") 基于XML技術與JAVA的醫(yī)生診療數(shù)據(jù)挖掘系統(tǒng)模型ARFDW的實現(xiàn)方案
基于XML技術與JAVA的醫(yī)生診療數(shù)據(jù)挖掘系統(tǒng)模型ARFDW的實現(xiàn)方案
引言
數(shù)據(jù)挖掘從20世紀80年代提出到現(xiàn)在,不過短短20多年的時間,但其應用已非常廣泛,不僅用于科研領域,在商業(yè)領域的應用也毫不遜色,尤其是用于銀行、電信、保險、交通、零售(如超級市場)等領域。數(shù)據(jù)挖掘在醫(yī)學領域的應用也有著廣泛的前景。在醫(yī)學領域存在著大量的數(shù)據(jù),包括病人病史、診斷、檢驗、和治療的臨床信息,藥品管理信息,醫(yī)院管理信息等。數(shù)據(jù)挖掘應用到醫(yī)學領域,對醫(yī)學數(shù)據(jù)進行分析,提取隱含的有價值的信息能夠促進醫(yī)院管理者作出明智決策、醫(yī)生對病人的正確診斷和治療。這對促進人類健康、保持健康的生活質(zhì)量都有積極的意義。
1 基于關聯(lián)規(guī)則數(shù)據(jù)挖掘技術分析
1.1 數(shù)據(jù)挖掘概述
1.1.1 數(shù)據(jù)挖掘的定義
數(shù)據(jù)挖掘就是從大量的、不完全的、有噪聲的、模糊的、隨機的數(shù)據(jù)中,提取隱含在其中的、人們事先不知道的、但又是潛在的有用信息和知識的過程。這個定義包含幾層含義,數(shù)據(jù)源必須是真實的、大量的、含噪聲的;發(fā)現(xiàn)的是用戶感興趣的知識;發(fā)現(xiàn)的知識要可接受、可理解、可運用;并不要求發(fā)現(xiàn)放之四海而皆準的知識,僅需支持特定的發(fā)現(xiàn)問題。
1.1.2 數(shù)據(jù)挖掘的過程
數(shù)據(jù)挖掘過程一般需要經(jīng)歷數(shù)據(jù)準備、數(shù)據(jù)開采、結果表述和解釋三個主要步驟。
(1)數(shù)據(jù)準備。數(shù)據(jù)準備是數(shù)據(jù)挖掘中的一個重要步驟,數(shù)據(jù)準備是否做好將直接影響到數(shù)據(jù)挖掘的效率、準確度以及最終模式的有效性。這個階段又可以進一步分為三個子步驟:數(shù)據(jù)集成、數(shù)據(jù)選擇、數(shù)據(jù)預處理。
(2)數(shù)據(jù)開采。數(shù)據(jù)開采階段選定某個特定的數(shù)據(jù)挖掘算法(如關聯(lián)規(guī)則、分類、回歸、聚類等算法),用于搜索數(shù)據(jù)中的模式。這是數(shù)據(jù)挖掘過程中最關鍵的一步,也是技術難點。
(3)結果表述和解釋。根據(jù)最終用戶的決策目的,對提取的信息進行分析,把最有價值的信息區(qū)分出來,并且通過決策支持工具提交給決策者。因此,這一步驟的任務不僅是把結果表達出來,還要對信息進行過濾處理。如果不能令決策者滿意,需要重復以上的數(shù)據(jù)挖掘過程。
1.2 關聯(lián)規(guī)則概述
給定一個事務(交易)數(shù)據(jù)庫,人們往往希望發(fā)現(xiàn)事務中的關聯(lián)事實,即事務中一些項目的出現(xiàn)必定隱含著同次事務中其他項目的出現(xiàn),這是關聯(lián)規(guī)則的一個簡單的描述。
設I ={t1,t2 ,-,tm} 是由m 個不同項目組成的集合,D 是交易數(shù)據(jù)庫(交易數(shù)據(jù)庫又稱事務數(shù)據(jù)庫),其中每一個交易或事務T 是I 中一些項目的集合,即T- I.每一個交易或事務T 都與一個惟一的標識符TID 相聯(lián)。
對于項目集X-I,如果X-T,則交易或事務T 支持X.
