") AutoML模型壓縮技術(shù),利用強(qiáng)化學(xué)習(xí)將壓縮流程自動(dòng)化
AutoML模型壓縮技術(shù),利用強(qiáng)化學(xué)習(xí)將壓縮流程自動(dòng)化
MIT韓松團(tuán)隊(duì)和Google Cloud的研究人員提出AutoML模型壓縮技術(shù),利用強(qiáng)化學(xué)習(xí)將壓縮流程自動(dòng)化,完全無(wú)需人工,而且速度更快,性能更高。
模型壓縮是在計(jì)算資源有限、能耗預(yù)算緊張的移動(dòng)設(shè)備上有效部署神經(jīng)網(wǎng)絡(luò)模型的關(guān)鍵技術(shù)。
在許多機(jī)器學(xué)習(xí)應(yīng)用,例如機(jī)器人、自動(dòng)駕駛和廣告排名等,深度神經(jīng)網(wǎng)絡(luò)經(jīng)常受到延遲、電力和模型大小預(yù)算的限制。已經(jīng)有許多研究提出通過(guò)壓縮模型來(lái)提高神經(jīng)網(wǎng)絡(luò)的硬件效率。
模型壓縮技術(shù)的核心是確定每個(gè)層的壓縮策略,因?yàn)樗鼈兙哂胁煌娜哂啵@通常需要手工試驗(yàn)和領(lǐng)域?qū)I(yè)知識(shí)來(lái)探索模型大小、速度和準(zhǔn)確性之間的大設(shè)計(jì)空間。這個(gè)設(shè)計(jì)空間非常大,人工探索法通常是次優(yōu)的,而且手動(dòng)進(jìn)行模型壓縮非常耗時(shí)。
為此,韓松團(tuán)隊(duì)提出了AutoML模型壓縮(AutoML for Model Compression,簡(jiǎn)稱AMC),利用強(qiáng)化學(xué)習(xí)來(lái)提供模型壓縮策略。
論文地址:
https://arxiv.org/pdf/1802.03494.pdf
負(fù)責(zé)這項(xiàng)研究的MIT助理教授韓松博士表示:
“算力換算法”是當(dāng)今AutoML系列工作的熱點(diǎn)話題,AMC則屬于“算力換算力”:用training時(shí)候的算力換取inference時(shí)候的算力。模型在完成一次訓(xùn)練之后,可能要在云上或移動(dòng)端部署成千上萬(wàn)次,所以inference的速度和功耗至關(guān)重要。
我們用AutoML做一次性投入來(lái)優(yōu)化模型的硬件效率,然后在inference的時(shí)候可以得到事半功倍的效果。比如AMC將MobileNet inference時(shí)的計(jì)算量從569M MACs降低到285M MACs,在Pixel-1手機(jī)上的速度由8.1fps提高到14.6fps,僅有0.1%的top-1準(zhǔn)確率損失。AMC采用了合適的搜索空間,對(duì)壓縮策略的搜索僅需要4個(gè)GPU hours。
總結(jié)來(lái)講,AMC用“Training算力”換取“Inference算力”的同時(shí)減少的對(duì)“人力“的依賴。最后,感謝Google Cloud AI對(duì)本項(xiàng)目的支持。
Google Cloud 研發(fā)總監(jiān)李佳也表示:“AMC是我們?cè)谀P蛪嚎s方面的一點(diǎn)嘗試,希望有了這類的技術(shù),讓更多的mobile和計(jì)算資源有限的應(yīng)用變得可能。”
“Cloud AutoML 產(chǎn)品設(shè)計(jì)讓機(jī)器學(xué)習(xí)的過(guò)程變得更簡(jiǎn)單,讓即便沒(méi)有機(jī)器學(xué)習(xí)經(jīng)驗(yàn)的人也可以享受機(jī)器學(xué)習(xí)帶來(lái)的益處。盡管AutoML有很大的進(jìn)步,這仍是一項(xiàng)相對(duì)初期的技術(shù),還有很多方面需要提高和創(chuàng)新。”李佳說(shuō)。
用AI做模型壓縮,完全不需要人工
研究人員的目標(biāo)是自動(dòng)查找任意網(wǎng)絡(luò)的壓縮策略,以實(shí)現(xiàn)比人為設(shè)計(jì)的基于規(guī)則的模型壓縮方法更好的性能。
這項(xiàng)工作的創(chuàng)新性體現(xiàn)在:
1、AMC提出的learning-based model compression優(yōu)于傳統(tǒng)的rule-based model compression
2、資源有限的搜索
3、用于細(xì)粒度操作的連續(xù)行動(dòng)空間
