") 基于Lucene實(shí)現(xiàn)全文搜索引擎MYSearch的構(gòu)建
基于Lucene實(shí)現(xiàn)全文搜索引擎MYSearch的構(gòu)建
互聯(lián)網(wǎng)最初設(shè)計是為了能提供一個通訊網(wǎng)絡(luò),即使一些地點(diǎn)被核武器摧毀也能正常工作。如果大部分的直接通道不通,路由器就會指引通信信息經(jīng)由中間路由器在網(wǎng)絡(luò)中傳播。 最大的搜索引擎Google從2002年的10億網(wǎng)頁增加到現(xiàn)在近40億網(wǎng)頁;最近雅虎搜索引擎號稱收錄了45億個網(wǎng)頁;國內(nèi)的中文搜索引擎百度的中文頁面從兩年前的7 000萬頁增加到了現(xiàn)在的2億多。據(jù)估計,當(dāng)前整個互聯(lián)網(wǎng)的網(wǎng)頁數(shù)達(dá)到100多億,而且還在快速增長。用戶要在如此浩瀚的信息海洋里尋找信息,猶如“大海撈針”,往往無功而返。如何從資源的海洋里找到自己需要的內(nèi)容就成了關(guān)鍵問題,搜索引擎的出現(xiàn)和研究,使網(wǎng)絡(luò)上的資源變得有序,使用戶能更加方便快捷地找到所需資源。目前被大家廣泛使用的搜索引擎如Google、百度等,其實(shí)現(xiàn)技術(shù)非常復(fù)雜,后臺數(shù)據(jù)庫也非常龐大,更新速度也很快。
1 Lucene基本技術(shù)原理
Lucene是apache軟件基金會4 jakarta項目組的一個子項目,是一個開放源代碼的全文檢索引擎工具包,即它不是一個完整的全文檢索引擎,而是一個全文檢索引擎的架構(gòu),提供了完整的查詢引擎和索引引擎,部分文本分析引擎(英文與德文兩種西方語言)。Lucene的目的是為軟件開發(fā)人員提供一個簡單易用的工具包,以方便的在目標(biāo)系統(tǒng)中實(shí)現(xiàn)全文檢索的功能,或者是以此為基礎(chǔ)建立起完整的全文檢索引擎。
作為一個開放源代碼項目,Lucene從問世之后,引發(fā)了開放源代碼社群的巨大反響,程序員們不僅使用它構(gòu)建具體的全文檢索應(yīng)用,而且將之集成到各種系統(tǒng)軟件中去,以及構(gòu)建Web應(yīng)用,甚至某些商業(yè)軟件也采用了Lucene作為其內(nèi)部全文檢索子系統(tǒng)的核心。apache軟件基金會的網(wǎng)站使用了Lucene作為全文檢索的引擎,IBM的開源軟件eclipse[9]的2.1版本中也采用了Lucene作為幫助子系統(tǒng)的全文索引引擎,相應(yīng)的IBM的商業(yè)軟件Web Sphere[10]中也采用了Lucene。Lucene以其開放源代碼的特性、優(yōu)異的索引結(jié)構(gòu)、良好的系統(tǒng)架構(gòu)獲得了越來越多的應(yīng)用。
目前網(wǎng)絡(luò)上有許多全文搜索引擎的開源代碼,若想構(gòu)建自己的全文搜索引擎,可以在這些開源代碼的基礎(chǔ)上進(jìn)行。Lucene不是一個完整的全文索引應(yīng)用,可以直接作為查詢工具使用,而只是為全文搜索引擎的構(gòu)建提供了基本的工具和設(shè)計方法。Lucene提供了一系列API,能夠?qū)ξ臋n進(jìn)行預(yù)處理、過濾、分析、索引和檢索排序。本文就是在Lucene基礎(chǔ)上構(gòu)建了一個全文搜索引擎MYSearch。