如果X 中有k 個項目,則又稱X 為k- 項目集,或X 的長度為k.
關聯(lián)規(guī)則是指形式如下的一種數(shù)據(jù)隱含關系:X -Y,其中X - I,Y-I,且X-Y = -.
關聯(lián)規(guī)則挖掘的任務是:在給定的交易或事務數(shù)據(jù)庫D 中,發(fā)現(xiàn)D 中所有的頻繁關聯(lián)規(guī)則。所謂頻繁關聯(lián)規(guī)則是指這些規(guī)則的支持度、置信度分別不低于用戶給定的最小支持度和最小置信度。
2 ARFDW 系統(tǒng)設計與實現(xiàn)
2.1 ARFDW系統(tǒng)框架需求分析
作為通用的數(shù)據(jù)挖掘框架,ARFDW 要提供對不同操作系統(tǒng)、不同處理平臺的支持;對異構數(shù)據(jù)源的支持;支持多樣化、可插拔、可組合的數(shù)據(jù)轉(zhuǎn)換功能;提供統(tǒng)一的管理和調(diào)度功能;處理程序的繼承和開放性;要有清晰的框架處理層次以及對元數(shù)據(jù)的管理等。下面對框架的關鍵需求進行描述。
2.1.1 建立挖掘主題
系統(tǒng)應該支持挖掘主題的建立。在對被挖掘?qū)ο筮M行充分分析并確定挖掘主題及數(shù)據(jù)后,系統(tǒng)能夠通過挖掘主題配置工具來創(chuàng)建挖掘主題及關聯(lián)維度,并生成相應數(shù)據(jù)庫表及數(shù)據(jù)記錄映射對象。
2.1.2 異構數(shù)據(jù)源數(shù)據(jù)抽取
作為通用框架,系統(tǒng)應該支持盡可能多的異構數(shù)據(jù)源,異構數(shù)據(jù)源包括不同廠商、不同版本的數(shù)據(jù)庫,不同格式的文本等。如ODBC 數(shù)據(jù)源、(非ODBC)各種關系型數(shù)據(jù)庫數(shù)據(jù)源、應用數(shù)據(jù)、電子商務數(shù)據(jù)、各種文件格式中數(shù)據(jù)等;同時提供通用數(shù)據(jù)訪問接口:該接口能夠跨平臺、網(wǎng)絡訪問數(shù)據(jù),支持在不同類型數(shù)據(jù)源間建立連接,通過它可以屏蔽各種數(shù)據(jù)源之間的差異,為后序工作提供一個統(tǒng)一的數(shù)據(jù)視圖。
2.1.3 建立轉(zhuǎn)換規(guī)則
由于業(yè)務系統(tǒng)的開發(fā)一般會有一個較長的時間跨度,這就造成同一種數(shù)據(jù)在業(yè)務系統(tǒng)中可能會有多種完全不同的存儲格式。這就要求ETL工具必須對抽取到的數(shù)據(jù)能進行靈活的計算、合并、拆分等轉(zhuǎn)換操作,系統(tǒng)要能夠不斷地以插件形式添加轉(zhuǎn)換節(jié)點的種類,就可以不斷地增強ETL工具的功能,以應付各種各樣的數(shù)據(jù)不一致的問題。
2.1.4 執(zhí)行定時任務
針對數(shù)據(jù)源的多樣性和可變性,ETL通過對從數(shù)據(jù)源到目標數(shù)據(jù)倉庫間的映射規(guī)則進行元數(shù)據(jù)級別上的建模,使得整個抽取、轉(zhuǎn)換、裝載過程在元數(shù)據(jù)驅(qū)動下能完全自動調(diào)度執(zhí)行,同時也便于維護和擴展。
2.2 ARFDW總體框架設計