4、使用很少的GPU進(jìn)行快速搜索(ImageNet上1個(gè)GPU,花費(fèi)4小時(shí))
目標(biāo):自動(dòng)化壓縮流程,完全無(wú)需人工。利用AI進(jìn)行模型壓縮,自動(dòng)化,速度更快,而且性能更高。
這種基于學(xué)習(xí)的壓縮策略優(yōu)于傳統(tǒng)的基于規(guī)則的壓縮策略,具有更高的壓縮比,在更好地保持準(zhǔn)確性的同時(shí)節(jié)省了人力。
在4×FLOP降低的情況下,我們?cè)贗mageNet上對(duì)VGG-16模型進(jìn)行壓縮,實(shí)現(xiàn)了比手工模型壓縮策略高2.7%的精度。
我們將這種自動(dòng)化壓縮pipeline應(yīng)用于MobileNet,在Android手機(jī)上測(cè)到1.81倍的推斷延遲加速,在Titan XP GPU上實(shí)現(xiàn)了1.43倍的加速,ImageNet Top-1精度僅下降了0.1%。
AutoML模型壓縮:基于學(xué)習(xí)而非規(guī)則
圖1:AutoML模型壓縮(AMC)引擎的概覽。左邊:AMC取代人工,將模型壓縮過(guò)程完全自動(dòng)化,同時(shí)比人類表現(xiàn)更好。右邊:將AMC視為一個(gè)強(qiáng)化學(xué)習(xí)為題。
以前的研究提出了許多基于規(guī)則的模型壓縮啟發(fā)式方法。但是,由于深層神經(jīng)網(wǎng)絡(luò)中的層不是獨(dú)立的,這些基于規(guī)則的剪枝策略并非是最優(yōu)的,而且不能從一個(gè)模型轉(zhuǎn)移到另一個(gè)模型。隨著神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的快速發(fā)展,我們需要一種自動(dòng)化的方法來(lái)壓縮它們,以提高工程師的效率。
AutoML for Model Compression(AMC)利用強(qiáng)化學(xué)習(xí)來(lái)自動(dòng)對(duì)設(shè)計(jì)空間進(jìn)行采樣,提高模型壓縮質(zhì)量。圖1展示了AMC引擎的概覽。在壓縮網(wǎng)絡(luò)是,ACM引擎通過(guò)基于學(xué)習(xí)的策略來(lái)自動(dòng)執(zhí)行這個(gè)過(guò)程,而不是依賴于基于規(guī)則的策略和工程師。
我們觀察到壓縮模型的精度對(duì)每層的稀疏性非常敏感,需要細(xì)粒度的動(dòng)作空間。因此,我們不是在一個(gè)離散的空間上搜索,而是通過(guò)DDPG agent提出連續(xù)壓縮比控制策略,通過(guò)反復(fù)試驗(yàn)來(lái)學(xué)習(xí):在精度損失時(shí)懲罰,在模型縮小和加速時(shí)鼓勵(lì)。actor-critic的結(jié)構(gòu)也有助于減少差異,促進(jìn)更穩(wěn)定的訓(xùn)練。
針對(duì)不同的場(chǎng)景,我們提出了兩種壓縮策略搜索協(xié)議:
對(duì)于latency-critical的AI應(yīng)用(例如,手機(jī)APP,自動(dòng)駕駛汽車和廣告排名),我們建議采用資源受限的壓縮(resource-constrained compression),在最大硬件資源(例如,F(xiàn)LOP,延遲和模型大小)下實(shí)現(xiàn)最佳精度);
對(duì)于quality-critical的AI應(yīng)用(例如Google Photos),我們提出精度保證的壓縮(accuracy-guaranteed compression),在實(shí)現(xiàn)最小尺寸模型的同時(shí)不損失精度。
DDPG Agent
DDPG Agent用于連續(xù)動(dòng)作空間(0-1)
輸入每層的狀態(tài)嵌入,輸出稀疏比
壓縮方法研究
用于模型大小壓縮的細(xì)粒度剪枝(Fine-grained Pruning)
粗粒度/通道剪枝,以加快推理速度
搜索協(xié)議
資源受限壓縮,以達(dá)到理想的壓縮比,同時(shí)獲得盡可能高的性能。
精度保證壓縮,在保持最小模型尺寸的同時(shí),完全保持原始精度。
為了保證壓縮的準(zhǔn)確性,我們定義了一個(gè)精度和硬件資源的獎(jiǎng)勵(lì)函數(shù)。有了這個(gè)獎(jiǎng)勵(lì)函數(shù),就能在不損害模型精度的情況下探索壓縮的極限。
對(duì)于資源受限的壓縮,只需使用Rerr = -Error
對(duì)于精度保證的壓縮,要考慮精度和資源(如FLOPs):RFLOPs = -Error?log(FLOPs)

