

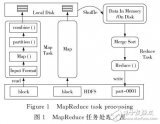
Web挖掘是針對包括Web頁面內容,頁面之間的結構,用戶訪問信息等在內的各種Web數據源。在一定基礎上應用數據挖掘的方法以發(fā)現(xiàn)有用的隱含的知識的過程。Web挖掘與傳統(tǒng)的數據挖掘相比有其自身的特點。Web本身是半結構化或無結構的數據,缺乏機器可理解的語義,Web挖掘的對象是大量,異質,分布的Web文檔,對Web服務器上的日志、用戶信息等數據所開展的挖掘工作也屬于Web數據挖掘的范疇。Web信息的多樣性決定了挖掘任務的多樣性。按照Web處理對象的不同,一般將Web挖掘分為3類: Web內容挖掘,Web結構挖掘和Web使用記錄挖掘(如圖1所示),針對這3種不同的處理對象,能夠挖掘出許多有用的信息。
Web日志挖掘現(xiàn)已成為Web挖掘研究的重點。其主要分為數據預處理、模式發(fā)現(xiàn)、模式分析3個階段[。數據預處理階段是要把從各種數據源得到的使用信息、內容信息和結構信息轉換成模式發(fā)現(xiàn)階段需要的數據抽象;模式發(fā)現(xiàn)階段旨在使用各種數據挖掘技術發(fā)掘隱藏在數據背后的規(guī)律和模式;模式分析階段旨在根據具體的實際應用,過濾掉在模式發(fā)現(xiàn)階段沒有用的規(guī)則或模式,并把有用的規(guī)則和模式轉換為知識。
本文主要研究數據預處理階段的會話識別。在分析現(xiàn)有的會話識別方法基礎上,提出一種基于訪問站點首頁和導航頁的改進會話識別方法,最后通過實驗驗證了改進的會話識別方法比現(xiàn)有方法更有效。
1 數據預處理
數據預處理是Web日志中最基礎、最頻繁的工作,是整個數據準備的核心工作。數據預處理的結果將直接影響到挖掘算法產生的規(guī)則和模式,因此預處理過程在整個Web日志挖掘過程中占據著非常重要的地位,是挖掘質量的保證。
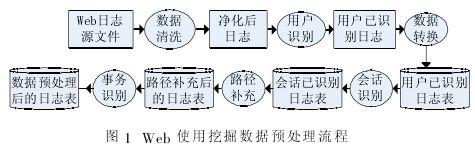
數據預處理包括數據清理、用戶識別、會話識別、路徑補充和事務識別5個階段。(1)數據清理是指刪除Web日志中與挖掘算法無關的數據;(2)用戶識別是識別出訪問網站的每個用戶;(3)會話識別是在用戶識別之后,把每個用戶在一段時間內的訪問序列進行分解,從而得到相應的會話。會話是指同一用戶在一次瀏覽過程中連續(xù)請求的頁面序列,它代表了用戶對服務器的一次有效訪問;(4)路徑補充是對識別出的用戶會話進行優(yōu)化的步驟,以使得其更加準確地描述用戶的瀏覽請求;(5)事務識別是將用戶會話進行語義分組,形成適合挖掘需要的事務。
2 會話識別分析
用戶會話[3]是指用戶從進入站點到離開站點期間所訪問的一系列頁面序列集合。可表示為:
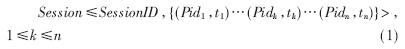
其中SessionID是會話標識,{(Pid1,t1)…(Pidk,tk)…(Pidn,tn)}是此次用戶會話的頁面訪問序列,Pid是訪問頁面的標識,t是訪問該頁面的時間。(Pid1,t1)表示用戶此次會話訪問的第一個頁面和時間,(Pidn,tn)表示用戶此次會話訪問的最后一個頁面和時間。
2.1 常用會話識別方法
目前常用會話識別方法主要有兩大類:一類是基于時間閾值,另一類是基于用戶訪問頁面時的參引頁面。基于時間閾值的會話識別方法又可細分為以下3類:
(1)設定會話的持續(xù)時間閾值θ。即一個會話總的持續(xù)時間不超過θ。國外學者Catledge和Pitkow由實驗得出θ設為25.5 min較好[4],許多商業(yè)產品都采用30 min作為缺省值。
(2)設定頁面的訪問時間閾值η[5]。假設(Pidi,ti)、(Pidi+1,ti+1)為一個用戶訪問序列中的兩條相鄰訪問記錄。只有當ti+1-ti≤η時,才認為這兩條記錄屬于同一個會話。當ti+1-ti>η時,(Pidi,ti)是上一次會話的最后一條訪問記錄,而(Pidi+1,ti+1)是新會話的第一條訪問記錄。一般η取10 min。
(3)上述方法(2)是對所有頁面設定同一個頁面訪問時間閾值,并沒有因頁面的不同而不同。參考文獻[6]中,根據統(tǒng)計的頁面的訪問時間,在正態(tài)分布的假設下為每個頁面設定一個訪問時間作為切分會話閾值,并結合頁面內容及站點結構來確定頁面重要程度,對該閾值進行調整。這是一種個性化的時間閾值設置方法。