ARFDW 系統(tǒng)架構模型如圖1 所示。首先,對被挖掘?qū)ο筮M行充分分析,確定挖掘主題及數(shù)據(jù),通過挖掘主題配置工具創(chuàng)建挖掘主題及關聯(lián)維度,并生成相應數(shù)據(jù)庫表及數(shù)據(jù)記錄映射對象;其次,通過數(shù)據(jù)源配置工具對等待抽取的數(shù)據(jù)源數(shù)據(jù)的相關連接格式參數(shù)進行配置,數(shù)據(jù)源配置好后系統(tǒng)會將輸入的數(shù)據(jù)通過數(shù)據(jù)對象化工具轉(zhuǎn)換為統(tǒng)一的XML 描述數(shù)據(jù)格式,并根據(jù)映射在基礎數(shù)據(jù)庫中創(chuàng)建數(shù)據(jù)保存表記錄;再次,通過轉(zhuǎn)換任務元數(shù)據(jù)配置工具生成數(shù)據(jù)轉(zhuǎn)換規(guī)則及對應目標主題,該部分實現(xiàn)需要用到功能節(jié)點以及設定任務中各個功能節(jié)點的執(zhí)行流程。配置好的任務將在任務列表中列出,可以手動執(zhí)行,也可以通過總控調(diào)度配置自動執(zhí)行。數(shù)據(jù)經(jīng)過ETL處理后會加載到挖掘庫對應的主題中去。最后,通過基于關聯(lián)規(guī)則的挖掘算法對目標數(shù)據(jù)進行挖掘,并將條件的規(guī)則保存到規(guī)則庫。
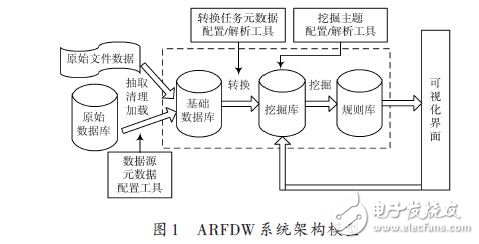
2.3 ARFDW框架實現(xiàn)
整個系統(tǒng)框架結構按照分層設計、實現(xiàn)。現(xiàn)對關鍵層的實現(xiàn)進行逐一描述。
數(shù)據(jù)持久層采用Hibernate,負責存儲、更新、刪除數(shù)據(jù)庫記錄等。Hibernate是一個用來處理O/R Mapping的持久層框架。技術本質(zhì)上是一個提供數(shù)據(jù)庫服務的中間件,該中間件屏蔽了不同數(shù)據(jù)庫之間的差異。它的工作原理是通過文件把值對象和數(shù)據(jù)庫表之間建立起一個映射關系,這樣,只需要通過操作這些值對象和Hibernate提供的一些基本類,就可以達到使用數(shù)據(jù)庫的目的。
Hibernate 使用數(shù)據(jù)庫和配置信息來為應用程序提供持久化服務(以及持久的對象)。在這里,創(chuàng)建了接口IdaoSupport,該接口定義了所有對數(shù)據(jù)庫進行的原子操作,DaoSupportHibernate3Imp 是其實現(xiàn)類,該類繼承了HibernateDaoSupport類,通過調(diào)用該類提供的方法來完成對數(shù)據(jù)庫的操作。
業(yè)務邏輯層采用Spring.Spring框架是一個分層架構,它的核心提供了一個管理業(yè)務對象以及它們之間依賴關系的方法。例如,應用控制反轉(zhuǎn)(IOC),它可以特定一個數(shù)據(jù)訪問對象(DAO)去依賴于某一個數(shù)據(jù)源。
同時,它允許開發(fā)者實現(xiàn)接口并在XML 文件中去定義其實現(xiàn)類。同時為了避免EJB的高度侵入性,實現(xiàn)無侵入性的目標,Spring 大量引入了JAVA 的Reflection 機制,通過動態(tài)調(diào)用的方式避免硬編碼方式的約束,并在此基礎上建立了其核心組件BeanFactory,以此作為其依賴注入機制的實現(xiàn)基礎。
表示層采用基于MVC模式的Struts框架。MVC(模型-視圖-控制)設計模式將WEB層分為三類對象:代表數(shù)據(jù)的模型(Model)對象,顯示模型的視圖(View)對象以及響應用戶輸入、處理業(yè)務流程的控制器(Controller)對象。
整個系統(tǒng)處理流程如下:
