") 如何完成從Pandas到Scikit-Learn這一令人興奮的工作流
如何完成從Pandas到Scikit-Learn這一令人興奮的工作流
近日,Scikit-Learn 發(fā)布了 0.20 版本,這是近年來(lái)最大的一次更新。對(duì)許多數(shù)據(jù)科學(xué)家來(lái)說(shuō),一個(gè)典型的工作流會(huì)在使用 Scikit-Learn 進(jìn)行機(jī)器學(xué)習(xí)之前,先通過(guò) Pandas 對(duì)數(shù)據(jù)進(jìn)行分析,而新的版本就將這一過(guò)程進(jìn)行了簡(jiǎn)化,并且功能更加多樣、穩(wěn)定與標(biāo)準(zhǔn)。
今天,我們將通過(guò) Ted Petrou 的一篇技術(shù)文章,為大家介紹如何完成從 Pandas 到 Scikit-Learn 這一令人興奮的工作流,并且作者基于 Kaggle 上入門(mén)級(jí)機(jī)器學(xué)習(xí)競(jìng)賽之一:Housing Prices: Advanced Regression Techniques 作為案例實(shí)踐分析,讓大家可以更好地理解與使用這一工具。
全文概括及目標(biāo)
通過(guò)本文,那些將 Scikit-Learn 作為機(jī)器學(xué)習(xí)庫(kù),但依賴 Pandas 進(jìn)行數(shù)據(jù)探索和準(zhǔn)備工作的用戶一定可以收益良多。(假設(shè)你對(duì) Scikit-Learn 和 Pandas 都有所了解)
我們會(huì)探索新的估計(jì)器ColumnTransformer,它使得我們可以對(duì)數(shù)據(jù)的不同子集單獨(dú)且并行地進(jìn)行轉(zhuǎn)換,然后再把結(jié)果串接在一起。
用列中的字符串?dāng)?shù)據(jù)來(lái)創(chuàng)建供 pandas 使用的數(shù)據(jù)框,這一過(guò)程應(yīng)該更加標(biāo)準(zhǔn)化。
估計(jì)器OneHotEncoder在對(duì)列的字符串?dāng)?shù)據(jù)編碼方面有所提升。
為了便于獨(dú)熱編碼 (one-hot encoding),我們使用新的估計(jì)器SimpleImputer來(lái)用常數(shù)填充缺失值。
我們會(huì)自定義一個(gè)估計(jì)器,該估計(jì)器將取代 Scikit-Learn 的內(nèi)置工具,來(lái)執(zhí)行對(duì)數(shù)據(jù)框的全部基本轉(zhuǎn)換操作。
最后,我們會(huì)基于新的估計(jì)器KBinsDiscretizer對(duì)數(shù)值進(jìn)行二進(jìn)制轉(zhuǎn)換 。
注:作者是在0.20 版本還沒(méi)有正式發(fā)布前完成的這個(gè)教程,以后這個(gè)教程很可能會(huì)在某些方面內(nèi)容有所更新。
前言
Scikit-Learn 的機(jī)器學(xué)習(xí)模型要求輸入必須是二維的數(shù)值數(shù)據(jù)結(jié)構(gòu)。字符串?dāng)?shù)據(jù)是不被接受的。但始終沒(méi)有提供一個(gè)處理字符串列的標(biāo)準(zhǔn)方法,而字符串?dāng)?shù)據(jù)在數(shù)據(jù)科學(xué)中是一種極為普遍的存在。這也致使相關(guān)教程都在探索用不同的方法來(lái)處理字符串?dāng)?shù)據(jù)列。
有些解決方案傾向于用 Pandas 的get_dummies函數(shù);一些使用 Scikit-Learn 的獨(dú)熱編碼方法LabelBinarizer,但此方法是為類(lèi)別數(shù)據(jù)(目標(biāo)變量)設(shè)計(jì)的,而非面向輸入數(shù)據(jù);還有一些方案則創(chuàng)建了自定義的估計(jì)器;甚至還有整個(gè)的工具包,如 sklearn-pandas 就是為了解決這個(gè)問(wèn)題創(chuàng)造出來(lái)的。對(duì)那些想要基于字符串列來(lái)建機(jī)器學(xué)習(xí)模型的人來(lái)說(shuō),標(biāo)準(zhǔn)化方面的欠缺給他們帶來(lái)了糟糕的體驗(yàn);在轉(zhuǎn)換特定列而非整個(gè)數(shù)據(jù)集上的技術(shù)支持也比較薄弱。例如,將連續(xù)特征進(jìn)行標(biāo)準(zhǔn)化處理十分普遍,而對(duì)類(lèi)別特征來(lái)說(shuō)卻很少見(jiàn)。如今這方面會(huì)變得容易得多。
sklearn-pandas:
https://github.com/scikit-learn-contrib/sklearn-pandas
▌升級(jí)至 0.20 版
幾天前,0.20 版的第一個(gè)候選版本發(fā)布了。你可以用 conda 安裝它:

或者 pip 安裝:

