

神經(jīng)風(fēng)格遷移是一項優(yōu)化技術(shù),可用于選取三幅圖像,即一幅內(nèi)容圖像、一幅風(fēng)格參考圖像(例如一幅名家作品),以及您想要設(shè)定風(fēng)格的輸入圖像,然后將它們?nèi)诤显谝黄穑@樣輸入圖像轉(zhuǎn)化后就會看起來與內(nèi)容圖像相似,但其呈現(xiàn)的是風(fēng)格圖像的風(fēng)格。
例如,我們選取一張烏龜?shù)膱D像和 Katsushika Hokusai 的《神奈川沖浪里》:
P. Lindgren 拍攝的《綠海龜》,圖像來自Wikimedia Commons
如果 Hokusai 決定將他作品中海浪的紋理或風(fēng)格添加到海龜圖像中,這幅圖看起來會是什么樣?會不會是這樣?
這是魔法嗎?又或者只是深度學(xué)習(xí)?幸運的是,這和魔法沒有任何關(guān)系:風(fēng)格遷移是一項好玩又有趣的技術(shù),可以展現(xiàn)神經(jīng)網(wǎng)絡(luò)的能力和內(nèi)部表現(xiàn)形式。
神經(jīng)風(fēng)格遷移的原理是定義兩個距離函數(shù),一個描述兩幅圖像的不同之處,即 Lcontent 函數(shù),另一個描述兩幅圖像的風(fēng)格差異,即 Lstyle 函數(shù)。然后,給定三幅圖像,一幅所需的風(fēng)格圖像、一幅所需的內(nèi)容圖像,還有一幅輸入圖像(用內(nèi)容圖像進行初始化)。我們努力轉(zhuǎn)換輸入圖像,借助內(nèi)容圖像將內(nèi)容距離最小化,并借助風(fēng)格圖像將風(fēng)格距離最小化。
簡而言之,我們會選取基本輸入圖像、我們想要匹配的內(nèi)容圖像以及想要匹配的風(fēng)格圖像。我們將使用反向傳播算法最小化內(nèi)容和風(fēng)格距離(損失),以轉(zhuǎn)換基本輸入圖像,創(chuàng)建與內(nèi)容圖像的內(nèi)容和風(fēng)格圖像的風(fēng)格相匹配的圖像。
下文要提及的特定概念有:
在此過程中,我們會圍繞下列概念積累實際經(jīng)驗,形成直覺認識:
Eager Execution— 使用 TensorFlow 的命令式編程環(huán)境,該環(huán)境可以立即評估操作
了解更多有關(guān) Eager Execution 的信息
查看動態(tài)教程(許多教程都可以在Colaboratory中運行)
使用功能 API來定義模型— 我們會構(gòu)建一個模型的子集,由其賦予我們使用功能 API 訪問必要的中間激活的權(quán)限
利用預(yù)訓(xùn)練模型的特征圖— 學(xué)習(xí)如何使用預(yù)訓(xùn)練模型及其特征圖
創(chuàng)建自定義訓(xùn)練循環(huán)— 我們會研究如何設(shè)置優(yōu)化器,以最小化輸入?yún)?shù)的既定損失
我們會按照下列常規(guī)步驟來進行風(fēng)格遷移:
可視化數(shù)據(jù)
對我們的數(shù)據(jù)進行基本的預(yù)處理/準備
設(shè)定損失函數(shù)
創(chuàng)建模型
優(yōu)化損失函數(shù)
實現(xiàn)
首先,我們要啟用Eager Execution。借助 Eager Execution,我們可以最清晰易讀的方式學(xué)習(xí)這項技術(shù)
1tf.enable_eager_execution()
2print("Eager execution: {}".format(tf.executing_eagerly()))
3
4Here are the content and style images we will use:
5plt.figure(figsize=(10,10))
6
7content = load_img(content_path).astype('uint8')
8style = load_img(style_path)
9
10plt.subplot(1, 2, 1)
11imshow(content, 'Content Image')
12
13plt.subplot(1, 2, 2)
14imshow(style, 'Style Image')
15plt.show()
P. Lindgren 拍攝的《綠海龜》圖,圖像來自Wikimedia Commons,以及 Katsushika Hokusai 創(chuàng)作的《神奈川沖浪里》,圖像來自公共領(lǐng)域
定義內(nèi)容和風(fēng)格表征
為了獲取我們圖像的內(nèi)容和風(fēng)格表征,我們先來看看模型內(nèi)的一些中間層。中間層代表著特征圖,這些特征圖將隨著您的深入變得越來越有序。在本例中,我們會使用 VGG19 網(wǎng)絡(luò)架構(gòu),這是一個預(yù)訓(xùn)練圖像分類網(wǎng)絡(luò)。要定義我們圖像的內(nèi)容和風(fēng)格表征,這些中間層必不可少。對于輸入圖像,我們會努力匹配這些中間層的相應(yīng)風(fēng)格和內(nèi)容的目標表征。
為什么是中間層?
