的麻煩到這里就結束了嗎?當然不,還有Cache的問題。前文提到的都是順序一致性(Sequential Consistency)的問題,沒有涉及Cache一致性(Cache Coherence)的問題。雖然說一般情況下程序員只需要關注順序一致性即可,但是區分清楚這兩個概念也能更好的解釋內存屏障(Memory Barrier)。
開始提到Cache一致性協議之前,先介紹兩個名詞:
Load/Read CPU讀操作,是指將內存數據加載到寄存器的過程
Store/Write CPU寫操作,是指將寄存器數據寫回主存的過程
現代處理器的緩存一般分為三級,由每一個核心獨享的L1、L2 Cache,以及所有的核心共享L3 Cache組成:
由于Cache的容量很小,一般都是充分的利用局部性原理,按行/塊來和主存進行批量數據交換,以提升數據的訪問效率。以前寫過一篇《淺析x86架構中cache的組織結構》,這里不再贅述。既然各個核心之間有獨立的Cache存儲器,那么這些存儲器之間的數據同步就是個比較復雜的事情。緩存數據的一致性由緩存一致性協議保證。這里比較經典的當屬MESI協議。Intel的處理器使用從MESI中演化出的MESIF協議,而AMD使用MOESI協議。緩存一致性協議的細節超出了本文的討論范圍,有興趣的讀者可以自行研究。
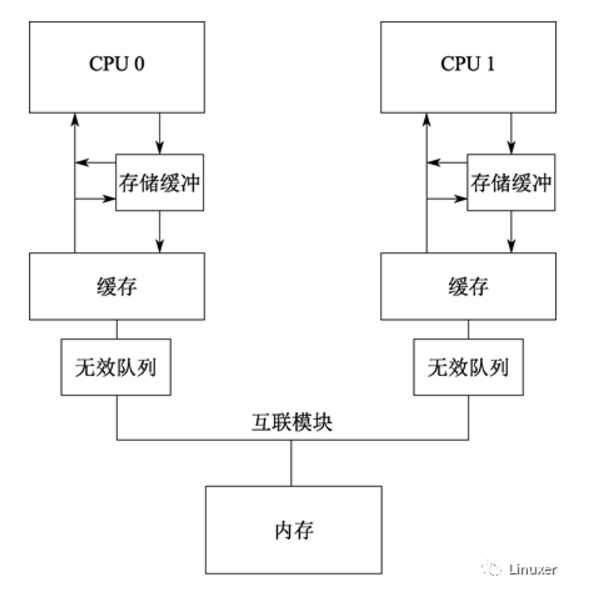
傳統的MESI協議中有兩個行為的執行成本比較大。一個是將某個Cache Line標記為Invalid狀態,另一個是當某Cache Line當前狀態為Invalid時寫入新的數據。所以CPU通過Store Buffer和Invalidate Queue組件來降低這類操作的延時。如圖:
當一個核心在Invalid狀態進行寫入時,首先會給其它CPU核發送Invalid消息,然后把當前寫入的數據寫入到Store Buffer中。然后異步在某個時刻真正的寫入到Cache Line中。當前CPU核如果要讀Cache Line中的數據,需要先掃描Store Buffer之后再讀取Cache Line(Store-Buffer Forwarding)。但是此時其它CPU核是看不到當前核的Store Buffer中的數據的,要等到Store Buffer中的數據被刷到了Cache Line之后才會觸發失效操作。而當一個CPU核收到Invalid消息時,會把消息寫入自身的Invalidate Queue中,隨后異步將其設為Invalid狀態。和Store Buffer不同的是,當前CPU核心使用Cache時并不掃描Invalidate Queue部分,所以可能會有極短時間的臟讀問題。當然這里的Store Buffer和Invalidate Queue的說法是針對一般的SMP架構來說的,不涉及具體架構。事實上除了Store Buffer和Load Buffer,流水線為了實現并行處理,還有Line Fill Buffer/Write Combining Buffer 等組件,參考文獻8-10給出了相關的資料可以進一步閱讀。
-
寄存器
+關注
關注
31文章
5336瀏覽量
120232 -
cpu
+關注
關注
68文章
10854瀏覽量
211589 -
編譯器
+關注
關注
1文章
1623瀏覽量
49108
原文標題:淺墨: 聊聊原子變量、鎖、內存屏障那點事(1)
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從硬件引申出內存屏障,帶你深入了解Linux內核RCU
ARM體系結構之內存序與內存屏障
詳解Linux內核鎖的原子操作
MCU上的無鎖原子讀操作
CPU和內存的那點事兒
導致ARM內存屏障的原因究竟有哪些
學習下ARM內存屏障(memory barrier)指令
聊聊原子變量、鎖、內存屏障那點事(2)
可以了解并學習Linux 內核的同步機制
Linux內核的內存屏障的原理和用法分析
Rust原子類型和內存排序
一文徹底搞懂內存屏障與volatile
如何實現一個多讀多寫的線程安全的無鎖隊列





 工商網監
工商網監
評論