▌ColumnTransformer & OneHotEncoder(升級(jí)版)簡(jiǎn)介
隨著版本更新至 0.20,從 Pandas 到 Scikit-Learn 的工作流應(yīng)該越來(lái)越相似了。估計(jì)器 ColumnTransformer 會(huì)對(duì) Pandas 數(shù)據(jù)框(或數(shù)組)中列的特定子集執(zhí)行轉(zhuǎn)換操作。
OneHotEncoder 并不是一個(gè)新的估計(jì)器,但它已更新至可以編碼字符串?dāng)?shù)據(jù)列。此前,它只能對(duì)包含數(shù)值形式的類(lèi)別數(shù)據(jù)進(jìn)行編碼。
接下來(lái)讓我們看看,這些新特性將如何處理 Pandas 數(shù)據(jù)框中的字符串?dāng)?shù)據(jù)列。
初體驗(yàn)
通過(guò) Kaggle 房屋數(shù)據(jù)集小試牛刀
Housing Prices: Advanced Regression Techniques 是 Kaggle 的入門(mén)級(jí)機(jī)器學(xué)習(xí)競(jìng)賽之一。該競(jìng)賽目標(biāo)是基于給定的80個(gè)特征,來(lái)預(yù)測(cè)房屋價(jià)格。特征列是由連續(xù)特征和類(lèi)別特征混雜成的。你可以從網(wǎng)站直接下載數(shù)據(jù)或使用他們的命令行工具。
參考鏈接:
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
https://github.com/Kaggle/kaggle-api
▌?dòng)^察數(shù)據(jù)
首先我們來(lái)看看數(shù)據(jù)框,并輸出頭幾行數(shù)據(jù)。



▌將目標(biāo)變量從訓(xùn)練集中移除
我們要移除的目標(biāo)變量是 SalePrice,然后將其以數(shù)組的形式賦值給它本身。我們之后做機(jī)器學(xué)習(xí)時(shí)會(huì)用到它。

▌單個(gè)字符串列的編碼
首先,我們對(duì)一個(gè)單獨(dú)的字符串列HouseStyle進(jìn)行編碼,該列含有關(guān)于房屋外部情況的數(shù)據(jù)。讓我們輸出一下每個(gè)不同字符串的個(gè)數(shù)。

可見(jiàn)在這一列中,我們有8個(gè)不同的值。
▌Scikit-Learn 必須基于 2D 數(shù)據(jù)
大多數(shù) Scikit-Learn 估計(jì)器都要求數(shù)據(jù)為嚴(yán)格的二維形式。如果我們選擇上面提到的所有列作為train['HouseStyle'],技術(shù)上來(lái)講,一維數(shù)據(jù)形式的 Pandas Series 就隨之產(chǎn)生了。我們可以通過(guò)將列表傳入空白數(shù)據(jù)框,來(lái)強(qiáng)制 Pandas 創(chuàng)建一個(gè)單列數(shù)據(jù)框:

▌轉(zhuǎn)換器三部曲 —— 導(dǎo)入、實(shí)例化、調(diào)試
Scikit-Learn 的 API 對(duì)于所有估計(jì)器都是一致的,即通過(guò)固定三個(gè)步驟的過(guò)程來(lái)訓(xùn)練數(shù)據(jù)。
根據(jù)不同的模塊,引入我們需要的估計(jì)器;
對(duì)估計(jì)器進(jìn)行實(shí)例化,改變其默認(rèn)配置;
基于數(shù)據(jù)對(duì)估計(jì)器進(jìn)行調(diào)試。如果需要,將數(shù)據(jù)轉(zhuǎn)換到新的地方。
下面我們引入OneHotEncoder,并將其實(shí)例化,確保我們得到的返回?cái)?shù)組中不存在缺失值,然后用fit_transform方法對(duì)我們的單列數(shù)據(jù)編碼。

和我們預(yù)期的一樣,它把所有不同的值都編碼成為了二進(jìn)制的列。

▌?dòng)辛?NumPy 數(shù)組,列名是什么呢?
值得注意的一點(diǎn)是,我們輸出的是 NunPy 數(shù)組而非 Pandas 數(shù)據(jù)框。起初 Scikit-Learn 并不是與 Pandas 可以直接整合的。所有的 Pandas 對(duì)象都被轉(zhuǎn)化成了 NumPy 數(shù)組,NumPy 數(shù)組都是由轉(zhuǎn)換操作生成的。
通過(guò)get_feature_names方法,我們?nèi)钥梢詮腛neHotEncoder對(duì)象中獲得列名。

▌驗(yàn)證第一行數(shù)據(jù)
驗(yàn)證估計(jì)器的運(yùn)行是否正常是很有必要的。讓我們看一下編碼后的數(shù)據(jù)的第一行:

這里將數(shù)組中的第6個(gè)值編碼成了1。我們用布爾值作為索引調(diào)出特征名字。

現(xiàn)在,我們來(lái)驗(yàn)證初始數(shù)據(jù)框的列中第一個(gè)值是與之相同的。

▌利用 inverse_transform 自動(dòng)化該過(guò)程
就像大多數(shù)轉(zhuǎn)換器對(duì)象一樣,方法inverse_transform方法可以幫你獲取原始數(shù)據(jù)。這里我們把row0放進(jìn)列表中,使其變成二維數(shù)組。

我們可以通過(guò)將整個(gè)數(shù)組進(jìn)行反轉(zhuǎn),來(lái)驗(yàn)證所有的值。

▌將轉(zhuǎn)換器作用于測(cè)試集
無(wú)論我們對(duì)測(cè)試集使用什么轉(zhuǎn)換器,我們必須對(duì)測(cè)試集也使用。讓我們來(lái)看看測(cè)試集,并獲取同樣的列,對(duì)其使用我們的轉(zhuǎn)換器。

我們又獲得了8個(gè)列。

這個(gè)例子證明了我們的觀點(diǎn),但還有幾個(gè)我們可能遇到的問(wèn)題,現(xiàn)在讓我們一一來(lái)看都有哪些。
難點(diǎn)
▌1. 測(cè)試集中不存在的類(lèi)別
如果我們現(xiàn)有一座房屋,其特征是測(cè)試集中不存在的,這種情況怎么辦呢?比如現(xiàn)有一個(gè)特征3Story。現(xiàn)在我們改變房屋特征的第一個(gè)值,然后看看會(huì)產(chǎn)生什么結(jié)果。

根據(jù)默認(rèn)設(shè)置,我們的編碼器會(huì)生成一個(gè)錯(cuò)誤。這是我們所期待的,因?yàn)槲覀円獣允欠裼袦y(cè)試集中不存在的字符串。如果你也存在這個(gè)問(wèn)題,那么你的探索可能需要更加深入了。現(xiàn)在我們通過(guò)將參數(shù) handle_unknown 設(shè)置為 'ignore' 來(lái)忽略這一未知元素,并將這一行都編碼為0。

我們來(lái)驗(yàn)證一下第一行均為0.

