") 各種知識(shí)圖譜精化方法,為國(guó)內(nèi)同行介紹本領(lǐng)域的最新研究成果
各種知識(shí)圖譜精化方法,為國(guó)內(nèi)同行介紹本領(lǐng)域的最新研究成果
摘要:
知識(shí)圖譜是一種在移動(dòng)互聯(lián)網(wǎng)大時(shí)代下產(chǎn)生的新型知識(shí)表示方法,而精化是知識(shí)圖譜應(yīng)用研究的主要內(nèi)容之一,其主要任務(wù)是知識(shí)圖譜補(bǔ)全和錯(cuò)誤檢測(cè)等,在信息檢索、機(jī)器人、智能問(wèn)答等領(lǐng)域有著重要的應(yīng)用前景。因此,對(duì)知識(shí)圖譜精化進(jìn)行研究具有十分重要的意義。對(duì)當(dāng)前知識(shí)圖譜精化方法進(jìn)行了較為全面、深入的總結(jié),并對(duì)知識(shí)圖譜未來(lái)的主要研究方向進(jìn)行了展望。
?
0 引言
隨著鏈接開(kāi)放數(shù)據(jù)源(如DBpedia)的出現(xiàn)以及谷歌在2012年提出知識(shí)圖譜的概念,全球掀起了研究知識(shí)圖譜的熱潮,涌現(xiàn)出了大量的知識(shí)圖譜構(gòu)建技術(shù)[1-5],并構(gòu)建了各種知識(shí)圖譜,這些知識(shí)圖譜要么是開(kāi)放的,要么是公司私有的,如Freebase[2]、維基數(shù)據(jù)(Wikidata)[3]、DBpedia[4]、YAGO[5]等,但無(wú)論采用哪種技術(shù),構(gòu)造出來(lái)的知識(shí)圖譜都不完美[6]。隨著研究的深入,越來(lái)越多的研究者開(kāi)始關(guān)注知識(shí)圖譜的覆蓋率和正確率。而提高知識(shí)圖譜的覆蓋率和正確率是知識(shí)圖譜精化的主要目的,對(duì)知識(shí)圖譜進(jìn)行精化具有十分重要的意義。
近年來(lái),該領(lǐng)域的研究進(jìn)展非常迅速,涌現(xiàn)出了一大批研究成果,已經(jīng)研發(fā)出了多種知識(shí)圖譜精化方法,這些方法主要集中在討論知識(shí)圖譜補(bǔ)全[7-28]和知識(shí)圖譜錯(cuò)誤探測(cè)[29-34]兩個(gè)方面,這也是本文從這兩個(gè)方面進(jìn)行綜述的原因。
本文的貢獻(xiàn)是:(1)討論各種知識(shí)圖譜精化方法;(2)為國(guó)內(nèi)同行介紹本領(lǐng)域的最新研究成果,了解該領(lǐng)域的研究進(jìn)展,從而推動(dòng)我國(guó)在該領(lǐng)域的發(fā)展。
1 知識(shí)圖譜精化相關(guān)概念
1.1 知識(shí)圖譜的概念
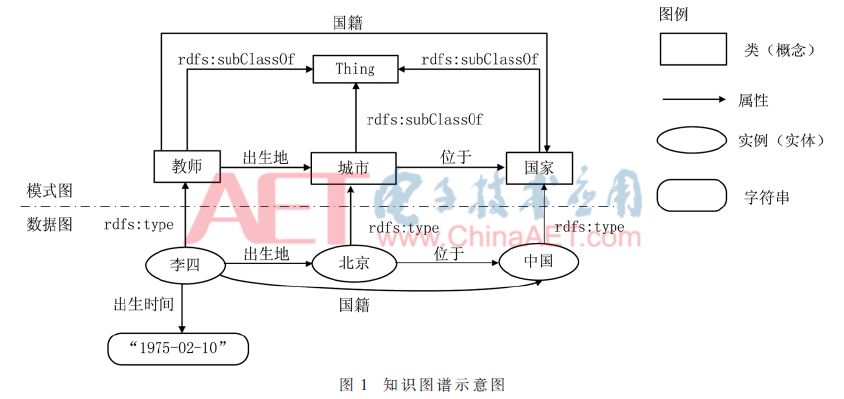
“知識(shí)圖譜”是一種描述真實(shí)世界客觀存在的實(shí)體、概念及它們之間關(guān)聯(lián)關(guān)系的語(yǔ)義網(wǎng)絡(luò)。可以利用知識(shí)圖譜開(kāi)發(fā)語(yǔ)義檢索和自動(dòng)問(wèn)答等應(yīng)用[1]。知識(shí)圖譜的結(jié)構(gòu)如圖1所示。可見(jiàn),知識(shí)圖譜是一個(gè)有向圖,由模式(schema)圖和數(shù)據(jù)圖構(gòu)成。其中,模式圖描述類之間的關(guān)系;數(shù)據(jù)圖描述實(shí)體之間的關(guān)系。圖1描述的知識(shí)(事實(shí))如下:
(1)李四是一個(gè)教師
(2)北京是一個(gè)城市
(3)中國(guó)是一個(gè)國(guó)家
(4)李四的出生地為北京
(5)北京位于中國(guó)
(6)李四的國(guó)籍是中國(guó)
1.2 知識(shí)圖譜構(gòu)建與知識(shí)圖譜精化
