 訓練表示學習函數(即編碼器)以最大化其輸入和輸出之間的互信息
訓練表示學習函數(即編碼器)以最大化其輸入和輸出之間的互信息
許多表示學習算法使用像素級的訓練目標,當只有一小部分信號在語義層面上起作用時是不利的。在這篇論文中,Bengio 等研究者假設應該更直接地根據信息內容和統計或架構約束來學習表示,據此提出了 Deep INFOMAX(DIM)。該方法可用于學習期望特征的表示,并且在分類任務上優于許多流行的無監督學習方法。他們認為,這是學習「好的」和更條理的表示的一個重要方向,有利于未來的人工智能研究。
引言
在意識層面上,智能體并不在像素和其他傳感器的層面上進行預測和規劃,而是在抽象層面上進行預測。因為語義相關的比特數量(在語音中,例如音素、說話者的身份、韻律等)只是原始信號中總比特數的一小部分,所以這樣可能更合適。
然而,大多數無監督機器學習(至少是部分地)基于定義在輸入空間中的訓練目標。由于無需捕獲少數語義相關的比特,就可以很好地優化這些目標,因此它們可能不會產生好的表示。深度學習的核心目標之一是發現「好的」表示,所以我們會問:是否有可能學習輸入空間中未定義的訓練目標的表示呢?本文探討的簡單想法是訓練表示學習函數(即編碼器)以最大化其輸入和輸出之間的互信息。
互信息是出了名的難計算,特別是在連續和高維設置中。幸運的是,在神經估計的最新進展中,已經能夠有效計算深度神經網絡的高維輸入/輸出對之間的互信息。而在本項研究中,研究人員利用這些技術進行表示學習。然而,最大化完全輸入與其表示之間的互信息(即全局互信息)不足以學習有用的表示,這依賴于下游任務。相反,最大化輸入的表示和局部區域之間的平均互信息可以極大地改善例如分類任務的表示質量,而全局互信息在給定表示的重建完整輸入上能發揮更大的作用。
表示的作用不僅僅體現在信息內容的問題上,架構等表示特征也非常重要。因此,研究者以類似于對抗性自編碼器或 BiGAN 的方式將互信息最大化與先驗匹配相結合,以獲得具有期望約束的表示,以及良好的下游任務表現。該方法接近 INFOMAX 優化原則,因此研究者們將他們的方法稱為深度 INFOMAX(DIM)。
本研究貢獻如下:
規范化的深度 INFOMAX(DIM),它使用互信息神經估計(MINE)來明確地最大化輸入數據和學習的高級表示之間的互信息。
互信息最大化可以優先考慮全局或局部一致的信息,這些信息可以用于調整學習表示的適用性,以進行分類或風格重建的任務。
研究者使用對抗學習來約束「具有特定于先驗的期望統計特征」的表示。
引入了兩種新的表示質量的度量,一種基于 MINE,另一種是 Brakel&Bengio 研究的的依賴度量,研究者用它們來比較不同無監督方法的表示。
論文:Learning deep representations by mutual information estimation and maximization
論文地址:https://arxiv.org/abs/1808.06670v2
摘要:許多流行的表示學習算法使用在觀察數據空間上定義的訓練目標,我們稱之為像素級。當只有一小部分信號在語義層面上起作用時,這可能是不利的。我們假設應該更直接地根據信息內容和統計或架構約束來學習和估計表示。為了解決第一個質量問題,研究者考慮通過最大化部分或全部輸入與高級特征向量之間的互信息來學習無監督表示。為了解決第二個問題,他們通過對抗地匹配先驗來控制表示特征。他們稱之為 Deep INFOMAX(DIM)的方法可用于學習期望特征的表示,并且在分類任務按經驗結果優于許多流行的無監督學習方法。DIM 開辟了無人監督學習表示的新途徑,是面向特定最終目標而靈活制定表征學習目標的重要一步。
實驗
我們使用以下指標來評估表示。下面編碼器都固定不變,除非另有說明:
使用支持向量機(SVM)進行線性分類。它同時代表具有線性可分性的表示的互信息。
使用有 dropout 的單個隱藏層神經網絡(200 個單元)進行非線性分類。這同樣代表表示的互信息,其中標簽與線性可分性分開,如上面的 SVM 所測的。
半監督學習,即通過在最后一個卷積層(有標準分類器的匹配架構)上添加一個小型神經網絡來微調整個編碼器,以進一步評估半監督任務(STL-10)。