▌2 . 測(cè)試集中的缺失值
如果你的測(cè)試集中存在缺失值(NaN 或 None),只要將 handle_unknown 設(shè)置為 'ignore',缺失值就可以被忽略。現(xiàn)在我們?yōu)闇y(cè)試集的前兩個(gè)元素加入缺失值。

▌3.訓(xùn)練集中的缺失值
訓(xùn)練集中存在缺失值是更為嚴(yán)重的問(wèn)題。到目前為止,估計(jì)器OneHotEncoder還無(wú)法很好地解決缺失值問(wèn)題。

如果像測(cè)試集一樣,也有一個(gè)方法可以忽略訓(xùn)練集中的缺失值就好了。目前這種方法并不存在,我們只能對(duì)缺失值進(jìn)行填充。
現(xiàn)在,我們必須對(duì)這些缺失值加以填充。預(yù)處理模塊中老的Imputer已經(jīng)被棄用了。在同樣的位置創(chuàng)建了一個(gè)新模塊impute,配合新的估計(jì)器SimpleImputer和新方案“常數(shù)”。若采用默認(rèn)設(shè)置,這一方案會(huì)用字符串 'missing_value' 來(lái)填充缺失值。我們可以通過(guò)參數(shù) fill_value 來(lái)設(shè)置這個(gè)值。

到了這里,我就可以像之前那樣進(jìn)行編碼了。

要注意的一點(diǎn)是,現(xiàn)在我們有額外的一個(gè)列和特證名。

技能升級(jí)
實(shí)踐整個(gè)轉(zhuǎn)換工作
▌對(duì)測(cè)試集執(zhí)行兩次轉(zhuǎn)換
我們可以手動(dòng)依次執(zhí)行上述兩個(gè)步驟,如下:

▌Pipeline 的使用
Scikit-Learn 提供了 Pipeline 估計(jì)器,它包括一系列轉(zhuǎn)換操作,可以將它們一一執(zhí)行。你可以把機(jī)器學(xué)習(xí)模型作為最終的估計(jì)器來(lái)運(yùn)行。現(xiàn)在我們對(duì)缺失值進(jìn)行簡(jiǎn)單的填充并編碼。

每個(gè)步驟都是一個(gè)二元組,包括一個(gè)代表該步驟的字符串和實(shí)例化的估計(jì)器。上個(gè)步驟的輸出是下個(gè)步驟的輸入。

只要將測(cè)試集傳入 transform 方法,它就可以基于 pipeline 的每一個(gè)步驟進(jìn)行轉(zhuǎn)換。

▌多字符串列的轉(zhuǎn)換
對(duì)含有多個(gè)字符串的列進(jìn)行轉(zhuǎn)換并不是難題。選中你要處理的列,然后基于同一個(gè) pipeline 再傳入新的數(shù)據(jù)框。

▌獲取 pipeline 的片段
我們可以通過(guò)從屬性字典獲取名字,來(lái)獲取 pipeline 內(nèi)每個(gè)單獨(dú)的轉(zhuǎn)換器。在這個(gè)例子中,我們獲取了一個(gè)獨(dú)熱編碼器,然后輸出特征名字。

▌使用新的 ColumnTransformer 選擇列
全新的ColumnTransformer允許我們?yōu)椴煌牧羞x擇不同的轉(zhuǎn)換器。類(lèi)別數(shù)據(jù)列比連續(xù)數(shù)據(jù)列往往更需要進(jìn)行單獨(dú)轉(zhuǎn)換。
ColumnTransformer目前還處于試驗(yàn)階段,也就說(shuō)未來(lái)可能有所變化。
ColumnTransformer包括一個(gè)三元組列表。元組的第一個(gè)值是特征名,第二個(gè)是實(shí)例化的估計(jì)器,第三個(gè)是一系列你想要執(zhí)行轉(zhuǎn)換操作的列。該元組的形式如下:

此處的 columns 不一定非要是列名,你也可以用列的整數(shù)索引值來(lái)代替,或者一個(gè)布爾數(shù)組,甚至可以用一個(gè)函數(shù)(該函數(shù)要將整個(gè)數(shù)據(jù)框作為參數(shù),并返回所選的列)。
你也可以選擇 NumPy 數(shù)組與ColumnTransformer配合使用,但本教程著重于和 Pandas 的整合,所以我們?nèi)圆捎脭?shù)據(jù)框進(jìn)行討論。
▌將 Pipeline 傳入 ColumnTransformer
我們甚至可以將一個(gè)含有多個(gè)轉(zhuǎn)換器的 pipeline 傳入列的轉(zhuǎn)換器,下面我們就要這么做,因?yàn)槲覀兊淖址行枰鄠€(gè)轉(zhuǎn)換器。
接下來(lái),我們重復(fù)上面的缺失值填充步驟,并用ColumnTransformer進(jìn)行編碼。要注意的是 pipeline 和上面是相同的,只是每個(gè)變量名后加了個(gè)cat。在下個(gè)部分中,我們會(huì)為數(shù)值列添加一個(gè)不同的 pipeline。

