 WEB應用安全領域的現狀與應用研究
WEB應用安全領域的現狀與應用研究
研究背景
WEB應用安全現狀
隨著互聯網的發展,金融網上交易、政府電子政務、企業門戶網站、社區論壇、電子商務等各類基于HTML文件格式的信息共享平臺(WEB應用系統)越發完善,深入到人們生活中的點點滴滴。然而WEB應用共享平臺為我們的生活帶來便利的同時,也面臨著前所未有的挑戰:WEB應用系統直接面向Internet,以WEB應用系統為跳板入侵服務器甚至控制整個內網系統的攻擊行為已成為最普遍的攻擊手段。
據中國互聯網應急中心最新統計顯示,2009年我國大陸地區政府網頁遭篡改事件呈大幅增長趨勢,被篡改網站的數量就達到52225個。2009年8月份,公安部對國內政府網站的進行安全大檢查,發現40%存在嚴重安全漏洞,包括SQL注入、跨站腳本漏洞等。由此導致的網頁篡改、網頁掛馬、機密數據外泄等安全事件頻繁發生,不但嚴重影響對外形象,有時甚至會造成巨大的經濟損失,或者嚴重的社會問題,嚴重危及國家安全和人民利益。
網頁篡改:一些不法分子的重點攻擊對象。組織門戶網站一旦被篡改引發較大的影響,嚴重甚至造成政治事件。
網頁掛馬:網頁掛馬指的是把一個木馬程序上傳到一個網站里面然后用木馬生成器生一個網馬,再上到空間里面,再加代碼使得木馬在打開網頁是運行。網頁掛馬未必會給網站帶來直接損害,但卻會給瀏覽網站的用戶帶來巨大損失。網站一旦被掛馬,其權威性和公信力將會受到打擊。
作為網頁掛馬的散布者,其目的是將木馬下載到用戶本地,并進一步執行,當木馬獲得執行之后,就意味著會有更多的木馬被下載,進一步被執行,進入一個惡性的循環,從而使用戶的電腦遭到攻擊和控制。為達到目的首先要將木馬下載到本地。機密數據外泄:在線業務系統中,總是需要保存一些企業、公眾的相關資料,這些資料往往涉及到企業秘密和個人隱私,一旦泄露,會造成企業或個人的利益受損,可能會給單位帶來嚴重的法律糾紛。
傳統安全防護方法
企業 WEB 應用的各個層面,都已使用不同的技術來確保安全性。為了保護客戶端機器的安全,用戶會安裝防病毒軟件;為了保證用戶數據傳輸到企業 WEB 服務器的傳輸安全,通信層通常會使用 SSL技術加密數據;防火墻和 IDS/IPS來保證僅允許特定的訪問,不必要暴露的端口和非法的訪問,在這里都會被阻止;同時企業采用一定的身份認證機制授權用戶訪問 WEB 應用。
SSL加密技術為了保護敏感數據在傳送過程中的安全,全球許多知名企業采用SSL(Security Socket Layer)加密機制。 SSL是Netscape公司所提出的安全保密協議,在瀏覽器(如Internet Explorer、Netscape Navigator)和Web服務器(如Netscape的Netscape Enterprise Server、ColdFusion Server等等)之間構造安全通道來進行數據傳輸,SSL運行在TCP/IP層之上、應用層之下,為應用程序提供加密數據通道,它采用了RC4、MD5以及RSA等加密算法,使用40 位的密鑰,適用于商業信息的加密。同時,Netscape公司相應開發了HTTPS協議并內置于其瀏覽器中,HTTPS實際上就是HTTP over SSL,它使用默認端口443,而不是像HTTP那樣使用端口80來和TCP/IP進行通信。HTTPS協議使用SSL在發送方把原始數據進行加密,然后在接受方進行解密,加密和解密需要發送方和接受方通過交換共知的密鑰來實現,因此,所傳送的數據不容易被網絡黑客截獲和解密。