2 MYSearch工作流程
2.1 搜索引擎的基本構(gòu)成
搜索引擎系統(tǒng)一般由蜘蛛(也叫網(wǎng)頁爬行器)、切詞器、索引器、查詢器幾部分組成。蜘蛛負(fù)責(zé)網(wǎng)頁信息的抓取工作;一般情況下切詞器和索引器一起使用,它們負(fù)責(zé)將抓取的網(wǎng)頁內(nèi)容進(jìn)行切詞處理并自動進(jìn)行標(biāo)引,建立索引數(shù)據(jù)庫;查詢器根據(jù)用戶查詢條件檢索索引數(shù)據(jù)庫并對檢索結(jié)果進(jìn)行排序和集合運(yùn)算,再提取網(wǎng)頁簡單摘要信息反饋給查詢用戶。
2.2 MYSearch工作流程
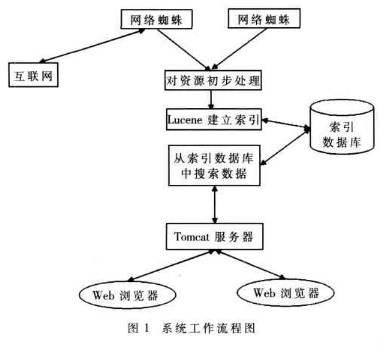
MYSearch首先使用網(wǎng)絡(luò)蜘蛛抓取網(wǎng)絡(luò)上的可用網(wǎng)頁鏈接,然后把抓取到的網(wǎng)頁資源下載到本地計算機(jī),對下載到本地計算機(jī)的網(wǎng)頁進(jìn)行初步的處理,去掉對搜索沒有意義的信息和詞匯。然后使用Lucene提供的索引功能,對處理后的信息資源建立索引,并且保存到索引數(shù)據(jù)庫中。之后,根據(jù)用戶提供的搜索信息,在索引中進(jìn)行查詢,并將搜索結(jié)果顯示到用戶搜索的界面上。其流程框圖如圖1所示。
3 MYSearch實(shí)現(xiàn)
3.1 系統(tǒng)功能模塊的劃分
MYSearch全文搜索系統(tǒng)主要分為網(wǎng)絡(luò)蜘蛛抓取、資源初步處理、建立索引、搜索以及顯示等功能模塊。
(1)網(wǎng)絡(luò)蜘蛛抓取功能模塊:首先根據(jù)事先設(shè)定好的網(wǎng)絡(luò)入口地址和設(shè)置的搜索條件,讀取網(wǎng)頁的內(nèi)容,分析網(wǎng)頁中其他的鏈接地址,然后垂直鏈接到下一個網(wǎng)頁,這樣一直循環(huán),直到網(wǎng)站的所有網(wǎng)頁都抓取完成或者滿足了搜索的條件為止。
(2)資源初步處理功能模塊:將搜索來的網(wǎng)頁中的信息進(jìn)行相關(guān)處理,去掉沒有用的格式內(nèi)容和其他對搜索結(jié)果沒有實(shí)際意義的信息。
(3)建立索引功能模塊:將處理后的網(wǎng)頁資源寫入數(shù)據(jù)庫,并使用倒排索引算法實(shí)現(xiàn)網(wǎng)頁資源索引的建立。
(4)搜索功能模塊:根據(jù)用戶的搜索關(guān)鍵詞,在已建好索引的數(shù)據(jù)庫中,根據(jù)語素向量的匹配度和相似度進(jìn)行相關(guān)的匹配,然后按照一定的排列順序把搜索結(jié)果返回給用戶。
(5)顯示功能模塊:將搜索結(jié)果按照一定的顯示方式顯示在頁面中,供用戶選擇和瀏覽。
3.2 MYSearch全文搜索引擎的實(shí)現(xiàn)
3.2.1 網(wǎng)絡(luò)蜘蛛
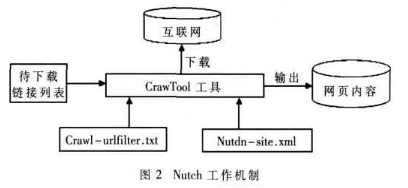
網(wǎng)絡(luò)蜘蛛是指某個能以人類無法達(dá)到的速度不斷重復(fù)執(zhí)行某項任務(wù)的自動程序[1]。本系統(tǒng)中使用的蜘蛛程序是Nutch,核心是Crawl工具。它可以根據(jù)之前設(shè)定好的入口URL列表不斷地自動下載頁面,直到滿足系統(tǒng)預(yù)設(shè)的停止條件。圖2所示是Nutch的工作機(jī)制。