MS-SSIM,使用在 L2 重建損失上訓練的解碼器。這代表輸入和表示之間的全部互信息,并且可以表明編碼的像素級信息的數量。
通過訓練參數為ρ的判別器來最大化 KL 散度的 DV 表示,來表示輸入 X 和輸出表示 Y 之間的互信息神經估計(MINE),I_ρ(X,Y)。
神經依賴度量(NDM)使用第二判別器來度量 Y 和分批再組(batch-wise shuffled)的 Y 之間的 KL 散度,使得不同的維度相互獨立。
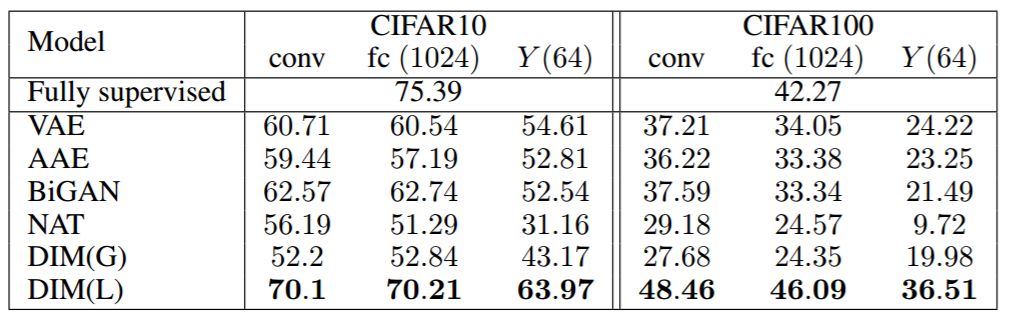
表 1:CIFAR10 和 CIFAR100 的分類準確率(top-1)結果。DIM(L)(僅局部目標)顯著優于之前提出的所有其他無監督方法。此外,DIM(L)接近甚至超過具有類似架構的全監督分類器。具有全局目標的 DIM 表現與任務中的某些模型相似,但不如 CIFAR100 上的生成模型和 DIM(L)。表中提供全監督分類結果用于比較。
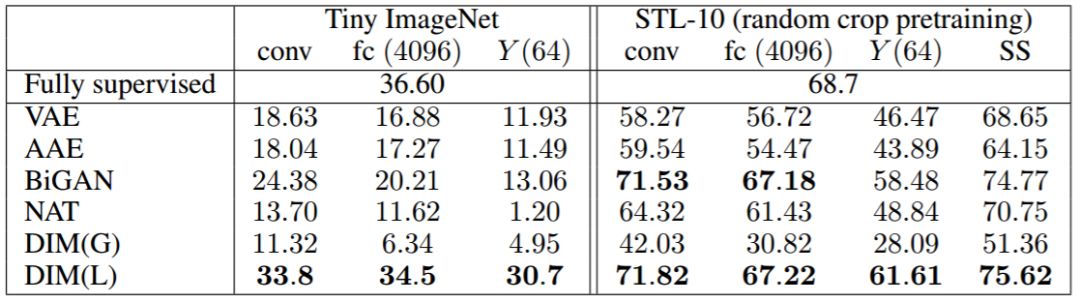
表 2:Tiny ImageNet 和 STL-10 的分類準確率(top-1)結果。對于 Tiny ImageNet,具有局部目標的 DIM 優于所有其他模型,并且接近全監督分類器的準確率,與此處使用的 AlexNet 架構類似。
圖 5:使用 DIM(G)和 DIM(L)在編碼的 Tiny ImageNet 圖像上使用 L1 距離的最近鄰。最左邊的圖像是來自訓練集的隨機選擇的參考圖像(查詢)以及在表示中測量的來自測試集的最近鄰的四個圖像,按照接近度排序。來自 DIM(L)的最近鄰比具有純粹全局目標的近鄰更容易理解。
圖 7:描繪判別器非歸一化輸出分布的直方圖,分別是標準 GAN、具有-log D 損失的 GAN、最小二乘 GAN、Wasserstein GAN 以及作者提出的以 50:1 訓練率訓練的方法。
方法:深度 INFOMAX
圖 1:圖像數據上下文中的基本編碼器模型。將圖像(在這種情況下)編碼到卷積網絡中,直到有一個 M×M 特征向量的特征圖與 M×M 個輸入塊對應。將這些矢量(例如使用額外的卷積和全連接層)歸一化到單個特征向量 Y。目標是訓練此網絡,以便從高級特征中提取有關輸入的相關信息。
圖 2:具有全局 MI(X; Y)目標的深度 INFOMAX(DIM)。研究者通過由額外的卷積層、flattening 層和全連接層組成的判別器來傳遞高級特征向量 Y 和低級 M×M 特征圖(參見圖 1)以獲得分數。通過將相同的特征向量與來自另一圖像的 M×M 特征圖結合來繪制偽樣本。
結論
在這項研究中,研究者們介紹了 Deep INFOMAX(DIM),這是一種通過最大化互信息來學習無監督表示的新方法。DIM 允許在架構「位置」(如圖像中的塊)中包含局部一致信息的表示。這提供了一種直接且靈活的方式來學習在各種任務上有優良表現的表示。他們認為,這是學習「好的」和更條理的表示的一個重要方向,這將利于未來的人工智能研究。
-
編碼器
+關注
關注
45文章
3638瀏覽量
134426 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238257 -
深度學習
+關注
關注
73文章
5500瀏覽量
121111
原文標題:學界 | 最大化互信息來學習深度表示,Bengio等提出Deep INFOMAX
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學會】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
labview獲取【顯示器分辨率】并實時設置界面【最大化】和【最小化居中】
基于最大互信息方法的機械零件圖像識別
基于互信息的功能磁共振圖像配準
基于圖嵌入和最大互信息組合的降維
基于互信息梯度優化計算的信息判別特征提取
Powell和SA混合優化的互信息圖像配準
基于互信息和余弦的不良文檔過濾
基于互信息轉發MIF的網絡編碼中繼轉發方案
密碼芯片時域互信息能量分析
是十款各具特色的GANs,深入了解其數學原理
編碼器參數_編碼器型號說明
一種改進互信息的加權樸素貝葉斯算法






 工商網監
工商網監
評論