 自制Word2Vec圖書推薦系統,幫你找到最想看的書!
自制Word2Vec圖書推薦系統,幫你找到最想看的書!
最近有開發者自制了一套圖書推薦系統,使用Word2Vec算法將書目表示為向量,可以同時獲得幾種書籍的推薦結果,并獲得書籍的TSNE圖及相似度最高的推薦。圖書數據來自GoodReads上的評價最高的前10000本書。開發者表示,采用較小的batchsize和長度可變的窗口可提升推薦相似度。
近日,有開發人員自制了一套圖書推薦系統,使用Word2Vec算法將書目表示為向量,可以同時獲得幾種書籍的推薦,并獲得書籍的TSNE圖以及相似度最高的推薦信息。訓練數據來自GoodReads上的評價最高的前10000本書。
作者將這一系統在Reddit論壇上進行了算法介紹和推薦效果圖分享,引發廣泛討論。我們不妨來看看這個自制薦書系統是怎么做的。
以下是作者自己給出的系統展示和介紹,最后是技術實現環節的相關討論。
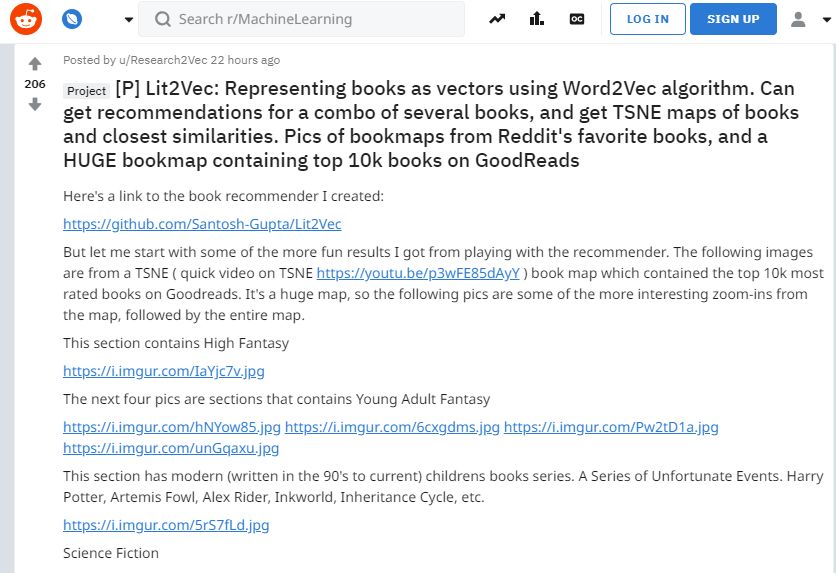
下面的圖片來自兩個2D TSNE生成的圖書嵌入圖。第一部分是數據中最常出現的3000本書的TNSE(已經過10000本書的數據訓練),第二部分是全部10000本書的TSNE。
我做了兩個TSNE圖,因為隨著書籍書目的增加,推薦的準確度趨于下降,所以我想查看最常出現的書籍的分布圖,然后再處理其余的書。
首先最常出現的3000本書的TSNE圖,先給出幾個局部放大圖,最后放上全圖。
下圖為作于最近30-40年間的奇幻/古典奇幻類書

中間的部分大部分是漫畫書,周圍是一些科學類書籍

宇宙科幻類:
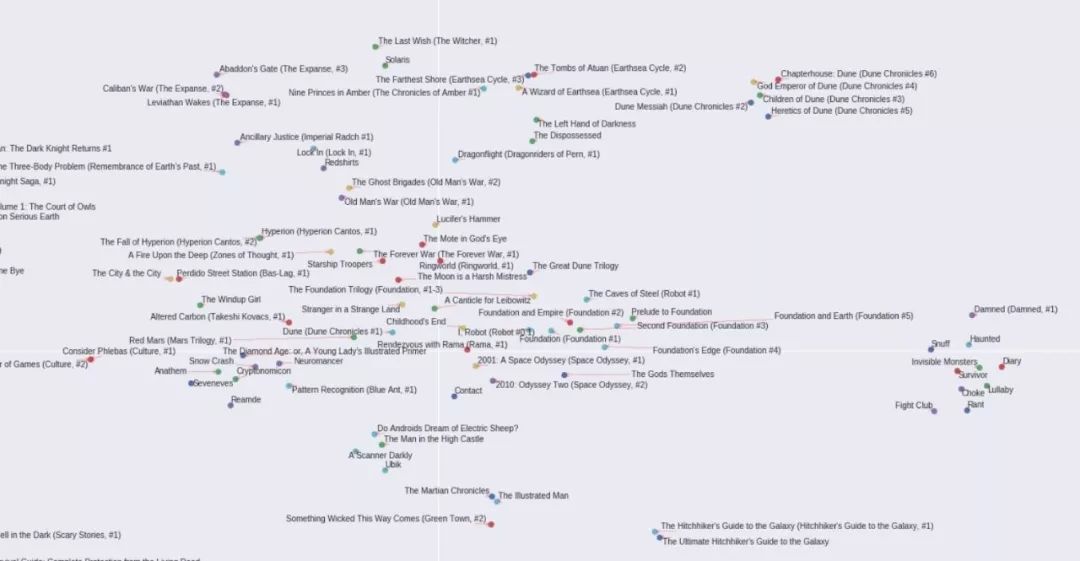
喜劇類(主要是電視劇)

