 CPU緩存的作用 CPU有多層緩存有何用意
CPU緩存的作用 CPU有多層緩存有何用意
這是來自于‘jlforrest’的一位讀者的提問,我認為值得更詳細的解答。以下是他的問題:
● 我理解緩存,但不明白為什么需要多層緩存而不是直接用一層大的。換句話說,如果一級緩存是32K,二級256K,三級2M,為什么不用32K+256k+2M的一級緩存?
簡短的回答是不同的緩存級別適用于不同的目的和限制,在設計上完全不同。經驗上,隨著緩存級別的增加,緩存變得更大,更慢,密度更高,每單位存儲消耗的電能更少,能處理更多的任務。
CPU的緩存有什么作用?
高速緩存是處理核心(包括CPU與GPU)或者外部儲存設備與主內存區間的一個緩沖儲存區,所以稱為緩存
在CPU,GPU等處理核心上,核心計算的臨時中間數據和大量需求的數據都優先儲存在緩存里,舉個例子:CPU計算一個1+1+1的值時,第一次計算前兩個數的和的結果2就儲存在CPU緩存里,再把結果拿來進行第二次計算,當然,現在的處理器算這個數據不用這么做,只是面對大量數據計算的時候需要這么做
在更大量的計算里,處理器會按數據的優先級從低到高分別儲存在一級,二級,三級緩存中,再沒有空間就會放進內存中,處理器讀取數據也是從一級緩存開始,直到內存中,如果內存還沒有數據就去硬盤光盤等外部儲存設備找,一級緩存速度最快,二級,三級次之
在外部儲存設備中,比如硬盤和光驅的緩存主要是提高傳輸速率,增加硬件壽命,你可以從硬盤一個分區復制一堆小文件到另一個分區,你可以發現,復制相同容量的文件速度是大文件快于小文件,因為每個小文件都要進行文件的建立,數據寫入與結束寫入等過程會耗費很多時間
在處理器或者內存向硬盤或者光驅(刻錄機)寫入的數據都是小文件或者數據而且并不連續,他們都先放在硬盤緩存里,到整個文件結束或者到緩存區容量極限時再一次性寫入硬盤,這樣可以減少硬盤的讀寫次數,并且以此寫入的速度更快~
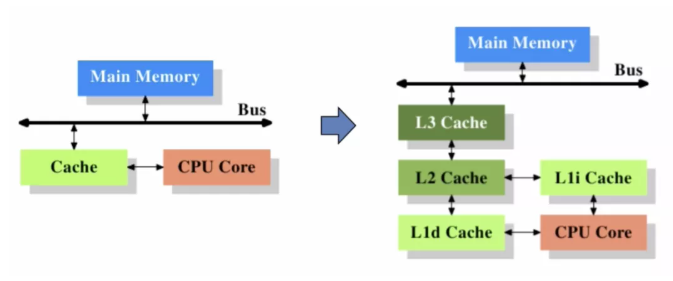
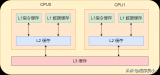
cpu緩存現在都分兩個級別,一及緩存稱L1 cache,二級緩存稱為L2 cache.