3.2.2 網(wǎng)頁初步處理
網(wǎng)頁剛剛被抓取下來的時候,存在很多格式化的信息(如html的網(wǎng)頁標(biāo)記),還有很多多余的信息(比如“is,the,an”)。這些信息都是噪音,如果想要使搜索引擎更高效、更準(zhǔn)確地運(yùn)行,就要去除這些信息,留下有效的信息。
對于html標(biāo)記的處理,首先就是準(zhǔn)備一個空字符串,然后判斷網(wǎng)頁的文字中是否存在html的“<>”符號,如果是html“<>”的符號,就繼續(xù)判斷網(wǎng)頁中的下一個字符,如果不是就把該字符保存到這個空字符串中;如果判斷完成,就結(jié)束;否則就繼續(xù)判斷。對于多余信息,在Lucene中提供了相關(guān)的包進(jìn)行處理。
通過上面的處理之后,下載的文件在建立索引的時候,就會更加便捷。
3.2.3 索引的建立
在日常的生活中,往往需要快速地從海量頁面信息中定位頁面資源。這樣的需求就需要用索引技術(shù)來實(shí)現(xiàn)。索引建立的好壞直接影響搜索效果和用戶的體驗感覺,所以索引的建立方法十分重要。Lucene采用倒排索引算法建立索引[2],主要包括索引類(IndexWriter)、文檔對象類(Document)和信息字段對象類(Field)。索引建立的過程為:
(1)建立索引器IndexWriter;
(2)建立文檔對象Document;
(3)建立信息字段對象Field;
(4)將Field添加到Document;
(5)將Document添加到IndexWriter里面;
(6)關(guān)閉索引器IndexWriter。
Lucene將建好的索引信息存儲在“_0.cfs”、“segments.gen”以及“segments_s”文件中。
3.2.4 信息搜索
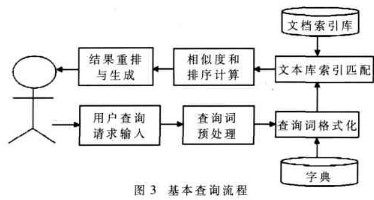
用戶提交的查詢請求通常是一個詞語或者短語,MYSearch搜索引擎在接受用戶訪問后會進(jìn)行一系列處理并最終向用戶提交。當(dāng)用戶輸入關(guān)鍵詞搜索后,由搜索程序從索引數(shù)據(jù)庫中找到符合該關(guān)鍵詞的所有相關(guān)文檔。因為所有文檔針對該關(guān)鍵詞的相關(guān)度早已算好,所以只需按照現(xiàn)成的相關(guān)度數(shù)值排序。排序規(guī)則是相關(guān)度越高,排名就越靠前。然后,就會把查詢到的信息返回給用戶,并進(jìn)行顯示。基本查詢流程如圖3所示。
3.2.5 搜索結(jié)果顯示
良好的交互設(shè)計可以使用戶的操作更加簡便,可以使用戶能夠更快更準(zhǔn)確地找到自己想要的信息,同時能夠增加用戶的滿意度。MYSearch全文搜索引擎設(shè)計了一個簡捷的搜索界面,用戶在該界面中輸入搜索條件,提交后就可以看到查詢結(jié)果。
4 改進(jìn)
搜索引擎(search engine)是指根據(jù)一定的策略、運(yùn)用特定的計算機(jī)程序從互聯(lián)網(wǎng)上搜集信息,在對信息進(jìn)行組織和處理后,為用戶提供檢索服務(wù),將用戶檢索相關(guān)的信息展示給用戶的系統(tǒng)。分詞就是為生成索引提供原材料,如果分詞分得不明確,則生成的索引必然復(fù)雜,那些沒有實(shí)際意義的分詞被稱為噪音,噪音多了搜索速度必然下降。Lucene其實(shí)自身是帶有中文分詞功能的,主要采用“單字切分”和“二分法”,但是由于它沒有做到確定最小索引項,因此無法去除噪音,搜索效率大大降低。IK_Canalyzer中文分析器是第三方實(shí)現(xiàn)的分析器,繼承自Lucene的Analyzer類。圖4(a)和圖4(b)分別為采用Lucene與IK_Canalyer分詞的顯示結(jié)果,可明顯看出后者優(yōu)于前者。