2.2 常用會話識別方法評估
第(1)、(2)兩種方法使用單一時間閾值來識別用戶會話顯然是不合理的。方法(1)不能識別出訪問時間大于30 min的會話,且識別不出兩個連續(xù)較短的會話;方法(2)的不足在于,若一個用戶在訪問站點期間暫時離開電腦,但并沒有退出站點,過10 min后回來繼續(xù)瀏覽該站點,這實際上屬于同一個會話,而方法(2)則會錯誤地認為用戶開始了一個新的會話;方法(3)使用的統(tǒng)計學方法雖然大大減小了上限閾值,但仍然無法準確描述對頁面感興趣的用戶閱讀網頁的平均時間,無法區(qū)分超短時間用戶訪問記錄。
基于參引頁面的會話識別方法引入了時間限制?駐,主要是考慮到下面這種情況:訪問頁面的引用頁面為空,用戶可能是通過點擊瀏覽器上的”BACK”按鈕,回溯到之前某個曾經瀏覽過的頁面,進而訪問到該頁。這顯然也是不合理的,用戶從p頁面回退到上級頁面后,用戶要在此頁面搜尋到感興趣的p頁面,并點擊鏈接進入該頁面,所需時間一般不止10 s,且用戶可能是回退多次后再點擊鏈接進入p頁面。因此,此處設置這個時間閾值并不合理。
3 改進的會話識別方法
3.1 會話劃分思考
要準確地識別出用戶會話,關鍵在于識別出兩次相鄰會話的分割點。即上一次會話結束時訪問的頁面及下一次會話開始時訪問的頁面。而找出新會話開始時訪問的頁面,也就意味著上一會話的結束。因此,研究重點放在尋找標記新會話開始的訪問頁面。
用戶開始訪問某一站點,一般是通過在瀏覽器的地址欄中輸入站點的URL或是通過點擊收藏欄中的收藏,通過站點的首頁進入此站點的,此時用戶也就開始了自己的一次會話。在Web服務器日志中,可以查看用戶訪問的URL是否是首頁來判斷用戶的這種行為。當用戶瀏覽完畢退出該站點,此時會話結束,而在Web服務器端日志中,無法判斷這種用戶行為。但當該用戶下一次通過首頁來訪問站點時,在Web日志中發(fā)現(xiàn)用戶又鍵入了首頁URL,則很顯然上一次會話在本條記錄之前結束,本條記錄標志用戶開始了一個新的會話。
3.2 改進的會話識別方法
上述思想以訪問站點的首頁作為新會話開始的標記,基于這一前提用戶開始訪問站點時總是由站點首頁進入站點。但真實的訪問情況并不是所有的用戶每次開始訪問站點時都由首頁進入。一般的站點分若干版塊,而每一版塊都有自己的導航頁。如一門戶網站有新聞、體育、娛樂各版塊,有的用戶只對體育感興趣,那么他可能就會將體育版塊的導航頁做為收藏,每次訪問站點時,點擊收藏,直接進入體育導航頁開始訪問,而非先通過站點首頁,再進入體育版塊導航頁。因此,識別用戶會話,不能只以站點首頁作為開始標記,還應考慮各導航頁,因為很多用戶是直接通過導航頁訪問自己感興趣的頁面而非站點首頁。
改進的會話識別方法如圖1所示,以站點首頁或導航頁作為新會話開始的標識。
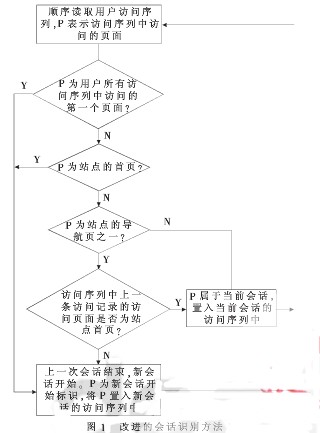
改進的會話識別方法具體描述如下:
(1)首先用戶訪問序列中的第一條訪問記錄是第一個會話的開始序列,置入第一個會話中;
(2)讀取用戶訪問序列中的下一條訪問記錄,直至序列中所有記錄都處理完畢;
(3)判斷本次訪問的頁面是否是站點的首頁,若是首頁,則當前會話結束,新會話開始,將該次訪問置入新會話的訪問序列中,然后轉步驟(2)處理下一條訪問記錄。否則,轉步驟(4);
(4)判斷本次訪問的頁面是否是站點的導航頁之一,若不是(即該頁面為內容頁),則將本次訪問置入當前會話的訪問序列中,然后轉步驟(2)繼續(xù)處理下一條訪問記錄。否則(即該頁面是導航頁之一),轉步驟(5)判斷它的上一條訪問記錄;
(5)判斷上一條訪問記錄,若上一條訪問記錄訪問的頁面是首頁,則本次訪問記錄和上次訪問記錄同屬一個會話;若上一條訪問記錄訪問的頁面不是首頁,則本次訪問就標識了新會話的開始,將其置入新會話的訪問序列中。轉步驟(2),處理下一條訪問記錄。
4 實驗與結果分析
4.1 實驗過程
4.1.1 數據準備
選用了安研星空站點http://www.ahusky.cn/從2009年2月17日至2009年3月5日的Web服務器日志,共計1 251 331條記錄,作為實驗數據,如圖2所示。