當然對于不同cpu,兩及緩存的作用是不同的。但總體來說,緩存是儲存cpu急需處理的數據的地方,當cpu要處理東西的時候,緩存中就開始儲存這些數據,由于緩存速度非常之高,所以,cpu讀取這些數據的速度就相當快。
由于緩存容量相當小,但是當緩存中的數據處理完了又沒有來得及重新添滿的時候,或者是緩存中的數據不是cpu馬上要處理的數據的時候,cpu就只有跳過緩存,直接村內存讀取,內存的速度要相對慢得多,所以這個時候cpu整體的速度就下降了。
當然,AMD和intel在緩存上的結構完全不同,這個造成了為什么intel的主流處理器的L2 cache緩存在2-4Mb,而AMD的L2 cache只有256kb-512kb.這個我們就要說到他們L1 cache的區別了。
intel的L1中不儲存cpu要處理的實際數據,他儲存的都是L2中數據的目錄,也就是intel的cpu要處理數據的時候先要訪問L1,為的是了解他要儲存的實際數據在L2中具體的位置。這個大大減少了cpu尋找L2數據的時間。比喻起來,intel的L2是一個倉庫,L1關于就是這個倉庫中儲存東西具體位置的目錄。
AMD完全不同,L1中就儲存實際數據,L2也儲存實際數據,當L1中的數據用完了的時候,或者L1不能裝的過大的數據的時候,cpu就直接處理L2中的數據。比喻起來,AMD的L1是個小倉庫,L2是個大倉庫。
然后是為什么他們對L2需求不同。
AMD的很好理解,他cpu處理數據的時候是有續處理的,先處理L1,處理完了再處理L2,數據一個接一個。
intel采取的是則是亂處理方式,cpu不會衣順序處理數據,而是隨即挑選數據來處理,當他隨便挑選的數據在L2中時,他就讀取L1了解數據在L2的位置,然后處理這個數據,但是當數據不在L2中時,就讀取內存。
這個造就了他們L2大小不同,intel的處理方式像是一個人隨機的在扔飛標,飛標落在標盤每個地方的幾率是相同的,標盤內的紅心就是L2的數據,標盤的其他地方是內存。前面說了,L2中數據是高速的,只有處理L2的,才能更快,否則要慢很多。所以,一個隨機扔飛標的人為了讓飛標落在紅心的幾率更大,最好的辦法就是加大紅心的面積,也就是L2.因此為了提高cpu的速度,intel需要很大的紅心,也就是L2.
AMD則不同,他是一個接一個處理的,不是隨機的扔飛標,他要考慮的只是L1和L2中單個數據的大小,因為cpu要處理的數據幾乎都在0-2Mb之間,0-128kb的占了50%,128-256kb占了25%,256-512的占了24%,大于512kb的只占了1%.
因此,512kb就能滿足cpu幾乎所有的需求了,只有處理那些1%的大于512kb的數據的時候AMD才會訪問內存。因此AMD需求很小的L2.
為了把這個問題講得更直觀,我打算用一個有點奇怪但很精巧的類比:
緩存的故事
假設你是一位六十年代的白領,在巨大的辦公樓里工作,沒有電腦,你需要閱讀大量的文件并且交叉檢索這些文檔。
你有一個辦公桌(L1 緩存)。桌上的文件是你正在手頭處理的資料,還有一些是你最近看過的或者你準備閱讀的。通常我們需要閱讀文件的每一頁(對應于存儲單元的一個字節),但除非它們在辦公桌上,文件都是作為一個整體。即只想看某一頁的內容,我們也必須把整份文件抓過來。
辦公室里還有文件柜(L2 緩存)。這些文件柜里存放的是你最近處理過,但目前沒有在使用的文件。辦公桌上的文件在用完后,通常也會放回文件柜。從文件柜里拿文件就不是順手拈來了——你需要走過去,打開相應的抽屜,還要查目錄卡片,才能找到想要的文件——不過這也還比較快了。
有些時候,其他人也需要查看你的文件柜里的文件。勤雜工會推著一輛推車(環路公共汽車)在各個辦公室轉。如果有人在自己的文件柜沒有找到相應的資料,他會寫一個紙條交給勤雜工。為簡化起見,假設這位勤雜工知道所有的東西放哪兒。所以當他來到你的辦公室的時候,他會檢查你的文件柜里是否有其他人需要的文件,如果有,就把這些文件抽出來放到車上。當他轉到別的辦公室,就會把找到的文件放在文件柜里,并留下收條。
