

我們生活在一個技術推動整個文明基石的時代。但是,盡管擁有所有輝煌的發明和技術進步,今天世界比以往更傾向于速度和敏捷性。我們已經從傳統的有線撥號互聯網連接轉移到第四代無線網絡。光纖的廣泛分布使得連接到互聯網并以快速的速度訪問數據成為可能。同樣,當涉及到處理器和GPU時,我們已經從僅包含6000個晶體管的傳統8位8080微處理器芯片轉變為時鐘速度高達1.7 GHz的最先進的Octa核心處理器。
人工智能的發展越來越抽象,越來越復雜。從早期簡單的是與否的判斷,到后來精準的識別,可以在復雜的場景里找出特定的目標,再到后來,出現 AlphaGo 這樣可以做出主動的決策的 AI,甚至智能如 AlphaGo Zero,可以完全依靠自學實現快速成長。
人工智能經過這么長時間的發展,在網絡的種類、復雜程度和處理的信息量上都發生了天翻地覆的變化。網絡種類上,從早期的 AlexNet 和 GoogleNet 到現在各種各樣的 GAN(生成對抗網絡)以及各種深度強化學習的網絡,它們各自網絡結構都有不同,開發者在適應最新的網絡上常常會遇到一些麻煩。
處理的信息量也在成倍地增長,算力需求越來越高的情況下,對搭載處理單元的體積有更多限制的機器人實際上存在著在智能水平上升級的障礙。這就是為什么人工智能芯片不斷升級迭代的原因。
人工智能的終極目標是模擬人腦,人腦大概有1000億個神經元,1000萬億個突觸,能夠處理復雜的視覺、聽覺、嗅覺、味覺、語言能力、理解能力、認知能力、情感控制、人體復雜機構控制、復雜心理和生理控制,而功耗只有10~20瓦。
可能有很多人會問,目前在人工智能領域,NVidia GPU為什么具有無可撼動的霸主地位,為什么AMD的GPU和NVidia GPU性能相差不多,但是在人工智能領域的受歡迎的程度卻有天壤之別。
2011年,負責谷歌大腦的吳恩達通過讓深度神經網絡訓練圖片,一周之內學會了識別貓,他用了12片GPU代替了2000片CPU,這是世界上第一次讓機器認識貓。
2016年,谷歌旗下Deepmind團隊研發的機器人AlphaGo以4比1戰勝世界圍棋冠軍職業九段棋手李世石(AlphaGo的神經網絡訓練用了50片GPU,走棋網絡用了174片GPU),引發了圍棋界的軒然大波,因為圍棋一直被認為是人類智力較量的巔峰,這可以看做是人工智能史上的又一個重大里程碑事件。
谷歌并不是唯一一家為這種設備上的AI任務設計芯片的公司。 ARM,Qualcomm,Mediatek和其他公司都制造了自己的AI加速器,而Nvidia制造的GPU在培訓算法市場上占據了主導地位。
然而,Google的競爭對手并沒有控制整個AI堆棧。 客戶可以將他們的數據存儲在Google的云端; 使用TPU訓練他們的算法; 然后使用新的Edge TPU進行設備上推斷。而且,他們很可能會使用TensorFlow創建他們的機器學習軟件--TensorFlow是由Google創建和運營的編碼框架。
這種垂直整合具有明顯的好處。 Google可以確保所有這些不同的部分盡可能高效,順暢地相互通信,使客戶更容易在公司的生態系統中玩游戲。
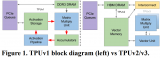
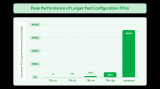
2016年5月的谷歌I/O大會,谷歌首次公布了自主設計的TPU,2017年谷歌I/O大會,谷歌宣布正式推出第二代TPU處理器,在今年的Google I/0 2018大會上,谷歌發布了新一代TPU處理器——TPU 3.0。TPU 3.0的性能相比目前的TPU 2.0有8倍提升,可達10億億次。
TPU全名為Tensor Processing Unit,是谷歌研發的一種神經網絡訓練的處理器,主要用于深度學習、AI運算。在7月份的Next 云端大會,谷歌又發布了 Edge TPU 芯片搶攻邊緣計算市場。雖然都是 TPU,但邊緣計算用的版本與訓練機器學習的 Cloud TPU 不同,是專門用來處理AI預測部分的微型芯片。Edge TPU可以自己運行計算,而不需要與多臺強大計算機相連,因此應用程序可以更快、更可靠地工作。它們可以在傳感器或網關設備中與標準芯片或微控制器共同處理AI工作。
-
cpu
+關注
關注
68文章
11037瀏覽量
216016 -
TPU
+關注
關注
0文章
152瀏覽量
21080
發布評論請先 登錄
TPU處理器的特性和工作原理
Google推出第七代TPU芯片Ironwood
谷歌第七代TPU Ironwood深度解讀:AI推理時代的硬件革命

M3 Ultra 蘋果最強芯片 80 核 GPU,32 核 NPU

光纜用tpu外護套用在哪些型號光纜上
高通驍龍汽車新方案:CPU性能躍升3倍,AI性能狂飆12倍
倍壓整流電路的類型和應用
CPU主頻是什么意思
CPU時鐘周期的組成和作用
蘋果 A18 芯片發布:CPU 提升 30%、GPU 提升 40%






 工商網監
工商網監

評論