全文索引引擎是名副其實(shí)的搜索引擎,國外代表有Google,國內(nèi)知名的百度搜索。它們從互聯(lián)網(wǎng)提取各個網(wǎng)站的信息(以網(wǎng)頁文字為主),建立起數(shù)據(jù)庫,并能檢索與用戶查詢條件相匹配的記錄,按一定的排列順序返回結(jié)果。
MYSearch是基于Lucene設(shè)計實(shí)現(xiàn)的一個全文搜索引擎,本文給出了設(shè)計過程以及實(shí)驗結(jié)果,并針對Lucene在中文分詞方面的不足給出了解決辦法。此外目前可以獲得的Lucene開源代碼中并沒有對PDF、Word、Excel等常用的文本格式進(jìn)行搜索。要想克服上述問題,就要對不同格式的文本進(jìn)行解析,把解析出來的文字提取出純文本,然后就像建立網(wǎng)頁的索引一樣,對提出來的文字建立索引,以便查詢。這將是進(jìn)一步需要改進(jìn)MYSearch全文搜索引擎的工作重點(diǎn)。
根據(jù)搜索結(jié)果的不同,全文搜索引擎可分為兩類:一類擁有自己的網(wǎng)頁抓取、索引、檢索系統(tǒng)(Indexer),有獨(dú)立的“蜘蛛”(Spider)程序、或爬蟲(Crawler)、或“機(jī)器人”(Robot)程序(這三種稱法意義相同),能自建網(wǎng)頁數(shù)據(jù)庫,搜索結(jié)果直接從自身的數(shù)據(jù)庫中調(diào)用,上面提到的Google和百度就屬于此類;另一類則是租用其他搜索引擎的數(shù)據(jù)庫,并按自定的格式排列搜索結(jié)果,如Lycos搜索引擎。
-
路由器
+關(guān)注
關(guān)注
22文章
3728瀏覽量
113705 -
引擎
+關(guān)注
關(guān)注
1文章
361瀏覽量
22547 -
代碼
+關(guān)注
關(guān)注
30文章
4779瀏覽量
68525
發(fā)布評論請先 登錄
相關(guān)推薦
[分享]最強(qiáng)山寨版搜索引擎震驚世界-熊熊搜索
參加搜索引擎營銷SEM培訓(xùn)的好處?
基于網(wǎng)格技術(shù)的并行搜索引擎
維、哈、柯全文搜索引擎檢索器的關(guān)鍵技術(shù)
基于壓縮后綴數(shù)組技術(shù)的搜索引擎
教育網(wǎng)BBS搜索引擎設(shè)計與實(shí)現(xiàn)
化工搜索引擎索引庫的研究和實(shí)現(xiàn)
開放源代碼的全文檢索引擎 Lucene
主題搜索引擎的研究
網(wǎng)絡(luò)搜索引擎,網(wǎng)絡(luò)搜索引擎的工作原理
基于JAVA技術(shù)的搜索引擎的研究與實(shí)現(xiàn)

垂直搜索引擎是什么_垂直搜索引擎有哪些
介紹五個具有高級功能的搜索引擎
蘋果自研的搜索引擎干的過谷歌嗎?
NAS下搭建linux命令搜索引擎教程





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論