知識(shí)圖譜構(gòu)建是使用各種技術(shù)從無(wú)到有構(gòu)造知識(shí)圖譜,而知識(shí)圖譜精化是使用各種技術(shù)對(duì)知識(shí)圖譜進(jìn)行完善。可見(jiàn),要構(gòu)建一個(gè)完美的知識(shí)圖譜,需要經(jīng)過(guò)多個(gè)精化步驟。因此,知識(shí)圖譜構(gòu)建和知識(shí)圖譜精化是相輔相成、不可分割的。另外,本文將關(guān)系、文字和類型稱為精化目標(biāo)。
2 常用的知識(shí)圖譜補(bǔ)全方法
知識(shí)圖譜補(bǔ)全的目的是利用已有信息,預(yù)測(cè)丟失的實(shí)體、類型和實(shí)體間的關(guān)系,從而提高知識(shí)圖譜的覆蓋率。它是知識(shí)圖譜精化的主要任務(wù)之一,其對(duì)應(yīng)的精化目標(biāo)包括實(shí)體、類型和實(shí)體間的關(guān)系。但根據(jù)已有文獻(xiàn),發(fā)現(xiàn)目前該方面的研究主要集中在對(duì)類型和實(shí)體間的關(guān)系進(jìn)行精化。
本節(jié)根據(jù)知識(shí)圖譜補(bǔ)全使用的數(shù)據(jù)源,將知識(shí)圖譜補(bǔ)全方法分為知識(shí)圖譜內(nèi)部補(bǔ)全和知識(shí)圖譜外部補(bǔ)全兩大類。其中,知識(shí)圖譜內(nèi)部補(bǔ)全方法是指僅使用知識(shí)圖譜本身預(yù)測(cè)丟失信息的方法總稱,知識(shí)圖譜外部補(bǔ)全方法是指除使用知識(shí)圖譜本身以外,還使用其他數(shù)據(jù)源(如文本語(yǔ)料)來(lái)預(yù)測(cè)丟失信息的方法總稱。下面將從這兩個(gè)方面對(duì)知識(shí)圖譜錯(cuò)誤探測(cè)進(jìn)行綜述。
2.1 知識(shí)圖譜內(nèi)部補(bǔ)全方法
為了揭示內(nèi)部補(bǔ)全方法因精化目標(biāo)的不同而不同,本小節(jié)將根據(jù)精化目標(biāo)的不同,把內(nèi)部補(bǔ)全方法分成實(shí)體類型內(nèi)部補(bǔ)全和關(guān)系內(nèi)部預(yù)測(cè)兩類進(jìn)行綜述。
2.1.1 實(shí)體類型內(nèi)部補(bǔ)全
實(shí)體類型內(nèi)部補(bǔ)全就是利用知識(shí)圖譜本身已有的實(shí)體、實(shí)體類型和實(shí)體關(guān)系預(yù)測(cè)丟失的實(shí)體類型。
在機(jī)器學(xué)習(xí)領(lǐng)域,常用多分類方法對(duì)實(shí)體類型進(jìn)行補(bǔ)全。其中,PAULHEIM H等人[7-8]提出了一種基于條件概率的補(bǔ)全算法SDType,這種算法的思想是通過(guò)實(shí)體所具有的關(guān)系預(yù)測(cè)實(shí)體類型。SDType算法的評(píng)價(jià)矩陣是正確率(precision)、召回率和新增類型數(shù)目。但這種算法的缺點(diǎn)是假設(shè)關(guān)系之間是相互獨(dú)立的,而現(xiàn)實(shí)世界中這種假設(shè)在很多情況下是不成立的,并且該算法沒(méi)有用類型的層次結(jié)構(gòu)。利用SDType算法,已經(jīng)為知識(shí)圖譜DBpedia新增了3.4億條類型語(yǔ)句。KROMPA?覻 D等人[9]利用張量分解預(yù)測(cè)實(shí)體類型,這種方法的思想是把知識(shí)圖譜表示成一個(gè)實(shí)體-實(shí)體-關(guān)系的三維張量,然后通過(guò)張量分解的方法實(shí)現(xiàn)類型補(bǔ)全。該方法的評(píng)價(jià)矩陣是正確率、召回率和正確率-召回率曲線。張香玲等人[10]提出了一種由謂詞和謂詞及謂詞和類型的相互作用補(bǔ)全實(shí)體類型的模型,在該模型中,為了解決類型語(yǔ)義漂移,使用PMI技術(shù)設(shè)計(jì)一個(gè)有效的謂詞-類型推理圖及基于圖上的隨機(jī)游走算法。該模型的評(píng)價(jià)矩陣是正確率和召回率。SLEEMAN J等人[11]將主題模型用在關(guān)系預(yù)測(cè)中,這種方法的思想是首先將實(shí)體表示成文檔,應(yīng)用LDA抽取文檔的主題,然后通過(guò)分析主題和實(shí)體類型的共現(xiàn)關(guān)系,根據(jù)分析結(jié)果,將實(shí)體類型指派給主題對(duì)應(yīng)的實(shí)體。該方法的評(píng)價(jià)矩陣是正確率和召回率。
