 循環神經網絡注意力的模擬實現
循環神經網絡注意力的模擬實現
我們觀察PPT的時候,面對整個場景,不會一下子處理全部場景信息,而會有選擇地分配注意力,每次關注不同的區域,然后將信息整合來得到整個的視覺印象,進而指導后面的眼球運動。將感興趣的東西放在視野中心,每次只處理視野中的部分,忽略視野外區域,這樣做最大的好處是降低了任務的復雜度。
深度學習領域中,處理一張大圖的時候,使用卷積神經網絡的計算量隨著圖片像素的增加而線性增加。如果參考人的視覺,有選擇地分配注意力,就能選擇性地從圖片或視頻中提取一系列的區域,每次只對提取的區域進行處理,再逐漸地把這些信息結合起來,建立場景或者環境的動態內部表示,這就是本文所要講述的循環神經網絡注意力模型。
怎么實現的呢?
把注意力問題當做一系列agent決策過程,agent可以理解為智能體,這里用的是一個RNN網絡,而這個決策過程是目標導向的。簡要來講,每次agent只通過一個帶寬限制的傳感器觀察環境,每一步處理一次傳感器數據,再把每一步的數據隨著時間融合,選擇下一次如何配置傳感器資源;每一步會接受一個標量的獎勵,這個agent的目的就是最大化標量獎勵值的總和。
下面我們來具體講解一下這個網絡。
如上所示,圖A是帶寬傳感器,傳感器在給定位置選取不同分辨率的圖像塊,大一點的圖像塊的邊長是小一點圖像塊邊長的兩倍,然后resize到和小圖像塊一樣的大小,把圖像塊組輸出到B。
圖B是glimpse network,這個網絡是以theta為參數,兩個全連接層構成的網絡,將傳感器輸出的圖像塊組和對應的位置信息以線性網絡的方式結合到一起,輸出gt。
圖C是循環神經網絡即RNN的主體,把glimpse network輸出的gt投進去,再和之前內部信息ht-1結合,得到新的狀態ht,再根據ht得到新的位置lt和新的行為at,at選擇下一步配置傳感器的位置和數量,以更好的觀察環境。在配置傳感器資源的時候,agent也會受到一個獎勵信號r,比如在識別中,正確分類r是1,錯誤分類r是0,agent的目標是最大化獎勵信號r的和:
梯度的近似可以表示為:
公式(1)也叫做增強學習的規則,它包括運用當前的策略運行agent去獲得交互序列,然后根據可以增大獎勵信號的行為調整theta。它的訓練過程就是用增強學習的方法學習具體任務策略。關于給定任務,根據模型做出的一系列決定給出表現評價,最大化表現評價,對其進行端到端的優化。
首先為什么要用增強學習呢?因為數據的狀態不是非常明確的,不是可以直接監督或者非監督來訓練的,比如機器人的控制很難完全精確。
那么什么是增強學習呢?
增強學習關注的是智能體如何在環境中采取一系列行為,從而獲得最大的累積回報。RL是從環境狀態到動作的映射的學習,我們把這個映射稱為策略。通過增強學習,一個智能體(agent)應該知道在什么狀態下應該采取什么行為。
假設一個智能體處于下圖(a)中所示的4x3的環境中。從初始狀態開始,它需要每個時間選擇一個行為(上、下、左、右)。在智能體到達標有+1或-1的目標狀態時與環境的交互終止。如果環境是確定的,很容易得到一個解:[上,上,右,右,右]。可惜智能體的行動不是可靠的(類似現實中對機器人的控制不可能完全精確),環境不一定沿這個解發展。下圖(b)是一個環境轉移模型的示意,每一步行動以0.8的概率達到預期,0.2的概率會垂直于運動方向移動,撞到(a)圖中黑色模塊后會無法移動。兩個終止狀態分別有+1和-1的回報,其他狀態有-0.4的回報。現在智能體要解決的是通過增強學習(不斷的試錯、反饋、學習)找到最優的策略(得到最大的回報)。
上述問題可以看作為一個馬爾科夫決策過程,最終的目標是通過一步步決策使整體的回報函數期望最優。
提到馬爾科夫,大家通常會立刻想起馬爾可夫鏈(Markov Chain)以及機器學習中更加常用的隱式馬爾可夫模型(Hidden Markov Model, HMM)。它們都具有共同的特性便是馬爾可夫性:當一個隨機過程在給定現在狀態及所有過去狀態情況下,未來狀態的條件概率分布僅依賴于當前狀態;換句話說,在給定現在狀態時,它與過去狀態是條件獨立的,那么此隨機過程即具有馬爾可夫性質。具有馬爾可夫性質的過程通常稱之為馬爾可夫過程。