您可能會好奇,為什么預(yù)訓(xùn)練圖像分類網(wǎng)絡(luò)中的中間輸出允許我們定義風(fēng)格和內(nèi)容表征。從較高的層面來看,我們可以通過這樣的事實來解釋這一現(xiàn)象,即網(wǎng)絡(luò)必須要理解圖像才能執(zhí)行圖像分類(我們的網(wǎng)絡(luò)已接受過這樣的訓(xùn)練)。這包括選取原始圖像作為輸入像素,并通過轉(zhuǎn)換構(gòu)建內(nèi)部表征,轉(zhuǎn)換就是將原始圖像像素變?yōu)閷D像中所呈現(xiàn)特征的復(fù)雜理解。這也可以部分解釋卷積神經(jīng)網(wǎng)絡(luò)為何能夠很好地概括圖像:它們能夠捕捉不同類別的不變性,并定義其中的特征(例如貓與狗),而且不受背景噪聲和其他因素的影響。因此,在輸入原始圖像和輸出類別標簽之間的某個位置,模型發(fā)揮著復(fù)雜特征提取器的作用。通過訪問中間層,我們可以描述輸入圖像的內(nèi)容和風(fēng)格。
具體而言,我們會從我們的網(wǎng)絡(luò)中抽取出這些中間層:
1# Content layer where will pull our feature maps
2content_layers = ['block5_conv2']
3
4# Style layer we are interested in
5style_layers = ['block1_conv1',
6'block2_conv1',
7'block3_conv1',
8'block4_conv1',
9'block5_conv1'
10]
11
12num_content_layers = len(content_layers)
13num_style_layers = len(style_layers)
模型
在本例中,我們將加載VGG19,并將輸入張量輸入模型中。這樣,我們就可以提取內(nèi)容圖像、風(fēng)格圖像和所生成圖像的特征圖(隨后提取內(nèi)容和風(fēng)格表征)。
依照論文中的建議,我們使用 VGG19 模型。此外,由于 VGG19 是一個較為簡單的模型(與 ResNet、Inception 等模型相比),其特征圖實際更適用于風(fēng)格遷移。
為了訪問與我們的風(fēng)格和內(nèi)容特征圖相對應(yīng)的中間層,我們需要使用 Keras功能 API來獲取相應(yīng)的輸出,從而使用所需的輸出激活定義我們的模型。
借助功能 API,定義模型時僅需定義輸入和輸出即可:model = Model(inputs, outputs)。
1def get_model():
2""" Creates our model with access to intermediate layers.
3
4This function will load the VGG19 model and access the intermediate layers.
5These layers will then be used to create a new model that will take input image
6and return the outputs from these intermediate layers from the VGG model.
7Returns:
8returns a keras model that takes image inputs and outputs the style and
9content intermediate layers.