實(shí)驗(yàn)和結(jié)果:全面超越手工調(diào)參
為了證明其廣泛性和普遍適用性,我們?cè)诙鄠€(gè)神經(jīng)網(wǎng)絡(luò)上評(píng)估AMC引擎,包括VGG,ResNet和MobileNet,我們還測(cè)試了壓縮模型從分類到目標(biāo)檢測(cè)的泛化能力。
強(qiáng)化學(xué)習(xí)agent對(duì)ResNet-50的剪枝策略
ACM將模型壓縮到更低密度而不損失精度(人類專家:ResNet50壓縮3.4倍;AMC:ResNet50壓縮5倍)
大量實(shí)驗(yàn)表明,AMC提供的性能優(yōu)于手工調(diào)優(yōu)的啟發(fā)式策略。對(duì)于ResNet-50,我們將專家調(diào)優(yōu)的壓縮比從3.4倍提高到5倍,而沒(méi)有降低精度。
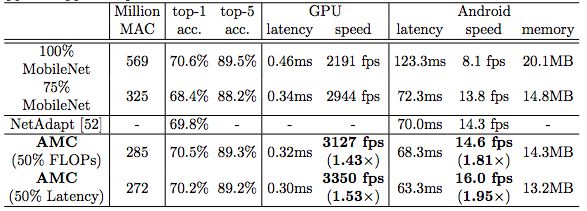
AMC對(duì)MobileNet的加速
此外,我們將MobileNet的FLOP降低了2倍,達(dá)到了70.2%的Top-1最高精度,這比0.75 MobileNet的Pareto曲線要好,并且在Titan XP實(shí)現(xiàn)了1.53倍的加速,在一部Android手機(jī)實(shí)現(xiàn)1.95的加速。
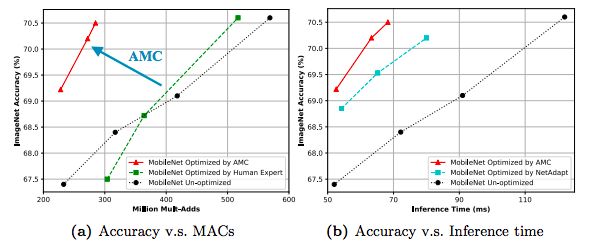
AMC和人類專家對(duì)MobileNet進(jìn)行壓縮的精度比較和推理時(shí)間比較
結(jié)論
傳統(tǒng)的模型壓縮技術(shù)使用手工的特征,需要領(lǐng)域?qū)<襾?lái)探索一個(gè)大的設(shè)計(jì)空間,并在模型的大小、速度和精度之間進(jìn)行權(quán)衡,但結(jié)果通常不是最優(yōu)的,而且很耗費(fèi)人力。
本文提出AutoML模型壓縮(AMC),利用增強(qiáng)學(xué)習(xí)自動(dòng)搜索設(shè)計(jì)空間,大大提高了模型壓縮質(zhì)量。我們還設(shè)計(jì)了兩種新的獎(jiǎng)勵(lì)方案來(lái)執(zhí)行資源受限壓縮和精度保證壓縮。
在Cifar和ImageNet上采用AMC方法對(duì)MobileNet、MobileNet- v2、ResNet和VGG等模型進(jìn)行壓縮,取得了令人信服的結(jié)果。壓縮模型可以很好滴從分類任務(wù)推廣到檢測(cè)任務(wù)。在谷歌Pixel 1手機(jī)上,我們將MobileNet的推理速度從8.1 fps提升到16.0 fps。AMC促進(jìn)了移動(dòng)設(shè)備上的高效深度神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4773瀏覽量
100890 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8424瀏覽量
132766 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
268瀏覽量
11267
原文標(biāo)題:AutoML自動(dòng)模型壓縮再升級(jí),MIT韓松團(tuán)隊(duì)利用強(qiáng)化學(xué)習(xí)全面超越手工調(diào)參
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
騰訊 AI Lab 開(kāi)源世界首款自動(dòng)化模型壓縮框架PocketFlow
基于ARM嵌入式系統(tǒng)的自動(dòng)化配送系統(tǒng)
深度強(qiáng)化學(xué)習(xí)實(shí)戰(zhàn)
啃論文俱樂(lè)部 | 壓縮算法團(tuán)隊(duì):我們是如何開(kāi)展對(duì)壓縮算法的學(xué)習(xí)
壓縮模型會(huì)加速推理嗎?
將深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)相結(jié)合的深度強(qiáng)化學(xué)習(xí)DRL
首款自動(dòng)化深度學(xué)習(xí)模型壓縮框架——PocketFlow
Waymo用AutoML自動(dòng)生成機(jī)器學(xué)習(xí)模型
機(jī)器學(xué)習(xí)中的無(wú)模型強(qiáng)化學(xué)習(xí)算法及研究綜述

模型化深度強(qiáng)化學(xué)習(xí)應(yīng)用研究綜述

預(yù)先設(shè)置NAS算法能否實(shí)現(xiàn)AutoML自動(dòng)機(jī)器學(xué)習(xí)革命

《自動(dòng)化學(xué)報(bào)》—多Agent深度強(qiáng)化學(xué)習(xí)綜述

VEGA:諾亞AutoML高性能開(kāi)源算法集簡(jiǎn)介

ICLR 2023 Spotlight|節(jié)省95%訓(xùn)練開(kāi)銷,清華黃隆波團(tuán)隊(duì)提出強(qiáng)化學(xué)習(xí)專用稀疏訓(xùn)練框架RLx2






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論