▌將整個(gè)數(shù)據(jù)框傳入 ColumnTransformer
ColumnTransformer實(shí)例選擇了我們要使用的列,所以我們將整個(gè)數(shù)據(jù)框傳入fit_transform方法。

現(xiàn)在我們可以通過(guò)同樣的方式將測(cè)試集進(jìn)行轉(zhuǎn)換。

▌獲取特征名
我們必須花時(shí)間要做的一個(gè)事情就是去獲取特征的名字。所有轉(zhuǎn)換器都存儲(chǔ)在屬性字典 named_transformers_ 中。接下來(lái),我們可以通過(guò)名字以及三元組的第一個(gè)元素來(lái)選取特定的轉(zhuǎn)換器。下面就是我們選擇轉(zhuǎn)換器的過(guò)程(此處只有一個(gè)轉(zhuǎn)換器,即一個(gè)名為 'cat' 的 pipeline)。

接下來(lái),我們從 pipeline 選取獨(dú)熱編碼器對(duì)象,并獲得特征名。

▌數(shù)值列的轉(zhuǎn)換
數(shù)值列需要一組不同的轉(zhuǎn)換器。數(shù)值列中的缺失值通常由中位值或平均值來(lái)填充,而非一個(gè)常數(shù)。而且我們常通過(guò)減去每列平均值或除以標(biāo)準(zhǔn)差的方式對(duì)其進(jìn)行標(biāo)準(zhǔn)化,而不是對(duì)它們的值直接編碼。這種方法有助于許多模型得到更好的效果,如嶺回歸模型。
▌?wù){(diào)用所有數(shù)值列
我們可以選擇所有的數(shù)值列,而非像上面那樣手動(dòng)選擇一兩個(gè)字符串列。我們通過(guò)根據(jù)dtypes屬性直接搜尋每一列的數(shù)據(jù)類(lèi)型來(lái)實(shí)現(xiàn)這一目的,然后檢查每個(gè)dtype的kind(類(lèi)型)是否為 'O'。dtypes屬性會(huì)返回一系列 Numpydtype對(duì)象。其中每一個(gè)都包含kind屬性,這些屬性都由一個(gè)字符表示。我們可以基于此去搜尋數(shù)值或字符串列。Pandas 將所有的字符串列作為object(對(duì)象)進(jìn)行儲(chǔ)存,等同于 'O' 的類(lèi)型。關(guān)于kind這個(gè)屬性的更多介紹可以參考 NumPy 文檔。
NumPy 文檔:
https://docs.scipy.org/doc/numpy/reference/generated/numpy.dtype.kind.html

得到了類(lèi)別,然后用一個(gè)字符來(lái)表示這些數(shù)據(jù)類(lèi)型。

現(xiàn)假設(shè)所有數(shù)值列都不是對(duì)象。我們也可以通過(guò)這種方式來(lái)獲取特征列。

一旦我們獲得了數(shù)值列的名字,我們就可以再次使用ColumnTransformer了。

▌將特征列和數(shù)值列的轉(zhuǎn)換器相結(jié)合
基于ColumnTransformer,我們可以分別對(duì)數(shù)據(jù)框的每個(gè)部分進(jìn)行單獨(dú)轉(zhuǎn)換。在這個(gè)例子中我們會(huì)使用每個(gè)單獨(dú)列。
接下來(lái)我們?yōu)樘卣髁泻蛿?shù)值列共同創(chuàng)建一個(gè)單獨(dú)的 pipeline,然后用ColumnTransformer來(lái)對(duì)它們進(jìn)行單獨(dú)轉(zhuǎn)換。這兩個(gè)轉(zhuǎn)換器是并行工作的,然后再把兩個(gè)結(jié)果整合在一起。
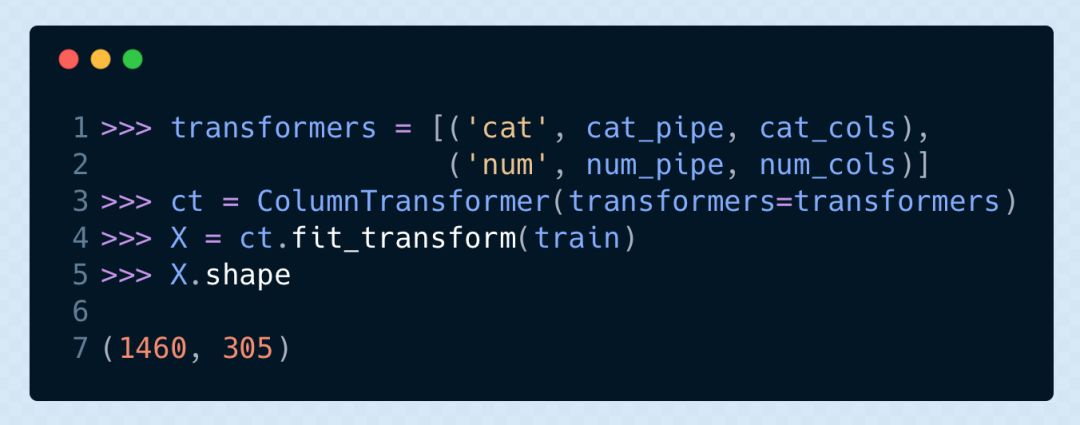
進(jìn)行機(jī)器學(xué)習(xí)
這些工作的全部意義在于布置我們的數(shù)據(jù),以便于我們接下來(lái)的機(jī)器學(xué)習(xí)環(huán)節(jié)。我們可以創(chuàng)建最終版 pipeline,并添加一個(gè)機(jī)器學(xué)習(xí)模型作為最后的估計(jì)器。pipeline 的第一步是我們上面提到的整個(gè)轉(zhuǎn)換環(huán)節(jié)。我們將房屋的出售價(jià)格SalePrice設(shè)為y。這里我們用fit方法來(lái)代替 fit_transform,因?yàn)樽詈笠粋€(gè)環(huán)節(jié)是機(jī)器學(xué)習(xí)模型,不需要轉(zhuǎn)換操作。