10"""
11# Load our model. We load pretrained VGG, trained on imagenet data (weights=’imagenet’)
12vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet')
13vgg.trainable = False
14# Get output layers corresponding to style and content layers
15style_outputs = [vgg.get_layer(name).output for name in style_layers]
16content_outputs = [vgg.get_layer(name).output 17for name in content_layers]
18model_outputs = style_outputs + content_outputs
19# Build model
20return models.Model(vgg.input, model_outputs)
在上圖的代碼片段中,我們將加載預(yù)訓(xùn)練圖像分類網(wǎng)絡(luò)。然后,我們會抓取此前定義的興趣層。之后,我們將定義一個模型,將模型的輸入設(shè)置為圖像,將輸出設(shè)置為風(fēng)格層和內(nèi)容層的輸出。換言之,我們創(chuàng)建的模型將接受輸入圖像并輸出內(nèi)容和風(fēng)格中間層!
定義和創(chuàng)建我們的損失函數(shù)(內(nèi)容和風(fēng)格距離)
內(nèi)容損失:
我們的內(nèi)容損失定義實際上相當簡單。我們將向網(wǎng)絡(luò)傳遞所需的內(nèi)容圖像和基本輸入圖像,這樣,我們的模型會返回中間層輸出(自上文定義的層)。然后,我們只需選取這些圖像的兩個中間表征之間的歐氏距離。
更正式地講,內(nèi)容損失是一個函數(shù),用于描述內(nèi)容與我們的輸入圖像 x 和內(nèi)容圖像 p 之間的距離。設(shè) C?? 為預(yù)訓(xùn)練深度卷積神經(jīng)網(wǎng)絡(luò)。再次強調(diào),我們在本例中使用VGG19。設(shè) X 為任意圖像,則 C??(x) 為 X 饋送的網(wǎng)絡(luò)。用 F???(x)∈ C??(x) 和 P???(x) ∈ C??(x) 分別描述網(wǎng)絡(luò)在 l 層上輸入為 x 和 p 的中間層表征。之后,我們可以將內(nèi)容距離(損失)正式描述為:
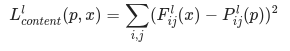
我們以常規(guī)方式執(zhí)行反向傳播算法,以便將內(nèi)容損失降至最低。這樣,我們可以更改初始圖像,直至其在某個層(在 content_layer 中定義)中生成與原始內(nèi)容圖像相似的響應(yīng)。
該操作非常容易實現(xiàn)。同樣地,在我們的輸入圖像 x 和內(nèi)容圖像 p 饋送的網(wǎng)絡(luò)中,其會將 L 層的輸入特征圖視為輸入圖像,然后返回內(nèi)容距離。
1def get_content_loss(base_content, target):
2return tf.reduce_mean(tf.square(base_content - target))
風(fēng)格損失:
計算風(fēng)格損失時涉及的內(nèi)容較多,但遵循相同的原則,這次我們要為網(wǎng)絡(luò)提供基本輸入圖像和風(fēng)格圖像。但我們要比較的是這兩個輸出的格拉姆矩陣,而非基本輸入圖像和風(fēng)格圖像的原始中間輸出。
在數(shù)學(xué)上,我們將基本輸入圖像 x 和風(fēng)格圖像 a 的風(fēng)格損失描述為這些圖像的風(fēng)格表征(格拉姆矩陣)之間的距離。我們將圖像的風(fēng)格表征描述為由格拉姆矩陣 G? 給定的不同過濾響應(yīng)間的相關(guān)關(guān)系,其中 G??? 為 l 層中矢量化特征圖 i 和 j 之間的內(nèi)積。我們可以看到,針對特定圖像的特征圖生成的 G??? 表示特征圖 i 和 j 之間的相關(guān)關(guān)系。
要為我們的基本輸入圖像生成風(fēng)格,我們需要對內(nèi)容圖像執(zhí)行梯度下降法,將其轉(zhuǎn)換為與原始圖像的風(fēng)格表征匹配的圖像。我們通過最小化風(fēng)格圖像與輸入圖像的特征相關(guān)圖之間的均方距離來進行此項操作。每層對總風(fēng)格損失的貢獻用以下公式描述
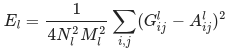
其中 G??? 和 A??? 分別為輸入圖像 x 和風(fēng)格圖像 a 在 l 層的風(fēng)格表征。Nl 表示特征圖的數(shù)量,每個圖的大小為 Ml= 高度 ? 寬度。因此,每層的總風(fēng)格損失為
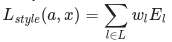
其中,我們用系數(shù) wl 來衡量每層損失的貢獻。在這個例子中,我們平均地衡量每個層:
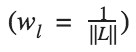
這實施起來很簡單:
1def gram_matrix(input_tensor):