在數(shù)據(jù)挖掘領(lǐng)域,利用關(guān)聯(lián)規(guī)則預(yù)測(cè)知識(shí)圖譜丟失的信息。PAULHEIM H等人[12]基于數(shù)據(jù)冗余信息使用關(guān)聯(lián)規(guī)則來(lái)預(yù)測(cè)DBpedia中丟失的類型。這種方法的評(píng)價(jià)矩陣為正確率和增加的類型數(shù)。
2.1.2 關(guān)系內(nèi)部預(yù)測(cè)
按照相同的思路,在機(jī)器學(xué)習(xí)領(lǐng)域,也把預(yù)測(cè)關(guān)系的存在與否看成是一個(gè)二分類問(wèn)題。其中,SOCHER R等人[13]提出一種通過(guò)訓(xùn)練張量神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)新關(guān)系的方法。例如:如果一個(gè)人出生在德國(guó),那么該方法就能根據(jù)這個(gè)關(guān)系預(yù)測(cè)他的國(guó)籍是德國(guó)。這種方法的評(píng)價(jià)矩陣是精確率(accuracy),已被用于Freebase和WordNet中。BAIER S等人[14]也提出了類似的方法,但他們?cè)陬A(yù)測(cè)過(guò)程增加了模式知識(shí),以提高關(guān)系預(yù)測(cè)的性能。不同的是該方法的評(píng)價(jià)矩陣是正確率-召回率曲線面積和ROC曲線面積。類似地,ZHAO Y等人[15]通過(guò)將關(guān)系嵌入到一個(gè)低維空間中來(lái)預(yù)測(cè)Freebase中關(guān)系的存在,這種方法的評(píng)價(jià)矩陣是正確率。
同樣地,在數(shù)據(jù)挖掘領(lǐng)域,將關(guān)聯(lián)規(guī)則挖掘也用于預(yù)測(cè)關(guān)系。其中,KIM J等人[16]提出了一種利用關(guān)聯(lián)規(guī)則預(yù)測(cè)DBpdia中實(shí)體關(guān)系的方法。這種方法只能預(yù)測(cè)來(lái)自于維基百科分類中的實(shí)體關(guān)系,其評(píng)價(jià)矩陣是正確率和增加的關(guān)系數(shù)目。KOLTHOFF C等人[17]利用關(guān)聯(lián)規(guī)則挖掘思想查找意義豐富的關(guān)系鏈來(lái)預(yù)測(cè)關(guān)系,該方法的評(píng)價(jià)矩陣是正確率和召回率。
2.2 知識(shí)圖譜外部補(bǔ)全方法
與知識(shí)圖譜外部補(bǔ)全方法類似,為了揭示外部補(bǔ)全方法因精化目標(biāo)的不同而不同,本小節(jié)將根據(jù)精化目標(biāo)的不同,把外部補(bǔ)全方法分成實(shí)體類型外部補(bǔ)全和關(guān)系外部預(yù)測(cè)兩類進(jìn)行綜述。
2.2.1 實(shí)體類型外部補(bǔ)全
實(shí)體類型外部補(bǔ)全就是利用知識(shí)圖譜本身和外部數(shù)據(jù)來(lái)預(yù)測(cè)丟失的實(shí)體類型。根據(jù)已有文獻(xiàn)分析,實(shí)體類型外部補(bǔ)全方法的研究主要集中在機(jī)器學(xué)習(xí)和自然語(yǔ)言處理領(lǐng)域。