我們可以用 score 方法來(lái)評(píng)估模型,返回的值為 R-square(確定系數(shù)):

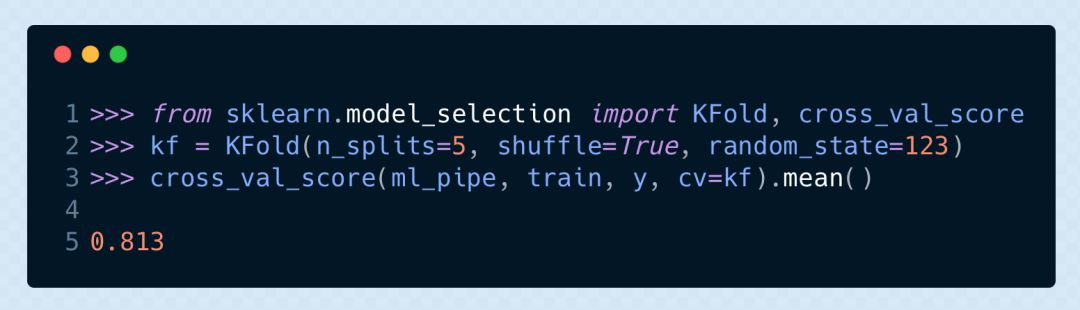
模型的表現(xiàn):交叉驗(yàn)證
當(dāng)然了,用訓(xùn)練集本身來(lái)驗(yàn)證模型是毫無(wú)意義的。讓我們做一下 K 折交叉驗(yàn)證,來(lái)看看模型對(duì)于未見(jiàn)過(guò)的數(shù)據(jù)有什么表現(xiàn)。我們?cè)O(shè)置一個(gè)隨機(jī)數(shù),以確保在整個(gè)過(guò)程中都能按固定的隨機(jī)序列對(duì)原數(shù)據(jù)進(jìn)行劃分。
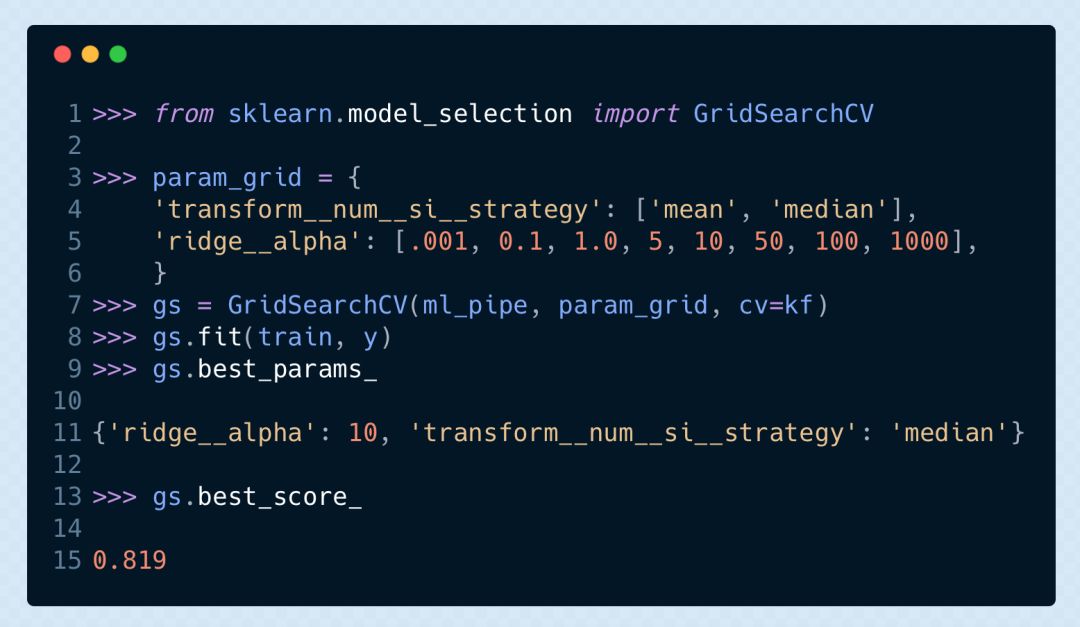
網(wǎng)格搜索的參數(shù)選擇
Scikit-Learn 的網(wǎng)格搜索需要我們傳入?yún)?shù)名字典,與可能的數(shù)值相映射。當(dāng)我們使用 pipeline 時(shí),必須在每一步的名字后加兩個(gè)下劃線,然后再接參數(shù)名。如果你的 pipeline 有多個(gè)層,我們必須再繼續(xù)加兩個(gè)下劃線來(lái)再提升一個(gè)層,直到我們能獲取需要優(yōu)化其參數(shù)的估計(jì)器。
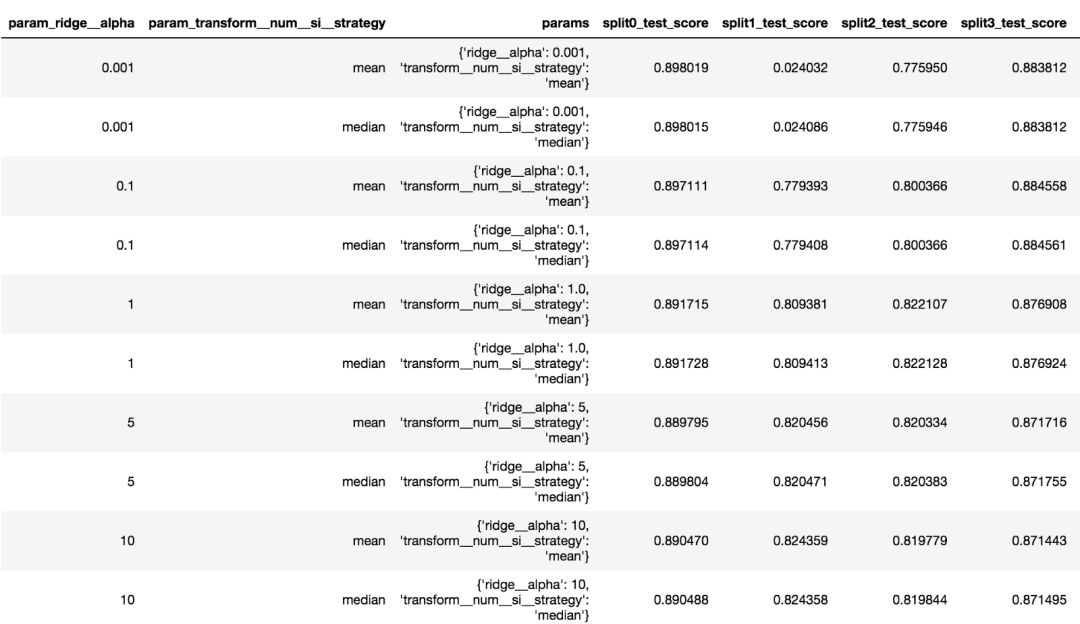
▌在 Pandas 數(shù)據(jù)框中獲得網(wǎng)格搜索的全部結(jié)果
網(wǎng)格搜索的全部結(jié)果被存儲(chǔ)在cv_results_中。為了便于展示,這是一個(gè)可以轉(zhuǎn)換為 Pandas 數(shù)據(jù)框的字典,而且它提供了更加便于手動(dòng)掃描的結(jié)構(gòu)。