2# We make the image channels first
3channels = int(input_tensor.shape[-1])
4a = tf.reshape(input_tensor, [-1, channels])
5n = tf.shape(a)[0]
6gram = tf.matmul(a, a, transpose_a=True)
7return gram / tf.cast(n, tf.float32)
8
9def get_style_loss(base_style, gram_target):
10"""Expects two images of dimension h, w, c"""
11# height, width, num filters of each layer
12height, width, channels = base_style.get_shape().as_list()
13gram_style = gram_matrix(base_style)
14return tf.reduce_mean(tf.square(gram_style - 15gram_target))
運行梯度下降法
如果您對梯度下降法/反向傳播算法不熟悉,或需要復(fù)習(xí)一下,那您一定要查看此資源。
在本例中,我們使用Adam優(yōu)化器來最小化我們的損失。我們迭代更新輸出圖像,以最大限度地減少損失:我們不是更新與網(wǎng)絡(luò)有關(guān)的權(quán)重,而是訓(xùn)練我們的輸入圖像以使損失最小化。為此,我們必須知道如何計算損失和梯度。請注意,我們推薦使用 L-BFGS 優(yōu)化器(如果您熟悉此算法的話),但本教程并未使用該優(yōu)化器,因為本教程旨在闡述使用 Eager Execution 的最佳實踐。通過使用 Adam,我們可以借助自定義訓(xùn)練循環(huán)來說明 autograd/梯度帶的功能。
計算損失和梯度
我們會定義一些輔助函數(shù),這些函數(shù)會加載我們的內(nèi)容和風(fēng)格圖像,通過網(wǎng)絡(luò)將它們向前饋送,然后從我們的模型輸出內(nèi)容和風(fēng)格的特點表征。
1def get_feature_representations(model, content_path, style_path):
2"""Helper function to compute our content and style feature representations.
3
4This function will simply load and preprocess both the content and style
5images from their path. Then it will feed them through the network to obtain
6the outputs of the intermediate layers.
7
8Arguments:
9 model: The model that we are using.
10content_path: The path to the content image. 11style_path: The path to the style image
12
13Returns:
14returns the style features and the content features.
15"""
16# Load our images in
17content_image = load_and_process_img(content_path)
18style_image = load_and_process_img(style_path)
19
20# batch compute content and style features
21stack_images = np.concatenate([style_image, content_image], axis=0)
22model_outputs = model(stack_images)
23# Get the style and content feature representations from our model
24
25 style_features = [style_layer[0] for style_layer in model_outputs[:num_style_layers]]
26content_features = [content_layer[1] for content_layer in model_outputs[num_style_layers:]]
27return style_features, content_features
這里我們使用tf.GradientTape來計算梯度。這樣,我們可以通過追蹤操作來利用可用的自動微分,以便之后計算梯度。它會記錄正向傳遞期間的操作,并能夠計算關(guān)于向后傳遞的輸入圖像的損失函數(shù)梯度。
1def compute_loss(model, loss_weights, init_image, gram_style_features, content_features):
2"""This function will compute the loss total loss.