在機(jī)器學(xué)習(xí)領(lǐng)域,主要將外部數(shù)據(jù)表示成實(shí)體特征進(jìn)行分類。因?yàn)榫S基百科頁(yè)之間的鏈接沒(méi)有約束,所以維基百科網(wǎng)頁(yè)之間的鏈接比知識(shí)圖譜中相應(yīng)實(shí)體的鏈接要多。因此,NUZZOLESE A G等人[18]利用維基百科鏈接圖和KNN分類算法來(lái)預(yù)測(cè)知識(shí)圖譜中的實(shí)體類型。如果一個(gè)知識(shí)圖譜包含到維基百科的鏈接,那么就以相關(guān)頁(yè)的分類為基礎(chǔ),將維基百科網(wǎng)頁(yè)之間的鏈接表示成特征向量,這種方法的評(píng)價(jià)矩陣是正確率和召回率。APRIOSIO A P等人[19]將DBpedia各種語(yǔ)言版本中的實(shí)體類型作為特征來(lái)預(yù)測(cè)丟失的類型,該方法使用不同距離公式的K-NN分類器,綜合應(yīng)用這些不同的距離公式,得到了最好的結(jié)果。這種方法的評(píng)價(jià)矩陣是正確率和召回率。SLEEMAN J等人[20]將支持向量機(jī)用于DBpedia和Freebase中的實(shí)體類型預(yù)測(cè)。為了提高覆蓋率和正確率,作者利用知識(shí)圖譜間的內(nèi)部鏈接和其他知識(shí)圖譜的屬性對(duì)知識(shí)圖譜實(shí)例進(jìn)行分類,這種方法的評(píng)價(jià)矩陣為正確率和召回率。
在自然語(yǔ)言處理領(lǐng)域,KLIEGR T[21]等人使用了不同語(yǔ)言的摘要來(lái)進(jìn)行實(shí)體類型預(yù)測(cè),從而大大提高知識(shí)圖譜的覆蓋率和正確率,這種方法的評(píng)價(jià)矩陣是正確率和召回率。
2.2.2 關(guān)系外部預(yù)測(cè)
關(guān)系外部預(yù)測(cè)就是利用知識(shí)圖譜本身和外部數(shù)據(jù)來(lái)預(yù)測(cè)丟失的實(shí)體關(guān)系。
一部分研究者利用遠(yuǎn)程監(jiān)督法和自然語(yǔ)言處理方法對(duì)大規(guī)模文本語(yǔ)料庫(kù)進(jìn)行處理以預(yù)測(cè)實(shí)體關(guān)系,其思路為:首先,通過(guò)命名實(shí)體識(shí)別將知識(shí)圖譜中的實(shí)體鏈接到語(yǔ)料庫(kù)(如維基百科)中;然后,以知識(shí)圖譜已有的關(guān)系為基礎(chǔ),找到與關(guān)系對(duì)應(yīng)的文本模式,例如,“author”關(guān)系對(duì)應(yīng)的文本模式為“Y’s book X”;最后,利用已找到的文本模式去發(fā)現(xiàn)語(yǔ)料庫(kù)中的新關(guān)系。其中,APROSIO A P等人[22]將遠(yuǎn)程監(jiān)督法用于預(yù)測(cè)DBpedia中的關(guān)系,該方法將維基百科作為語(yǔ)料庫(kù),并且將正確率和召回率作為評(píng)價(jià)矩陣。GERBER D等人[23]也提出了類似的方法,并開(kāi)發(fā)了一個(gè)RdfLiveNews原型。在該原型中,利用新聞的RSS來(lái)解決DBpedia的時(shí)效性,即判斷預(yù)測(cè)到的新關(guān)系在DBpedia中屬于過(guò)時(shí)的關(guān)系還是丟失的關(guān)系。這種方法使用的評(píng)價(jià)矩陣是正確率、召回率和精確率。
一部分研究者利用Web搜索引擎填充知識(shí)圖譜[24]。和上述研究類似,這種方法首先找到關(guān)系對(duì)應(yīng)的詞匯,然后使用這些詞匯形成搜索語(yǔ)句以填充丟失的關(guān)系值。顯然,該方法使用整個(gè)網(wǎng)絡(luò)作為語(yǔ)料庫(kù),并使用信息提取和抽取技術(shù)進(jìn)行知識(shí)圖譜的補(bǔ)全。這種方法使用的評(píng)價(jià)矩陣是正確率、召回率和排名。