一個(gè)完整 WorkFlow 還需要解決的問(wèn)題
▌創(chuàng)建含有全部基礎(chǔ)操作的自定義轉(zhuǎn)換器
上述討論的工作流還存在一些限制。例如,在我們使用fit方法時(shí),若OneHotEncoder可以提供忽略缺失值的選項(xiàng)就好了。比如,它可以將缺失值編碼為一行0。現(xiàn)在它強(qiáng)制我們用字符串來(lái)填充缺失值,并將這些字符串編碼成一個(gè)單獨(dú)的列。
▌自定義估計(jì)器類(lèi)
Scikit_Learn 的文檔提供了許多關(guān)于如何寫(xiě)估計(jì)器類(lèi)方面的指導(dǎo)。base 模塊中的BaseEstimator類(lèi)為我們提供了get_params和set_params方法。做網(wǎng)格搜索時(shí),set_params方法是必需的。你可以自己寫(xiě),或從 BaseEstimator 直接繼承。
Scikit_Learn 文檔:
http://scikit-learn.org/stable/developers/contributing.html#rolling-your-own-estimator
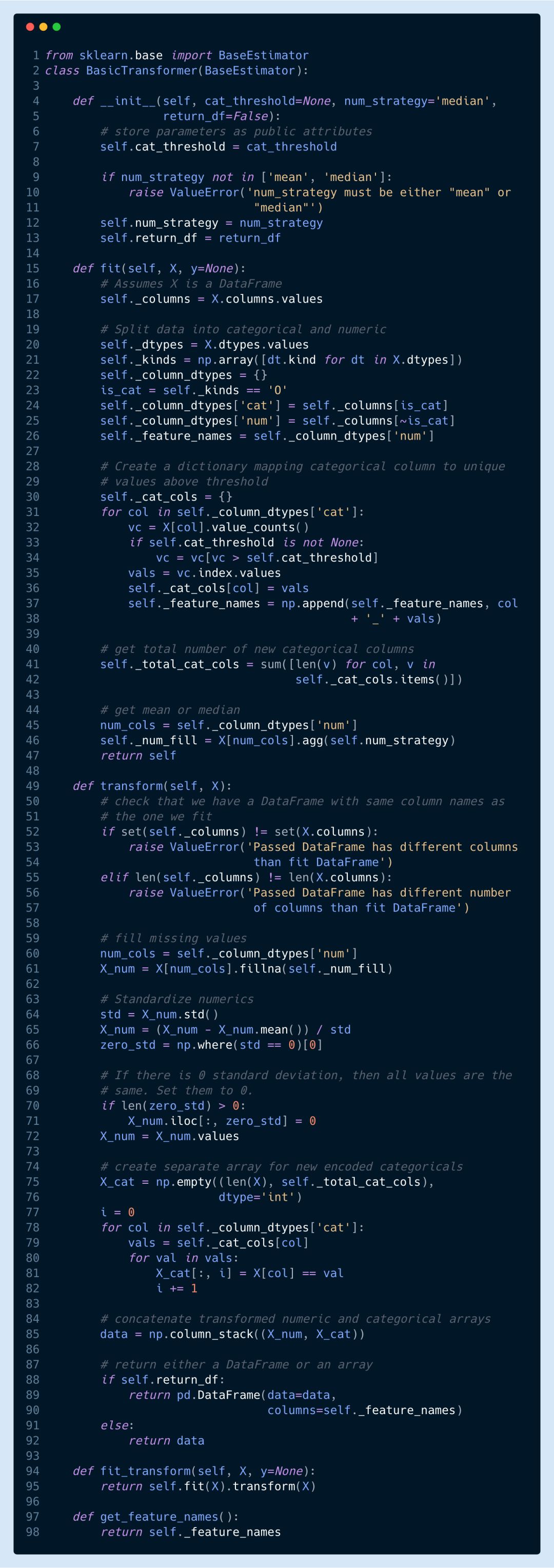
BasicTransformer 類(lèi)可以執(zhí)行下面一系列操作:
用平均值或中位值對(duì)數(shù)值列的缺失值進(jìn)行填充
將全部數(shù)值列做標(biāo)準(zhǔn)化處理
對(duì)字符串列采取獨(dú)熱編碼
不對(duì)特征列的缺失值加以填充,而是將它們編碼為0
忽略測(cè)試集字符串列中不存在的值
允許我們?yōu)樽址兄幸粋€(gè)值必須出現(xiàn)的次數(shù)設(shè)置閾值。該閾值以下的字符串都被編碼為0
大多數(shù)操作都是基本的轉(zhuǎn)換,對(duì)許多數(shù)據(jù)集來(lái)說(shuō)是必須執(zhí)行的。
▌BasicTransformer 的使用
BasicTransformer估計(jì)器的使用和其它的 scikit-learn 估計(jì)器一樣。我們可以將其實(shí)例化,然后轉(zhuǎn)換數(shù)據(jù)。