馬爾可夫決策過程(Markov Decision Process),其也具有馬爾可夫性,與上面不同的是MDP考慮了動作,即系統下個狀態不僅和當前的狀態有關,也和當前采取的動作有關。
一個馬爾科夫決策過程(Markov Decision Processes, MDP)有五個關鍵元素組成{S,A,{Psa},γ,R},其中:
這個就是馬爾科夫決策過程。講完馬爾科夫決策之后我們回過頭回顧一下訓練的過程:每次agent只通過一個帶寬限制的傳感器觀察環境,每一步處理一次傳感器數據,再把每一步的數據隨著時間融合,選擇下一次如何配置傳感器資源;每一步會接受一個標量的獎勵,這個agent的目的就是最大化標量獎勵值的總和。
注意力模型的效果如何
把注意力模型和全連接網絡以及卷積神經網絡進行比較,實驗證明了模型可以從多個glimpse結合的信息中成功學習,并且學習的效果優于卷積神經網絡。
由于注意力模型可以關注圖像相關部分,忽視無關部分,所以能夠在在有干擾的情況下識別,識別效果也是比其他網絡要好的。下面這個圖表現的是注意力的路徑,表明網絡可以避免計算不重要的部分,直接探索感興趣的部分。
基于循環神經網絡的注意力模型比較有特色的地方就在于:
●提高計算效率,處理比較大的圖片的時候非常好用;
●阻塞狀態下也能識別。
我們講了半天,一個重要的概念沒有講,下面來講講循環神經網絡RNN。
我們做卷積神經網絡的時候樣本的順序并不受到關注,而對于自然語言處理,語音識別,手寫字符識別來說,樣本出現的時間順序是非常重要的,RNNs出現的目的是來處理時間序列數據。
這個網絡最直觀的印象是什么呢,就是線多。在傳統的神經網絡模型中,是從輸入層到隱含層再到輸出層,層與層之間是全連接的,每層的節點之間是無連接的。但是這種普通的神經網絡對于很多問題卻沒有辦法。例如,要預測句子的下一個單詞,一般需要用到前面的單詞,因為一個句子中前后單詞并不是獨立的。RNNs之所以稱為循環神經網路,即一個序列當前的輸出與前面的輸出也有關,網絡會對前面的信息進行記憶并應用于當前輸出的計算中,具體的表現形式為即隱藏層之間的節點不再無連接而是有連接的,并且隱藏層的輸入不僅包括輸入層的輸出還包括上一時刻隱藏層的輸出。理論上,RNNs能夠對任何長度的序列數據進行處理。但是在實踐中,為了降低復雜性往往假設當前的狀態只與前面的幾個狀態相關,下圖便是一個典型的RNNs:
T時刻的輸出是該時刻的輸入和所有歷史共同的結果,這就達到了對時間序列建模的目的。RNN可以看成一個在時間上傳遞的神經網絡,它的深度是時間的長度。對于t時刻來說,它產生的梯度在時間軸上向歷史傳播幾層之后就消失了,根本就無法影響太遙遠的過去。因此,之前說“所有歷史”共同作用只是理想的情況,在實際中,這種影響也就只能維持若干個時間戳。
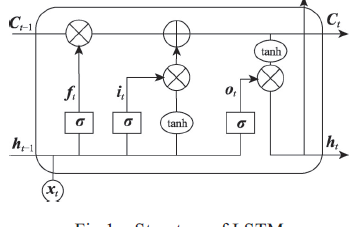
為了解決時間上的梯度消失,機器學習領域發展出了長短時記憶單元LSTM,通過門的開關實現時間上記憶功能,并防止梯度消失。
RNN還可以用在生成圖像描述之中,用CNN網絡做識別和分類,用RNN網絡產生描述語句,這就是李飛飛的實驗室所研究的內容。
-
傳感器
+關注
關注
2551文章
51177瀏覽量
754271 -
機器學習
+關注
關注
66文章
8422瀏覽量
132741
發布評論請先 登錄
相關推薦
卷積神經網絡模型發展及應用
循環神經網絡卷積神經網絡注意力文本生成變換器編碼器序列表征
基于異質注意力的循環神經網絡模型

基于雙向長短期記憶神經網絡的交互注意力模型
基于語音、字形和語義的層次注意力神經網絡模型

基于循環卷積注意力模型的文本情感分類方法





 工商網監
工商網監
評論