一部分研究者直接從網(wǎng)站的表格中抽取關(guān)系[25-26]。其中,HOGAN A等人[25]提出一種從維基百科表格中抽取關(guān)系的方法。他們認(rèn)為維基百科表格中共存的兩個(gè)實(shí)體共享知識(shí)圖譜中的一條邊,為了補(bǔ)全這些邊,首先使用已有關(guān)系從表格中抽取出候選實(shí)體集,然后對(duì)候選實(shí)體子集進(jìn)行標(biāo)注,最后基于已標(biāo)注的候選實(shí)體子集,使用分類算法來(lái)識(shí)別知識(shí)圖譜中真正成立的關(guān)系,這種方法使用的評(píng)價(jià)矩陣是正確率和召回率。RITZE D等人[26]將上述方法擴(kuò)展到任意的HTML表格中,該方法的不足是不僅要求表的列必須與DBpdedia本體中的屬性匹配,而且要求行也要與DBpdedia中的實(shí)體匹配。這種方法使用的評(píng)價(jià)矩陣是正確率和召回率。
一些研究者認(rèn)為許多自動(dòng)構(gòu)建的知識(shí)圖譜包含很多到其他知識(shí)圖譜的鏈接,可以利用這些鏈接對(duì)知識(shí)圖譜進(jìn)行融合。其中, DUTTA A等人[27]提出一種在知識(shí)圖譜之間建立概率映射的方法。這種方法首先以類型和屬性的分布概率為基礎(chǔ),創(chuàng)建知識(shí)圖譜之間的映射,然后利用該映射得到知識(shí)圖譜中丟失的事實(shí),最后,在兩個(gè)知識(shí)圖譜使用的類型系統(tǒng)之間建立映射。這樣就可以用一個(gè)知識(shí)圖譜的類型去預(yù)測(cè)另一個(gè)知識(shí)圖譜的類型。該方法利用黃金標(biāo)準(zhǔn)進(jìn)行評(píng)估,其評(píng)價(jià)矩陣是正確率和召回率。
另外,WANG Q等人[28]利用耦合的路徑排序算法補(bǔ)全知識(shí)圖譜。這種方法首先設(shè)計(jì)了一個(gè)聚類算法自動(dòng)發(fā)現(xiàn)彼此高度相關(guān)的關(guān)系,然后采用多任務(wù)學(xué)習(xí)策略對(duì)這些關(guān)系的預(yù)測(cè)進(jìn)行耦合,這樣是為了能夠利用關(guān)系之間的聯(lián)系和共享隱式數(shù)據(jù)。該方法使用的評(píng)價(jià)矩陣是平均正確率和平均倒數(shù)排名(Mean Reciprocal Rank)。
3 常用的知識(shí)圖譜錯(cuò)誤探測(cè)方法
與知識(shí)圖譜補(bǔ)全方法不同,知識(shí)圖譜錯(cuò)誤探測(cè)的目的是利用已有信息,識(shí)別圖中的錯(cuò)誤信息, 同樣,本節(jié)也將錯(cuò)誤探測(cè)分成內(nèi)部和外部?jī)深悺?/p>
3.1 知識(shí)圖譜錯(cuò)誤內(nèi)部探測(cè)方法
目前錯(cuò)誤內(nèi)部探測(cè)方法主要集中在文字值錯(cuò)誤和鏈接錯(cuò)誤上,因此本部分只對(duì)這兩類方法進(jìn)行綜述。
3.1.1 文字值錯(cuò)誤內(nèi)部檢測(cè)
異常檢測(cè)(Outlier detection)的目的是識(shí)別一個(gè)數(shù)據(jù)集中與大多數(shù)數(shù)據(jù)偏離的實(shí)例,即特征顯著的數(shù)據(jù)。由于異常檢測(cè)在許多情況下僅處理數(shù)值型數(shù)據(jù),因此數(shù)值型文字自然成為這些方法處理的對(duì)象。其中,WIENAND D等人[29]將不同的單變量異常值檢測(cè)方法(如四分位范圍或核密度估計(jì))用于DBpedia中,該方法使用正確率和新增文字?jǐn)?shù)作為評(píng)價(jià)矩陣。