全圖

然后是全部10000本書的TSNE圖,同樣先給出幾個局部圖,最后是全圖。
歷史類書籍。圖左半部為美國史,右半部為世界通史

宇宙史和起源理論

兒童經典書目

食品科學和新聞類

Word2Vec薦書系統的技術實現
下面是一些技術上的實現要點,對機器學習感興趣的小伙伴們可以關注一下。
1、使用較小的batch size
訓練中使用batch size較小(32和64)對于確保所有書籍向量的穩健性非常重要。在更高的batch size(128、256和512)下,大多數向量具有相當的相似性,但似乎總是有一些書的向量不具備相似性。
以《哈利·波特》2-7部的推薦結果為例,如果直接查看數據,很容易知道與這些書相似度最高的書應該是該系列中的其他《哈利·波特》書,但最初推薦模型給出的相似圖書結果并非如此。但是,在把batch size設置為64后,推薦結果的相似度很快得到明顯改善。
由于平均窗口大小為112,并在20到200之間變化(取決于用戶閱讀的書籍數量),因此像《哈利·波特》這樣的系列叢書中的一些書,很可能會與其他書籍匹配為相似了。
假設某系列叢書中共有7本書,并且用戶對所有7本書都進行了評分,該用戶還評價了112本其他書,那么,其中一本《哈利·波特》書與另一本《哈利·波特》在該用戶的標簽下實現配對的概率是6/112。
在這種情況下,由于word2vec試圖一次性優化多個嵌入,因此對于窗口大小很小且恒定的情況,更高的batch size會比word2vec算法的應用對結果優化造成更加明顯的阻礙。
2、Softmax嵌入向量算術
到目前為止,上面的所有矢量算術示例都是我在書籍輸入嵌入上執行加法和/或減法,然后針對softmax嵌入對結果矢量執行相似性結果的情況。比結果向量與輸入嵌入進行比較要穩健得多。
3、可變長度窗口(VLW)
最初的Word2Vec Cbow算法使用固定的窗口大小的單詞用作特定目標的輸入。比如,如果窗口大小是目標詞左側和右側的2個單詞,那么在這句“The cat in the hat”中,如果目標詞(標簽)是“in”,那么單詞'The ','cat','the'和'hat'將各自向量進行平均,并將得到的結果向量作為輸入。
而在這個薦書系統中,窗口大小不可能是固定的。對于特定數據點(輸入),由用戶輸入的所有對全部書籍的評價都可能作為潛在的輸入,而且每個用戶瀏覽過的書籍數量彼此存在很大差異,因此窗口大小不可能恒定。
盡管窗口大小不是恒定的,但是平均輸入向量的數量是保持不變的。所有提供的數據都使用兩個平均向量作為輸入,這樣向量的算術屬性的穩健性是最高的。改變輸入平均向量的數量,在相似性推薦屬性方面并沒有表現出明顯優勢。
-
算法
+關注
關注
23文章
4610瀏覽量
92859 -
機器學習
+關注
關注
66文章
8414瀏覽量
132607
原文標題:【Reddit今日最火】Lit2Vec圖書推薦系統,自動推薦適合你的AI好書!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
二維碼掃描頭嵌入在圖書自助管理設備中的應用案例

如何保障圖書館用電安全?——安科瑞 丁佳雯

智慧圖書館能耗監測優化管理系統方案
聚徽-什么是智能圖書館
nlp自然語言處理模型有哪些
雷拓科技云廣播助力江西省蘆溪縣新圖書館打造沉浸式觀展體驗!
iPad版微軟Word新增頁面邊框功能,提升文檔美觀度
名單公布!【書籍評測活動NO.32】硬核科普書《計算》,豆瓣評分9.8,榮膺圖書界至高獎項
如果通過物聯網技術提升學校圖書館管理水平
RFID智能書架:圖書館智能化管理的新趨勢
AURIX Development Studio支持在線調試自制的最小系統嗎?
上海交通大學徐匯校區包兆龍圖書館修繕工程電氣火災監控系統 Acrelsale1





 工商網監
工商網監
評論