3
4 Arguments:
5model: The model that will give us access to the intermediate layers
6loss_weights: The weights of each contribution of each loss function.
7(style weight, content weight, and total variation weight)
8init_image: Our initial base image. This image is what we are updating with
9 our optimization process. We apply the gradients wrt the loss we are
10 calculating to this image.
11 gram_style_features: Precomputed gram matrices corresponding to the
12 defined style layers of interest.
13 content_features: Precomputed outputs from defined content layers of
14 interest.
15
16Returns:
17returns the total loss, style loss, content loss, and total variational loss
18"""
19style_weight, content_weight, total_variation_weight = loss_weights
20
21# Feed our init image through our model. This will give us the content and
22# style representations at our desired layers. Since we're using eager
23# our model is callable just like any other function!
24model_outputs = model(init_image)
25
26style_output_features = model_outputs[:num_style_layers]
27content_output_features = model_outputs[num_style_layers:]
28
29style_score = 0
30content_score = 0
31
32# Accumulate style losses from all layers
33# Here, we equally weight each contribution of each loss layer
34weight_per_style_layer = 1.0 / float(num_style_layers)
35for target_style, comb_style in zip(gram_style_features, style_output_features):
36style_score += weight_per_style_layer * get_style_loss(comb_style[0], target_style)
37
38# Accumulate content losses from all layers
39weight_per_content_layer = 1.0 / float(num_content_layers)
40for target_content, comb_content in zip(content_features, content_output_features):
41content_score += weight_per_content_layer* get_content_loss(comb_content[0], target_content)
42
43style_score *= style_weight
44content_score *= content_weight
45total_variation_score = total_variation_weight * total_variation_loss(init_image)
46
47# Get total loss
48loss = style_score + content_score + total_variation_score
49return loss, style_score, content_score, total_variation_score
然后計算梯度就很簡單了:
1def compute_grads(cfg):
2with tf.GradientTape() as tape:
3all_loss = compute_loss(**cfg)
4# Compute gradients wrt input image
5total_loss = all_loss[0]
6return tape.gradient(total_loss, cfg['init_image']), all_loss
應(yīng)用并運行風(fēng)格遷移流程
要實際進行風(fēng)格遷移:
1def run_style_transfer(content_path,
2style_path,
3num_iterations=1000,
4content_weight=1e3,
5style_weight = 1e-2):
6display_num = 100
7# We don't need to (or want to) train any layers of our model, so we set their trainability
8# to false.
9model = get_model()
10for layer in model.layers:
11layer.trainable = False
12
13# Get the style and content feature representations (from our specified intermediate layers)
14style_features, content_features = get_feature_representations(model, content_path, style_path)
15gram_style_features = [gram_matrix(style_feature) for style_feature in style_features]
16
17# Set initial image
18init_image = load_and_process_img(content_path)
19init_image = tfe.Variable(init_image, dtype=tf.float32)
20# Create our optimizer
21opt = tf.train.AdamOptimizer(learning_rate=10.0)
22
23# For displaying intermediate images
24iter_count = 1
25
26# Store our best result
27best_loss, best_img = float('inf'), None
28
29# Create a nice config
30loss_weights = (style_weight, content_weight)
31cfg = {
32'model': model,
33'loss_weights': loss_weights,
34'init_image': init_image,
35'gram_style_features': gram_style_features,
36'content_features': content_features
37}
38
39# For displaying
40plt.figure(figsize=(15, 15))
41num_rows = (num_iterations / display_num) // 5
42start_time = time.time()
43global_start = time.time()
44
45norm_means = np.array([103.939, 116.779, 123.68])
46min_vals = -norm_means
47max_vals = 255 - norm_means
48for i in range(num_iterations):
49grads, all_loss = compute_grads(cfg)
50loss, style_score, content_score = all_loss
51# grads, _ = tf.clip_by_global_norm(grads, 5.0)
52opt.apply_gradients([(grads, init_image)])
53clipped = tf.clip_by_value(init_image, min_vals, max_vals)
54init_image.assign(clipped)
55end_time = time.time()
56
57if loss < best_loss: ? ?