為了降低自然異常的影響,F(xiàn)LEISCHHACKER D等人[30]對(duì)文獻(xiàn)[29]的方法進(jìn)行了擴(kuò)展,將實(shí)例集分成更小的子集,從而提高識(shí)別的正確率。這種方法還能使用其他知識(shí)圖譜預(yù)測(cè)交叉檢測(cè)異常,是內(nèi)部檢測(cè)和外部檢測(cè)方法的混合。
3.1.2 知識(shí)圖譜鏈接錯(cuò)誤內(nèi)部檢測(cè)
PAULHEIM H[31]指出異常檢測(cè)不僅可用于數(shù)值型數(shù)據(jù),還可用于知識(shí)圖譜的內(nèi)部鏈接。他首先將鏈接表示成多維特征向量,然后利用標(biāo)準(zhǔn)的異常檢測(cè)技術(shù)(如局部異常因素檢測(cè)、基于簇的異常檢測(cè))指派異常分?jǐn)?shù),基于這些異常分?jǐn)?shù)和所有鏈接的整體分布情況,能夠識(shí)別出不合理的鏈接。LI H等人[32]使用概率模型學(xué)習(xí)屬性之間的數(shù)學(xué)關(guān)系(如小于、大于),例如,一個(gè)人的出生日期必須在死亡日期之前。如果知識(shí)圖譜中有關(guān)系與這些關(guān)系不符,那么就說(shuō)明該關(guān)系是錯(cuò)誤的。
3.2 知識(shí)圖譜錯(cuò)誤外部探測(cè)
知識(shí)圖譜錯(cuò)誤外部探測(cè)就是除了利用知識(shí)圖譜本身外,還利用外部的資源來(lái)檢測(cè)錯(cuò)誤。外部探測(cè)方法主要集中在錯(cuò)誤關(guān)系探測(cè)和錯(cuò)誤文字值探測(cè)兩方面。所以,本小節(jié)將從這兩個(gè)方面進(jìn)行綜述。
3.2.1 錯(cuò)誤關(guān)系外部檢測(cè)
錯(cuò)誤關(guān)系外部檢測(cè)就是除了利用知識(shí)圖譜本身外,還利用外部的資源來(lái)檢測(cè)錯(cuò)誤的實(shí)體間關(guān)系。其中, PAULHEIM H等人認(rèn)為在知識(shí)圖譜構(gòu)造過(guò)程中大量的錯(cuò)誤都是由一個(gè)共同的原因(如錯(cuò)誤的映射或程序錯(cuò)誤)造成的,因此,只需檢測(cè)少量的樣本,就會(huì)發(fā)現(xiàn)大量錯(cuò)誤的語(yǔ)句。于是他們提出了一種識(shí)別不一致性的自動(dòng)化聚類方法[33],該方法只需要給人提供代表性的樣本即可,從而解決了上述的規(guī)模問(wèn)題。
3.2.2 錯(cuò)誤文字值外部檢測(cè)
文獻(xiàn)[34]提出了一種使用知識(shí)圖譜鏈接探測(cè)錯(cuò)誤數(shù)字值的自動(dòng)方法,作者利用相同資源的鏈接和單個(gè)資源中屬性之間的不同匹配函數(shù)來(lái)識(shí)別錯(cuò)誤。他們認(rèn)為如果多個(gè)外部資源與知識(shí)圖譜中的一個(gè)事實(shí)發(fā)生沖突,那么就認(rèn)為該事實(shí)是錯(cuò)的。
4 討論
通過(guò)文獻(xiàn)發(fā)現(xiàn),將知識(shí)圖譜精化方法分成知識(shí)圖譜補(bǔ)全和知識(shí)圖譜錯(cuò)誤探測(cè)兩大類是嚴(yán)謹(jǐn)?shù)摹R驗(yàn)槟壳盎静淮嬖谝粋€(gè)方法同時(shí)解決知識(shí)圖譜補(bǔ)全和知識(shí)圖譜錯(cuò)誤探測(cè)。唯一的例外是文獻(xiàn)[8],該文獻(xiàn)既能進(jìn)行知識(shí)圖譜補(bǔ)全又能進(jìn)行知識(shí)圖譜錯(cuò)誤探測(cè)。但它實(shí)際上是兩個(gè)方法,分別是SDType和SDValidate,因?yàn)檫@兩個(gè)方法不是一個(gè)整體,而是獨(dú)立存在的。其中SDType負(fù)責(zé)進(jìn)行補(bǔ)全,SDValidate負(fù)責(zé)進(jìn)行錯(cuò)誤探測(cè)。