4.1.2 會話識別
將這些Web訪問日志通過SQL Loader載入Oracle數據庫中,經過數據清理,共有有效訪問記錄35 273條,存放在表log中,如圖3所示。

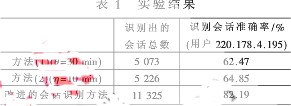
此處,以Web訪問日志中的IP地址作為用戶標識,利用Oracle PL/SQL編程實現(xiàn)上述改進的會話識別算法。為了與其他的會話識別方法進行比較,分別用2.1節(jié)中的方法(1)和方法(2)對同樣的Web日志進行會話識別,其中方法(1)取時間閾值30 min,方法(2)取時間閾值10 min。實驗結果如表1所示。
4.2 實驗分析
通過實驗發(fā)現(xiàn),改進的會話識別方法識別出的會話數(11 325條)要遠多于方法(1)(5 073條)和方法(2)(5 226條)。另外,為了比較這三種會話識別方法識別會話的準確率,將三種方法中識別出的關于用戶220.178.4.195的會話分別與原始的Web日志記錄比較,發(fā)現(xiàn)改進的會話識別方法識別會話的準確率(82.19%)也要高于方法(1)(62.47%)和方法(2)(64.85%)。由此可見,改進的會話識別方法能夠識別出更多的會話,且識別會話的準確率也更高。
數據預處理階段的會話識別為模式分析階段提供了挖掘數據,即每一個有效的用戶會話,因此它直接影響到模式分析階段能否發(fā)現(xiàn)有效的模式。本文提出的基于站點首頁和導航頁的改進會話識別方法能識別出更多的會話,識別會話的準確率更高。
5 結束語
進一步的工作我們可以將Web訪問日志的挖掘和其他的Web內容和Web鏈接結構挖掘結合起來用于Web頁面的等級劃分、Web文檔的分類和多層次Web信息庫的構造等方面,總之對Web數據進行進一步的數據挖掘是非常有意義的。當然,數據挖掘所帶來的好處,是與用戶的需求及數據挖掘技術本身的發(fā)展相關的。從而提供更好的服務。
-
服務器
+關注
關注
12文章
9620瀏覽量
87086 -
編程
+關注
關注
88文章
3674瀏覽量
94748 -
機器
+關注
關注
0文章
790瀏覽量
41087
發(fā)布評論請先 登錄
基于用戶會話數據的Web測試方法
基于訪問路徑的WEB事務聚類改進方法
Web結構挖掘中HITS算法改進的研究
硬盤標識識別方法
電容的識別方法
電容識別方法及換算
基于MapReduce的新會話識別方法
Web使用挖掘中的數據預處理模塊、實現(xiàn)方法及發(fā)展前景





 工商網監(jiān)
工商網監(jiān)

評論