但是,即便有防病毒保護、防火墻和 IDS/IPS,企業仍然不得不允許一部分的通訊經過防火墻,保護措施可以關閉不必要暴露的端口,但是 WEB 應用所必須的端口,必須開放。順利通過的這部分通訊,可能是善意的,也可能是惡意的,很難辨別。同時,WEB 應用是由軟件構成的,那么,它一定會包含漏洞,這些漏洞可能被惡意的用戶利用,他們通過執行各種惡意的操作,或者偷竊、或者操控、或者破壞 WEB 應用中的重要信息。
本文研究觀點
網站是否存在WEB 應用程序漏洞,往往是被入侵后才能察覺;如何在攻擊發動之前主動發現WEB應用程序漏洞。答案就是:主動防御,即利用WEB應用弱點掃描技術,主動實現對WEB應用的安全防護。
本文主要針對B/S架構WEB應用系統中典型漏洞、流行的攻擊技術、AJAX的隱藏資源獲取、驗證碼圖片識別等進行研究,提出了一種新的面向WEB的漏洞檢測技術,能夠較完整得提取出AJAX的資源,有效識別驗證碼。
B/S(Browser/Server)結構即瀏覽器和服務器結構。它是隨著Internet技術的興起,對C/S結構的一種變化或者改進的結構。在這種結構下,用戶工作界面是通過WWW瀏覽器來實現,極少部分事務邏輯在前端(Browser)實現,但是主要事務邏輯在服務器端(Server)實現,形成所謂三層3-tier結構。相對于C/S結構屬于“胖”客戶端,需要在使用者電腦上安裝相應的操作軟件來說,B/S結構是屬于一種“瘦”客戶端,大多數或主要的業務邏輯都存在在服務器端,因此,B/S結構的系統不需要安裝客戶端軟件,它運行在客戶端的瀏覽器之上,系統升級或維護時只需更新服務器端軟件即可,這樣就大大簡化了客戶端電腦載荷,減輕了系統維護與升級的成本和工作量,降低了用戶的總體成本(TCO)。 B/S結構系統的產生為系統面對無限未知用戶提供了可能。當然,與C/S結構相比,B/S結構也存在著系統運行速度較慢,訪問系統的用戶不可控的弱點。
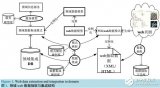
WEB應用風險掃描架構
WEB應用風險掃描技術架構主要分為URL獲取層、檢測層、取證與深度評估層三個層次,其中:
URL獲取層:主要通過網絡爬蟲方式獲取需要檢測的所有URL,并提交至檢測層進行風險檢測;
風險檢測層:對URL獲取層所提交的所有URL頁面進行SQL注入、跨站腳本、文件上傳等主流WEB應用安全漏洞進行檢測,并將存在安全漏洞的頁面和漏洞類型提交至取證與深度評估層;
取證與深度評估層:針對存在安全漏洞的頁面,進行深度測試,獲取所對應安全漏洞的顯性表現,(如風險檢測層檢測出該網站存在SQL注入漏洞,則至少需可獲取該網站的數據庫類型);作為該漏洞存在的證據。
網絡爬蟲技術—URL獲取
網絡爬蟲(又被稱為網頁蜘蛛,網絡機器人,在FOAF社區中間,更經常的稱為網頁追逐者),是一種按照一定的規則,自動的抓取萬維網信息的程序或者腳本。另外一些不常使用的名字還有螞蟻,自動索引,模擬程序或者蠕蟲。它通過指定的域名,從一個或若干初始網頁的URL開始,獲得初始網頁上的URL,在抓取網頁的過程中,不斷從當前頁面上抽取新的URL放入隊列,直到滿足系統的一定停止條件。
網絡爬蟲是一個自動提取網頁的程序,它為搜索引擎從萬維網上下載網頁,是搜索引擎的重要組成。傳統爬蟲從一個或若干初始網頁的URL開始,獲得初始網頁上的URL,在抓取網頁的過程中,不斷從當前頁面上抽取新的URL放入隊列,直到滿足系統的一定停止條件。聚焦爬蟲的工作流程較為復雜,需要根據一定的網頁分析算法過濾與主題無關的鏈接,保留有用的鏈接并將其放入等待抓取的URL隊列。然后,它將根據一定的搜索策略從隊列中選擇下一步要抓取的網頁URL,并重復上述過程,直到達到系統的某一條件時停止。另外,所有被爬蟲抓取的網頁將會被系統存貯,進行一定的分析、過濾,并建立索引,以便之后的查詢和檢索;對于聚焦爬蟲來說,這一過程所得到的分析結果還可能對以后的抓取過程給出反饋和指導。