在知識(shí)圖譜精化方面,為什么大量的研究成果都只用在一個(gè)方面,這個(gè)原因還不太明確。但在客觀世界中,知識(shí)圖譜補(bǔ)全和知識(shí)圖譜錯(cuò)誤探測(cè)這兩個(gè)過(guò)程是相輔相成的。除了將補(bǔ)全和錯(cuò)誤檢測(cè)嚴(yán)格區(qū)別以外,還發(fā)現(xiàn)多數(shù)方法只能處理一種精化目標(biāo),同時(shí)處理多種精化目標(biāo)的方法相當(dāng)少。因此,將每類精化任務(wù)按照精化目標(biāo)進(jìn)行分類這也是嚴(yán)謹(jǐn)?shù)摹?/p>
在知識(shí)圖譜補(bǔ)全方面,本文所介紹的方法都是對(duì)已有實(shí)體的類型或關(guān)系進(jìn)行補(bǔ)全。經(jīng)文獻(xiàn)分析,目前沒(méi)有方法能夠增加新的實(shí)體,這種實(shí)體集擴(kuò)展方法屬于NLP領(lǐng)域,但這種方法對(duì)于進(jìn)一步提高知識(shí)圖譜覆蓋率非常有用,尤其可以減少長(zhǎng)尾實(shí)體。可見(jiàn),研究增加新實(shí)體的方法也將是知識(shí)圖譜精化的一個(gè)新方向。
在知識(shí)圖譜錯(cuò)誤探測(cè)方面,所有方法都輸出一個(gè)潛在錯(cuò)誤的語(yǔ)句列表。但據(jù)筆者所知,只有文獻(xiàn)[33]能從錯(cuò)誤列表中發(fā)現(xiàn)知識(shí)圖譜模式的錯(cuò)誤。因?yàn)槟J绞侵R(shí)圖譜的一個(gè)基礎(chǔ)構(gòu)建,模式的錯(cuò)誤就會(huì)造成實(shí)體的關(guān)系錯(cuò)誤。可見(jiàn),探測(cè)模式錯(cuò)誤也將是知識(shí)圖譜精化的一個(gè)新方向。
在評(píng)價(jià)矩陣方面,發(fā)現(xiàn)大量的方法將正確率和召回率作為主要的評(píng)價(jià)矩陣,偶爾也有方法使用ROC曲線、精確率或均方根誤差;在評(píng)估方法方面,發(fā)現(xiàn)有一半以上的評(píng)估方法只使用DBpedia這樣一種知識(shí)圖譜,這樣的評(píng)估結(jié)果的作用非常有限。因?yàn)榇蠖鄶?shù)的研究只對(duì)特定的知識(shí)圖譜有用,但知識(shí)圖譜根據(jù)特征的不同而不同。因此,對(duì)于只用一種知識(shí)圖譜評(píng)估的方法來(lái)說(shuō),有以下問(wèn)題值得研究:(1)能否在不用特征的知識(shí)圖譜上有同樣的性能;(2)在精化過(guò)程中是否用了知識(shí)圖譜本身的特征,如是否隱含地使用DBpedia實(shí)體和對(duì)應(yīng)的維基百科頁(yè)之間的鏈接;(3)是否過(guò)度擬合圖譜的特定特征。另外,還發(fā)現(xiàn)只有少數(shù)評(píng)價(jià)方法對(duì)計(jì)算性能進(jìn)行評(píng)估。但在大規(guī)模知識(shí)圖譜階段,計(jì)算性能這個(gè)指標(biāo)是一個(gè)不可忽視的維度。為了將來(lái)有一個(gè)可比較的知識(shí)圖譜評(píng)價(jià)方法,需要選一個(gè)既在數(shù)量上可比較、也在計(jì)算性能上可比較的基準(zhǔn)(benchmark)。目前這樣的研究工作在語(yǔ)義網(wǎng)絡(luò)的其他領(lǐng)域(如模式和實(shí)例匹配、推理和問(wèn)答系統(tǒng))已經(jīng)開(kāi)展。可見(jiàn),知識(shí)圖譜精化的通用評(píng)價(jià)方法將是知識(shí)圖譜精化的另一個(gè)方向。
5 結(jié)論
多年來(lái),許多研究者提出了各種知識(shí)圖譜精化方法,取得了豐碩的研究成果。由此可以預(yù)見(jiàn),知識(shí)圖譜精化研究將是一個(gè)有著非常廣闊研究前景的領(lǐng)域。