(1)當系統(tǒng)第一次啟動時,應用會根據(jù)部署描述文件Web.xml指向的applicationContext.xml中定義的內(nèi)容初始化數(shù)據(jù)庫連接池、進行O-R Mapping映射、根據(jù)IoC實例化業(yè)務邏輯類。
(2)操作員登陸時,進行相應的權限驗證,如果驗證通過,則初始化單例對象(InitSingleton),該對象保存了一些全局實例,用戶信息、角色信息、權限信息等。
(3)操作員通過系統(tǒng)界面(JSP)提交業(yè)務請求(業(yè)務信息保存在FormBean中),并通過struts-config.xml中的描述定位到控制器(Action),業(yè)務請求包括:業(yè)務編號、當前步驟、執(zhí)行動作等。
(4)控制器接收用戶請求,將FormBean中的信息傳遞到BO中,同時調(diào)用權限驗證模塊(RightControl)進行操作員權限驗證。權限驗證接口判斷當前用戶對于請求的業(yè)務是否具有權限(只讀、可寫),將結果反饋給控制器。
(5)如果驗證通過,控制器將根據(jù)用戶請求信息,調(diào)用系統(tǒng)啟動時實例化的業(yè)務邏輯類進行相應業(yè)務處理。
(6)業(yè)務處理邏輯對象處理特定業(yè)務邏輯,當需要CRUD(即Create、Read、Update、Delete)時,會根據(jù)appli-cationContext.xml中通過set方法注入的DAO實例,執(zhí)行相應的CRUD操作。
(7)業(yè)務處理完成后,控制器根據(jù)返回結果,將用戶頁面導向特定JSP,如果有需要,將返回的結果封裝成FormBean(與用戶界面相對應的JavaBean,其屬性與用戶界面元素相對應)一并返回特定JSP.
3 結語
課題根據(jù)目前國內(nèi)外數(shù)據(jù)集成工具暴露出的問題,及目前醫(yī)生診療數(shù)據(jù)挖掘的現(xiàn)狀、技術及特點提出了ARFDW 自適應模型框架的概念。該框架使用JAVA語言、對象持久化技術和XML技術構建出跨平臺、多線程并發(fā)運行、支持增量數(shù)據(jù)更新、靈活的數(shù)據(jù)挖掘系統(tǒng)架構模型,并給出了設計和實現(xiàn)方案。
-
數(shù)據(jù)
+關注
關注
8文章
7006瀏覽量
88949 -
JAVA
+關注
關注
19文章
2966瀏覽量
104704 -
XML
+關注
關注
0文章
188瀏覽量
33079
發(fā)布評論請先 登錄
相關推薦
JAVA專家末端網(wǎng)絡
JAVA技術專家末端網(wǎng)絡
數(shù)據(jù)挖掘算法有哪幾種?
XML和VR技術在GIS中數(shù)據(jù)互操作設計與實現(xiàn)
生產(chǎn)調(diào)度系統(tǒng)中的XML通訊模型及實現(xiàn)
基于XML的WEB信息抽取模型設計
XML快速關聯(lián)規(guī)則挖掘算法的研究
中醫(yī)毒熱數(shù)據(jù)挖掘系統(tǒng)的設計與實現(xiàn)
基于XML技術的企業(yè)數(shù)據(jù)集成模型研究
數(shù)據(jù)挖掘技術在入侵檢測系統(tǒng)中的實現(xiàn)
基于XML的多方數(shù)據(jù)通信安全模型研究
XML數(shù)據(jù)相似度研究
概率XML數(shù)據(jù)模型的綜述
Java解析XML的一種數(shù)據(jù)綁定技術
Java中的XML與內(nèi)容管理






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論