網絡爬蟲的工作流程較為復雜,首先根據一定的網頁分析算法過濾與主題無關的鏈接,保留有用的鏈接并將其放入等待抓取的URL隊列。然后,根據搜索策略從隊列中選擇下一步要抓取的網頁URL,并重復,直到達到預設的停止條件。另外,所有被爬蟲抓取的網頁將會被系統存貯,進行一定的分析、過濾,并建立索引,以便之后的查詢、檢索和取證及報表生成時做為源數據。
為了更加高速、有效地獲取網站中所有的URL鏈接,在本WEB應用風險掃描技術研究中,所采用的網絡爬蟲技術著重解決以下三個問題:
(1) 對抓取目標的描述或定義;
(2) 對網頁和數據的分析與過濾;
(3) 對URL的搜索策略。
網頁抓取目標
網頁弱點爬蟲對抓取目標的描述或定義基于目標網頁特征抓取、存儲并索引,對象是網站的網頁;通過用戶行為確定的抓取目標樣例,其中,網頁特征可以是網頁的內容特征,也可以是網頁的鏈接結構特征,以及網頁代碼的結構特征等。
網頁分析算法
基于網頁內容的分析算法指的是利用網頁內容特征進行的網頁評價。該算法從原來的較為單純的文本檢索方法,發展為涵蓋網頁數據抽取、機器學習、數據挖掘、語義理解等多種方法的綜合應用。根據網頁數據形式的不同,將基于網頁內容的分析算法,歸納以下三類:第一種針對以文本和超鏈接為主的無結構或結構很簡單的網頁;第二種針對從結構化的數據源動態生成的頁面,其數據不能直接批量訪問;第三種針對的數據界于第一和第二類數據之間,具有較好的結構,顯示遵循一定模式或風格,且可以直接訪問。
網頁抓取策略
網頁抓取主要有三個方面:1、搜集新出現的網頁:2搜集那些在上次搜集后有改變的網頁:3發現自從上次搜集后已經不再存了的網頁,并從庫中刪除。
爬蟲的抓取策略目前普遍的采用的方法有:深度優先、廣度優先、最佳優先三種。由于深度優先在很多情況下會導致爬蟲的陷入(trapped)問題,網頁弱點爬蟲目前采用的是深度優先和最佳優先方法組合方法。
深度優先搜索策略:指在抓取過程中,在完成當前層次的搜索后,才進行下一層次的搜索。網頁弱點爬蟲采用深度優先搜索方法為覆蓋指定網站存在弱點的網頁。其基本思想是認為與初始URL在一定鏈接距離內的網頁具有弱點相關性的概率很大;并采用將深度優先搜索與網頁過濾技術結合使用,先用深度優先策略抓取網頁,再將其中無關的網頁過濾掉。這些方法的缺點在于,隨著抓取網頁的增多,大量的無關網頁將被下載并過濾,算法的效率將變低。
最佳優先搜索策略:最佳優先搜索策略采用基于網頁內容的網頁分析算法,預測候選URL與目標網頁的相似度,或與主題的相關性,并選取評價最好的一個或幾個URL進行抓取。
漏洞檢測技術—風險檢測
主要WEB應用漏洞
OWASP十大安全威脅
開放式WEB應用程序安全項目是一個組織,它提供有關計算機和互聯網應用程序的公正、實際、有成本效益的信息。其目的是協助個人、企業和機構來發現和使用可信賴軟件。美國聯邦貿易委員會(FTC)強烈建議所有企業需遵循OWASP所發布的十大Web弱點防護守則、美國國防部亦列為最佳實務,國際信用卡資料安全技術PCI標準更將其列為必須采用有效措施進行針對性防范。
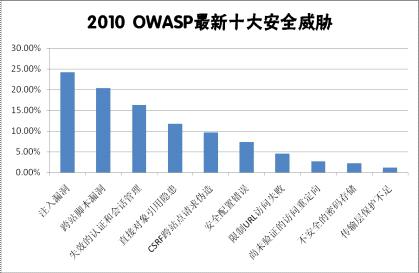
圖1 2010年OWASP十大安全威脅
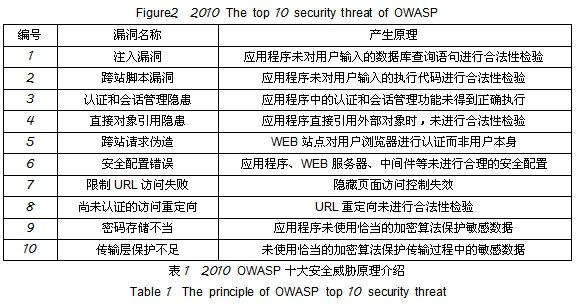
CWE/SANS 25大危險編程錯誤