本文對(duì)知識(shí)圖譜精化方法進(jìn)行了綜述。綜述結(jié)果表明,該分類標(biāo)準(zhǔn)是嚴(yán)謹(jǐn)?shù)摹VR(shí)圖譜精化涉及機(jī)器學(xué)習(xí)、統(tǒng)計(jì)學(xué)和NLP相關(guān)知識(shí)和技術(shù),是一個(gè)綜合的研究方向。幾乎沒(méi)有一個(gè)精化方法能同時(shí)提高知識(shí)圖譜的完備性和正確率,也沒(méi)有方法對(duì)多個(gè)精化目標(biāo)進(jìn)行精化,即還沒(méi)有一個(gè)改善知識(shí)圖譜質(zhì)量的整體解決方案。在評(píng)價(jià)方面,多數(shù)評(píng)價(jià)方法通常都是在一個(gè)特定的知識(shí)圖譜上進(jìn)行評(píng)價(jià),這使得難以對(duì)它們的性能進(jìn)行比較。
綜上所述,雖然知識(shí)圖譜精化已經(jīng)取得了豐碩的研究成果,并且已成功應(yīng)用于許多領(lǐng)域,但仍然還不成熟,依然有很大的挑戰(zhàn)。將來(lái)可從以下幾個(gè)方面對(duì)知識(shí)圖譜精化進(jìn)行深入的研究:(1)改善知識(shí)圖譜質(zhì)量的整體解決方案;(2)知識(shí)圖譜擴(kuò)展性的研究;(3)知識(shí)圖譜通用的評(píng)價(jià);(4)未知領(lǐng)域知識(shí)圖譜的構(gòu)建。隨著大規(guī)模網(wǎng)絡(luò)知識(shí)圖譜的出現(xiàn),知識(shí)圖譜的擴(kuò)展和自動(dòng)化的知識(shí)圖譜精化將是該領(lǐng)域未來(lái)發(fā)展的趨勢(shì)。
-
移動(dòng)互聯(lián)網(wǎng)
+關(guān)注
關(guān)注
5文章
598瀏覽量
34059 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8406瀏覽量
132565 -
知識(shí)圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
7703
原文標(biāo)題:【學(xué)術(shù)論文】知識(shí)圖譜精化研究綜述
文章出處:【微信號(hào):ChinaAET,微信公眾號(hào):電子技術(shù)應(yīng)用ChinaAET】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
NLPIR系統(tǒng)KGB知識(shí)圖譜引擎為數(shù)據(jù)內(nèi)容安全設(shè)崗
NLPIR大數(shù)據(jù)知識(shí)圖譜完美展現(xiàn)文本數(shù)據(jù)內(nèi)容
NLPIR在文本信息提取方面的優(yōu)勢(shì)介紹
KGB知識(shí)圖譜基于傳統(tǒng)知識(shí)工程的突破分析
KGB知識(shí)圖譜技術(shù)能夠解決哪些行業(yè)痛點(diǎn)?
知識(shí)圖譜的三種特性評(píng)析
KGB知識(shí)圖譜通過(guò)智能搜索提升金融行業(yè)分析能力
領(lǐng)域知識(shí)圖譜落地實(shí)踐中的問(wèn)題與對(duì)策
知識(shí)圖譜已經(jīng)取得了哪些學(xué)術(shù)與技術(shù)成果,產(chǎn)業(yè)與應(yīng)用發(fā)生了哪些變化?
知識(shí)圖譜劃分的相關(guān)算法及研究

知識(shí)圖譜在工程應(yīng)用中的關(guān)鍵技術(shù)、應(yīng)用及案例

數(shù)學(xué)課程知識(shí)圖譜構(gòu)建研究應(yīng)用綜述
《無(wú)線電工程》—基于知識(shí)圖譜的直升機(jī)飛行指揮模型研究
知識(shí)圖譜:知識(shí)圖譜的典型應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論