58# Update best loss and best image from total loss.
59 best_loss = loss
60best_img = init_image.numpy()
61
62if i % display_num == 0:
63print('Iteration: {}'.format(i))
64print('Total loss: {:.4e}, '
65'style loss: {:.4e}, '
66'content loss: {:.4e}, '
67'time: {:.4f}s'.format(loss, style_score, content_score, time.time() - start_time))
68start_time = time.time()
69
70# Display intermediate images
71if iter_count > num_rows * 5: continue
72plt.subplot(num_rows, 5, iter_count)
73# Use the .numpy() method to get the concrete numpy array
74plot_img = init_image.numpy()
75plot_img = deprocess_img(plot_img)
76plt.imshow(plot_img)
77plt.title('Iteration {}'.format(i + 1))
78
79iter_count += 1
80print('Total time: {:.4f}s'.format(time.time() - global_start))
81
82return best_img, best_loss
就是這樣!
我們在海龜圖像和 Hokusai 的《神奈川沖浪里》上運行該流程:
1best, best_loss = run_style_transfer(content_path,
2style_path,
3verbose=True,
4show_intermediates=True)
P.Lindgren 拍攝的《綠海龜》圖[CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)],圖片來自 Wikimedia Common
觀察這一迭代過程隨時間發(fā)生的變化:
下面有一些關(guān)于神經(jīng)風(fēng)格遷移用途的很棒示例。快來看看吧!
圖賓根的圖像 — 拍攝者:Andreas Praefcke [GFDL (http://www.gnu.org/copyleft/fdl.html) 或 CC BY 3.0 (https://creativecommons.org/licenses/by/3.0)],圖像來自Wikimedia Commons;以及梵高的《星月夜》,圖像來自公共領(lǐng)域
圖賓根的圖像 — 拍攝者:Andreas Praefcke [GFDL (http://www.gnu.org/copyleft/fdl.html) 或 CC BY 3.0 (https://creativecommons.org/licenses/by/3.0)],圖片來自Wikimedia Commons,和 Vassily Kandinsky 所作的《構(gòu)圖 7》,圖片來自公共領(lǐng)域
-
圖像
+關(guān)注
關(guān)注
2文章
1092瀏覽量
40987 -
AI
+關(guān)注
關(guān)注
87文章
34001瀏覽量
275091 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4367瀏覽量
64068
原文標題:想化身 AI 領(lǐng)域藝術(shù)家?使用 tf.keras 和 Eager Execution 吧
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
cube AI導(dǎo)入Keras模型出錯怎么解決?
轉(zhuǎn)帖:日本藝術(shù)家 LED立體光雕
3D打印技術(shù)玩轉(zhuǎn)生活的藝術(shù)
八位藝術(shù)家合作開發(fā)一個新的藝術(shù)項目:交互式AR展覽
AI的創(chuàng)作是真正的藝術(shù)嗎?你會買嗎?
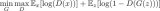
人工智能賦能藝術(shù) 藝術(shù)家塑造未來
最新tf.keras指南,TensorFlow官方出品
AI會將藝術(shù)家代替掉嗎
藝術(shù)家鐘愫君:人機協(xié)作領(lǐng)域的先驅(qū)人物
OPPO Reno5 Pro+藝術(shù)家限定版1月22日正式開售
首款電致變色旗艦OPPO Reno5 Pro+藝術(shù)家限定版上架
OPPO Reno5 Pro+藝術(shù)家限定版全網(wǎng)開啟預(yù)售
紐約現(xiàn)代藝術(shù)博物館的裝置標志著 AI 藝術(shù)的突破
你意想不到的舞蹈藝術(shù)家們!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論