 構建中文網頁分類器對網頁進行文本分類
構建中文網頁分類器對網頁進行文本分類
網絡原指用一個巨大的虛擬畫面,把所有東西連接起來,也可以作為動詞使用。在計算機領域中,網絡就是用物理鏈路將各個孤立的工作站或主機相連在一起,組成數據鏈路,從而達到資源共享和通信的目的。凡將地理位置不同,并具有獨立功能的多個計算機系統通過通信設備和線路而連接起來,且以功能完善的網絡軟件(網絡協議、信息交換方式及網絡操作系統等)實現網絡資源共享的系統,可稱為計算機網絡。網絡的迅速發展,使人們不僅面臨信息爆炸,同時也面臨著如何從浩如煙海的信息中獲取自己所需信息的難題。如何有效地組織和處理海量的信息,并過濾和管理網絡資源,已成為必須面對的問題。
為了網頁信息的有效組織和檢索,人們開發了各種網絡信息搜索器,在一定程度上確實提高了網絡信息的利用率。與文本分類技術相比較,網頁分類更加復雜,這是由網頁的結構特征決定的,但是網頁的信息主要是通過文本的方式向人們傳遞的,所以在對網頁分類之前,首先要對其中的文本進行提取,對所提取的文本分類,最終使網頁分類問題轉化為文本分類問題。
目前,文本分類技術的研究比較活躍,已經出現了多種文本分類算法,并且被廣泛應用于多個領域:信息檢索、搜索引擎、文本數據庫等。文本分類算法基本是基于概率統計模型,本文就是基于互信息(MI)提出一種改進的特征提取方法,并根據TFIDF提出一種新的特征權值計算方法構建中文網頁分類器。
1 網頁預處理
網頁分類之前首先要進行預處理,實際上就是HTML解析,把解析出來的內容用于文本分類,選取網頁中的下面這些文本用于分類:
(1)錨文本。錨文本是網頁中用于指示所連接網頁內容的提示,由于后面要對提取的文本進行分類,所以只提取文字形式的錨文本。
(2)title文本。這樣的文本可能是網頁中最重要的標簽,必須取得。
(3)meta標簽。其重要的功能就是設置關鍵字,網頁的制作者往往都設置了關鍵字,來提高網頁的搜索點擊率。可以利用meta標簽中的有關文本內容進行網頁分類。
(4)主文本。上面這些信息獲取之后,網頁中剩余的文本信息還在各種HTML標簽中,在HTML源文件中,主文本有可能不是連續出現的。主文本一般是網頁中文字最集中的較長的字符串,查看源文件,那些比較長的字符串是整個出現在1個標簽中的。
文本首先要確定的問題就是表示文本的基本單位,用于表示文本的基本單位通常稱為文本的特征或特征項。中文文本不同于英文文本,英文文本以空格為分隔符,非常明確。而中文文本需要對其進行分詞處理才能得出每個特征。本文采用中科院計算技術研究所漢語詞法分析系統ICTCLAS3.0進行分詞。如果把這些對文本分類沒有意義的虛詞作為特征,將會帶來很大噪音,降低文本分類的效率和準確率。因此,在提取文本特征時,應首先考慮剔除這些對文本分類沒有用處的虛詞,而在實詞中,又以名詞和動詞對于文本的類別特性的表現力最強。
2 特征提取
特征提取就是提取出最能代表某篇文章或某類的特征項,以達到降維的效果從而減少文本分類的計算量。典型特征提取方法:信息增益(Information Gain),互信息(MI)、文檔頻度(DF)。傳統的MI特征提取方法:
計算出所有特征詞的統計值后,從大到小進行排序,然后根據需要從上到下選取一定數量的特征詞構建文本分類的特征詞庫。
3 特征加權及向量化
TFIDF算法及其改進型[5]有多種公式,本文使用一種新的改進的TF-IDF公式來計算特征詞的權重。TF-IDF公式有很多變種,比較常見的TF-IDF公式:

:
-
HTML
+關注
關注
0文章
278瀏覽量
35874 -
分類器
+關注
關注
0文章
152瀏覽量
13202 -
文本
+關注
關注
0文章
118瀏覽量
17092
發布評論請先 登錄
相關推薦
pyhanlp文本分類與情感分析
NLPIR平臺在文本分類方面的技術解析
融合詞語類別特征和語義的短文本分類方法
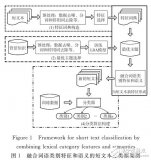
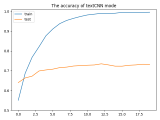
textCNN論文與原理——短文本分類
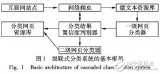
基于深度神經網絡的文本分類分析

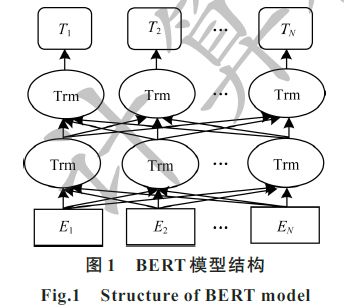
結合BERT模型的中文文本分類算法





 工商網監
工商網監
評論