有時候,這些文件并不在文件柜里,而是在辦公桌上。那就不可以直接拿了,需要征詢主人的意見,如果不行,大家就要商量如何協調。有大量冗長的詳盡的合作指引來處理這類情況(至少要一起開會)。
文件柜經常會滿,這時就不能放新的文件,需要先騰地方,把一些很久都沒用到的文件拿出來。勤雜工會把這些文件放到地下室里(L3 緩存)。地下室里的文件被密集地堆放到紙箱里或者文件架上,交給文檔管理員處理,其他人都不會下去,也不會了解文檔的存放細節。
當勤雜工來到地下室,會把一堆不需要的文件放到‘in’框里,同時他也會留下一堆紙條,寫著在樓上文件柜里找不到的文件名。文檔管理員會拿著這些紙條,找到對應的文件,把它們放到‘out’ 框里。下次勤雜工下來的時候,就可以把‘out’框里的文件拿走,交給需要的人。
現在的問題是,文件還是太多,地下室也放不下,而且辦公大樓的租金都很貴,所以通常公司都會在離市區較遠的地方租一個倉庫來存放歸檔文件(對應于DRAM內存)。文檔管理員會記錄哪些文件放在地下室,哪些文件放在倉庫。這樣,當需要拿文件時,管理員就知道哪些是能在地下室找到,哪些要到倉庫里拿。每天有一兩次,會有一輛貨車開到倉庫去拿需要的文件,同時把一些地下室的舊文件運過去。
對勤雜工而言,他并不關心這些細節,這些都是文檔管理員在處理。他需要做的就是把紙條放到‘in’框里,從‘out’框里取出文件。
回到最初的問題
那么,這個類比的意義何在?簡短而言,一個具體的模型比模糊的概念更能清晰地闡明物流的意義。實際上,物流對設計芯片的意義和運作一個高效的辦公文件處理系統是一樣的。
最初的問題是‘為什么不用一個大的緩存,而是用幾層小的緩存?’。 也就是說,如果一個4核芯片配置32K一級緩存,256K二級緩存和2M三級緩存,為什么不能用一個3M的大緩存?
在類比里,類似于問與其給4個人每人分一個1.5米寬的辦公桌,為什么不給這4個人一個150米寬的大辦公桌?
關鍵在于,放辦公桌上的目的就是要能觸手可及。如果辦公桌太大,就沒有意義了。難道還需要走50米去拿文件? 對一級緩存也是同理,如果太大,存取速度會變慢,而且會消耗更多的電力。所以一級緩存既要足夠大到能起作用,又要小到能夠快速存取。
另外一點,一級緩存處理的存取類型和其他緩存不同。有L1的數據緩存,也有L1指令緩存。Intel的CPU還有另外的指令緩存,uOp緩存,既叫L1并發指令緩存也叫L0指令緩存。
L1數據緩存通常只處理1到8個字節的數據,但高層級的緩存并不處理單獨的字節。在我們的類比里,所有不辦公桌上的資料都是以文件為單位(對應于catch line)。 在內存中也一樣,高層級緩存通常是批發處理數據,以緩存行為單位(cache line)。
L1指令緩存和數據緩存完全不同,就內核而言,它是只讀的。(指令內存的寫入通常是用非直接的方式,先把指令放入高層的緩存,再載入一級指令緩存)。由于這個原因,指令緩存和數據緩存通常是分隔的。使用通用的L1緩存意味著把互相沖突的設計原則糅合在一起,妥協的結果就是任何一個目的都達不到。而且用通用的L1緩存處理指令和數據負載也會很大。
另外,作為程序員,我們通常不關心內存帶寬。例如,每個時鐘周期,i7的CPU的內核能從L1緩存中讀取16字節的指令,而且會不斷地循環讀取。如果是3GHZ,每個核可以讀50GB指令/秒。實際上,通常L1指令緩存的能力都足夠大,很少需要L2緩存參與處理。但如果是通用緩存,就需要預估指令和數據的高并發情況。(想象一下在L1緩存中用memcopy拷貝幾K數據的情況)
順便提一句,如果都在L1緩存,CPU能在一個時鐘周期完成許多存取操作。‘Haswell’或者之后的3GHZ的i7內核可以處理超過300GB的指令和數據, 如果搭配合理的話。這樣的處理能力綽綽有余,但你仍然需要考慮數據和指令同時出現峰值的情況。