一般弱點列舉(Common Weakness Enumeration CWE)是由美國國家安全局首先倡議的戰略行動,該行動的組織最近發布了《2010年CWE/SANS最危險的程序設計錯誤(PDF)》一文,其中列舉了作者認為最嚴重的25種代碼錯誤,同時也是軟件最容易受到攻擊的點。OWASP Top 10,所關注的是WEB應用程序的安全風險,而CWE的Top 25的覆蓋范圍更廣,包括著名的緩沖區溢出缺陷。
WEB應用漏洞規則庫
我們經過多年WEB應用安全領域的研究,結合國內外優秀組織的經典總結、描述以及驗證,建立起一套幾乎涵蓋所有可能帶來安全威脅的WEB應用安全漏洞的豐富的WEB應用漏洞規則庫,包括各個安全漏洞的產生原理、檢測規則、可能危害、漏洞驗證等等,通過自動化手段,對網絡爬蟲所獲取到的網站頁面進行逐一檢測。隨著安全漏洞的不斷產生、攻擊手段的不斷演變,WEB應用漏洞規則庫也不斷獲得充實和改進。
模擬滲透測試—取證與深度評估
模擬滲透測試
通常我們所理解的滲透測試,是指具有豐富安全經驗的安全專家,在對目標系統一無所知的情況下,通過收集系統信息,進行具有針對性的安全攻擊和入侵,獲取系統管理權限、敏感信息的一個過程。這包括三個要素:豐富安全經驗的安全專家(人)、系統漏洞(漏洞檢測)、權限獲取或信息獲取(取證)。由于組織內部一般并不具備具有專業滲透技術的安全專家,所以通常依靠于第三方安全公司。
結合大量優秀安全專家的滲透測試經驗,以及對各類WEB應用安全漏洞的顯性分析(即如果存在該漏洞,其具體表現是什么),在完成網站中各個頁面的漏洞檢測后,對所存在的安全漏洞進行驗證,即獲取相應的權限或信息,達到模擬滲透測試的效果,不僅可以大大降低漏洞檢測的誤報率,準確呈現該漏洞的存在和取證;而且可以在一定程度上替代第三方的滲透測試人員,自主進行安全掃描,降低信息泄露的風險。
安全漏洞取證分析
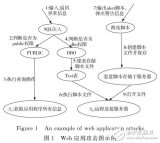
對安全漏洞的取證分析,在此以SQL注入漏洞為例進行簡要描述。
SQL注入類型根據原理可以分為以下幾類:數值型、字符型、搜索型、錯誤型、雜項型。在檢測出相關注入漏洞后, 根據不同后臺數據庫, 采用不同的數據庫注入策略包來進行進一步的取證和滲透。圖2講述了SQL注入檢測的流程:通過網絡爬蟲獲取的URL,成為SQL注入檢測的輸入,通過圖2流程完成SQL注入、滲透和審計。
SQL是高級的非過程化編程語言,是溝通數據庫服務器和客戶端的重要工具,允許用戶在高層數據結構上工作。它不要求用戶指定對數據的存放方法,也不需要用戶了解具體的數據存放方式,所以,具有完全不同底層結構的不同數據庫系統,可以使用相同的SQL語言作為數據輸入與管理的。它以記錄集合作為操作對象,所有SQL語句接受集合作為輸入,返回集合作為輸出,這種集合特性允許一條SQL語句的輸出作為另一條SQL語句的輸入,所以SQL語句可以嵌套,這使他具有極大的靈活性和強大的功能,在多數情況下,在其他語言中需要一大段程序實現的功能只需要一個SQL語句就可以達到目的,這也意味著用SQL語言可以寫出非常復雜的語句。
-
互聯網
+關注
關注
54文章
11148瀏覽量
103234 -
服務器
+關注
關注
12文章
9123瀏覽量
85328 -
HTML
+關注
關注
0文章
278瀏覽量
35211
發布評論請先 登錄
相關推薦
基于DSP的圖像處理系統的應用研究
嵌入式Web技術在無紙記錄儀中的應用研究
智能家居的應用研究現狀 精選資料分享
Web應用安全評估
元宇宙相關技術在泛工業領域的應用研究

振弦采集儀在橋梁安全監測中的應用研究






 工商網監
工商網監
評論