▌在 pipeline 中使用自定義轉(zhuǎn)換器
我們可以將自定義的轉(zhuǎn)換器設(shè)置為 pipeline 的一部分。

我們也可以用它做交叉驗(yàn)證,所得分?jǐn)?shù)與之前的分?jǐn)?shù)很相近。
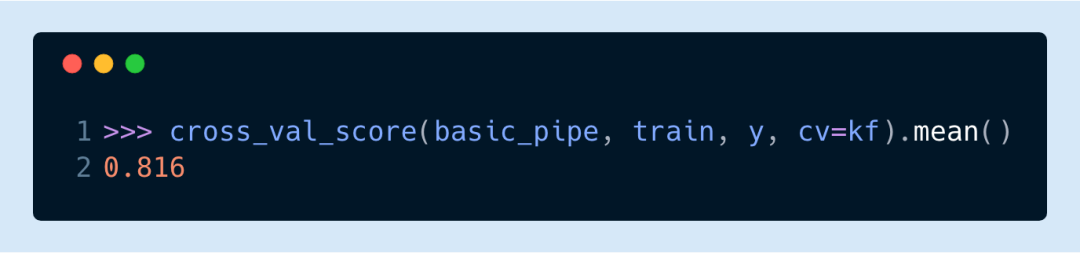
我們可以把它用作網(wǎng)格搜索的一部分。這證明了去掉低頻率字符串對(duì)該模型幫助不大,即使對(duì)其它模型有明顯的提升。最佳分?jǐn)?shù)有所提升,可能是因?yàn)槭褂昧瞬煌木幋a方式。
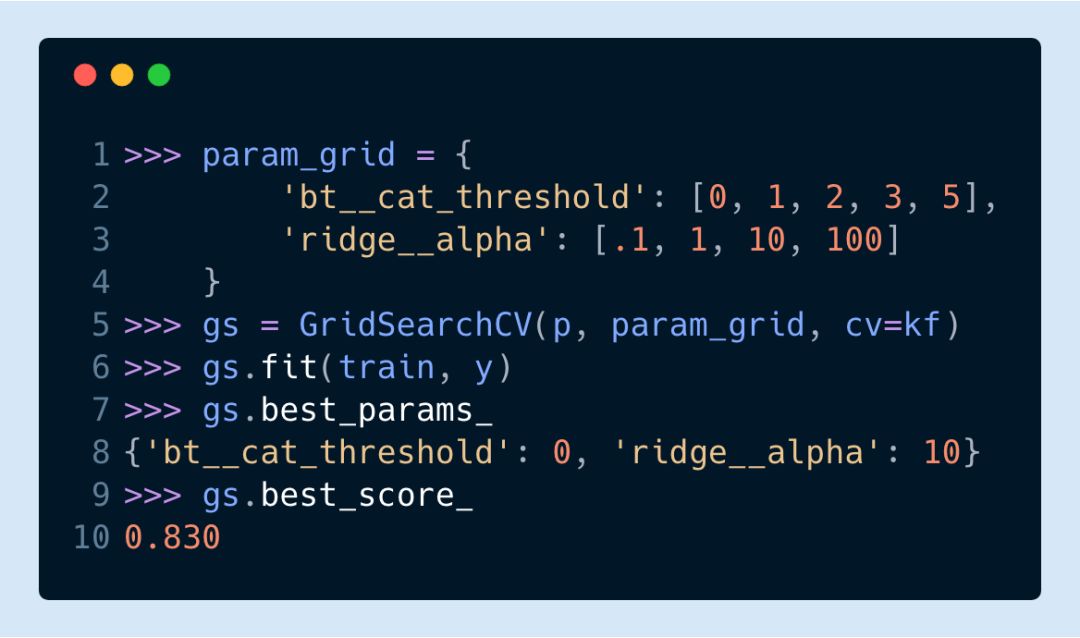
▌基于新的 KBinsDiscretizer 對(duì)數(shù)值列作二進(jìn)制轉(zhuǎn)換并編碼
存在多個(gè)列都含有關(guān)于年份的信息,所以比起把它們當(dāng)作特征列,將這些列的值進(jìn)行二進(jìn)制轉(zhuǎn)換更為合理。Scikit-Learn 開(kāi)發(fā)了新的估計(jì)器KBinsDiscretizer來(lái)執(zhí)行這一操作。它不僅將這些值轉(zhuǎn)換為二進(jìn)制碼,還會(huì)對(duì)其進(jìn)行編碼。在此之前,你可以通過(guò) Pandas 的cut和qcut函數(shù)手動(dòng)完成這個(gè)過(guò)程。
讓我們看看它是如何工作的,以YearBuilt列為例。
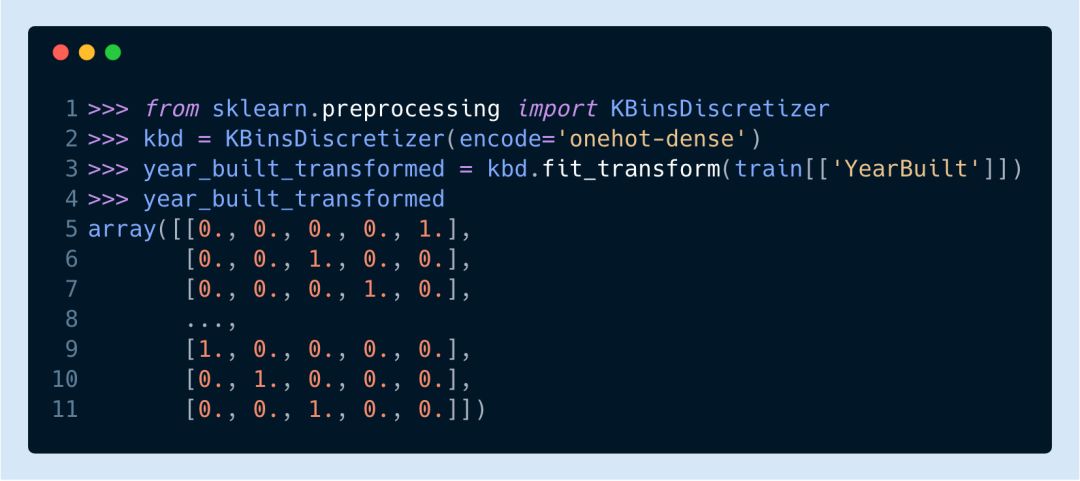
每個(gè)二進(jìn)制結(jié)果包含的位數(shù)相等,我們將每一列相加來(lái)驗(yàn)證這一點(diǎn)。