L1緩存在設計上就是越快越好,以應對峰值情況。只有L1緩存處理不了,才會轉給更高層的緩存,但速度會降低。因為高層緩存更關心電力效率和存儲密度。
第三點,共享。在上面的比喻中,獨立辦公桌,亦或L1緩存是私有的,如果在你的辦公桌上,你只管拿就好了,不需要詢問其他人。
這很關鍵。如果4個人共享一個大辦公桌,你就不能隨便拿文件,因為另外三個人可能正在使用。(即使他們只是在閱讀其他文件時順便參考一下你想使用的文件)。任何時候,你想要拿什么東西,你需要先叫一聲,‘有人在用嗎?’如果別人在你前面,你就必須等待。或者需要一個排隊系統,當存在資源沖突的時候,每個人需要拿張票排隊等候,或者其它的什么機制,具體實現細節并不重要,但是所有的事情你都需要和其他人協調。
對多核共享緩存的情況也是這樣。你不能在不通知別人的情況下隨意動那些數據,所有對共享緩存的操作都必須協調進行。
這就是為什么我們要使用私有的L1緩存。L1緩存就是你的辦公桌,你可以隨便使用桌上的文件。L2緩存處理大部分的協同操作。大部分時間,工作者(CPU內核)坐在辦公桌前,勤雜工會走過來,把需求列表拿走,同時把之前你想找的文件放倒文件柜里。整個過程不會打斷你的工作(CPU)。
僅僅當你和勤雜工都需要拿文件柜里的同一份文件,或者別人想用你辦公桌上的文件,這時就需要停下手頭工作,進行交談。
簡單而言,L1緩存的工作就是優先為CPU內核服務。因為是私有的,所以基本不需要協調工作。L2緩存也是私有的,但是它的工作重心還包括在不打擾內核工作的情況下,處理大量的緩存間的數據通信。
L3緩存是共享資源,需要全局協調。在上面的類比中,工作者只有從勤雜工的推車里拿到文件,這就是一個阻塞點。我們只能希望L1和L2緩存足夠大以便這類阻塞點不會成為性能瓶頸。
附加說明
本篇文章涵蓋了當前臺式機(筆記本)CPU的緩存架構:分開的L1/L1 D 緩存,每核統一的L2緩存,共享的L3緩存。
不是每個系統都象這樣。一些系統并不區分指令緩存和數據緩存;另外一些則把指令和數據在所有的緩存級全部分開。很多L2緩存是多核共享的,L2緩存就象是連接多個內核的公共汽車。還有一些系統有L3和L4緩存。我也沒有提到使用多CPU套接字的系統。
我提到環路公共汽車是因為這是一個很好的類比。環路公共汽車很常見。有些時候,環路汽車是個麻煩(尤其是只需要把兩三個街區連起來);有時候,環路公共汽車需要和交叉系統連接起來(就象在辦公室,每個樓層用推車,不同樓層則用電梯)。
作為軟件工程師,我們自然而然地會假設模塊A和模塊B可以魔術般地連接,數據則可隨意地從一端流向另一端。內存的實際工作機制其實非常復雜,但抽象出來呈現給程序員的只是一組大平面的字節排列。
硬件并不象這樣工作。各個部件之間并不能魔法般地自動連接。模塊A和模塊B并非抽象概念,而是具體的物理設備,實際上可以看作是非常小的機器,在硅片上占有實際的物理空間。芯片都有平面圖,是真正的2D地圖。如果你想連接A和B,就需要一條實際的導線來連接。 導線也占空間,而且需要消耗電力(越遠消耗越多)。用一大捆線連接A和B意味著物理上這一塊區域會阻礙其他區域的連接。(當然,芯片可以使用多層連接,如果你有興趣,可以搜索‘routing congestion’)。 在芯片里移動數據實際上是一個物流問題,并且超級復雜。
所以盡管辦公室的故事只是半開玩笑的類比,‘誰需要和誰談’、‘這個系統的幾何構造如何——是有意義的布局嗎?’這些問題其實對系統設計和硬件相關并有巨大的影響。 利用空間的隱喻來概念化實際情況是十分有效的。
-
cpu
+關注
關注
68文章
10872瀏覽量
211993 -
緩存
+關注
關注
1文章
240瀏覽量
26693
發布評論請先 登錄
相關推薦
什么是CPU一級緩存/二級緩存?
談一談CPU緩存和緩存一致性
CPU緩存是什么意思_CPU緩存有什么作用
緩存如何工作,如何設計CPU緩存
CPU緩存的作用及原理有哪些
CPU緩存那些事兒





 工商網監
工商網監
評論