▌?dòng)?ColumnTransformer 分別處理所有年份列
我們可以采用ColumnTransformer對(duì)列的其它子集進(jìn)行單獨(dú)處理。下面一段代碼是我們之前轉(zhuǎn)換操作的后續(xù)步驟。我們也可以去掉Id這一列,它的作用只是用來(lái)標(biāo)記每一行。
接下來(lái)進(jìn)行交叉驗(yàn)證,計(jì)算得分,然后我們發(fā)現(xiàn)這一系列操作并沒(méi)有使結(jié)果提升。
改變每一列的二進(jìn)制串?dāng)?shù)目也許會(huì)優(yōu)化我們的結(jié)果。但無(wú)論如何,KBinsDiscretizer還是使二進(jìn)制化數(shù)值變量這一過(guò)程變得更加容易了。
Scikit-Learn 0.20 更多的有點(diǎn)
關(guān)于新版本還有許多本文未提到的新特性。查看文檔中的 What’s New 部分可以得到更多信息。
What’s New:
http://scikit-learn.org/dev/whats_new.html#version-0-20-0
總結(jié)
本文介紹了一種新型工作流,它有助于那些依賴于 Pandas 做數(shù)據(jù)分析與準(zhǔn)備工作的 Scikit-Learn 用戶。
這是一個(gè)更加流暢且多功能的過(guò)程,包括納入 Pandas 數(shù)據(jù)框,并將其進(jìn)行轉(zhuǎn)換,以便于后續(xù)的機(jī)器學(xué)習(xí),這一系列操作都由全新且優(yōu)化的估計(jì)器ColumnTransformer、SimpleImpute,、OneHotEncoder和KBinsDiscretizer來(lái)完成。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8424瀏覽量
132763 -
數(shù)據(jù)科學(xué)
+關(guān)注
關(guān)注
0文章
165瀏覽量
10078
原文標(biāo)題:Scikit-Learn大變化:合并Pandas
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Python機(jī)器學(xué)習(xí)庫(kù)談Scikit-learn技術(shù)
在PyODPS DataFrame自定義函數(shù)中使用pandas、scipy和scikit-learn
6個(gè)令人興奮的醫(yī)療保健物聯(lián)網(wǎng)案例
6個(gè)令人興奮的醫(yī)療保健物聯(lián)網(wǎng)案例
高級(jí)駕駛輔助系統(tǒng)是一個(gè)令人興奮的市場(chǎng)空間
通用Python機(jī)器學(xué)習(xí)庫(kù)scikit-learn
如何在移動(dòng)和嵌入式設(shè)備上部署機(jī)器學(xué)習(xí)模型
基于Python的scikit-learn編程實(shí)例
詳細(xì)解析scikit-learn進(jìn)行文本分類(lèi)

用英特爾DAAL性能庫(kù)加速SCIKIT學(xué)習(xí)
高性能Python代碼工具的介紹
scikit-learn K近鄰法類(lèi)庫(kù)使用的經(jīng)驗(yàn)總結(jié)
基于Python的scikit-learn包實(shí)現(xiàn)機(jī)器學(xué)習(xí)
RAPIDS cuML中的輸入輸出可配置性






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論