

基于圖像信息對目標進行三維空間定位具有十分重要的作用。例如,在機器人操作中,抓握和運動規劃等任務就需要對物體的6D姿態(3D位置和3D方向)信息進行準確的估計;在虛擬現實應用中,人與物體之間的友好流暢的虛擬交互需要對目標進行準確的6D姿態估計。
雖然最新的技術已經在使用深度相機進行物體姿態估計,但這種相機在幀速率、視場、分辨率和深度范圍等方面還存在相當大的局限性,一些小的、薄的、透明的或快速移動的物體檢測起來還非常困難。目前,基于RGB的6D目標姿態估計問題仍然具有挑戰,因為圖像中目標的表觀會受到一系列因素的影響,如光照、姿態變化、遮擋等。此外,魯棒的6D姿態估計方法還需要能處理有紋理和無紋理的目標。
傳統方法往往通過將2D圖像中提取的局部特征與待檢測目標3D模型中的特征相匹配來求解6D姿態估計問題,也就是基于2D-3D對應關系求解PnP問題。但是,這種方法對局部特征依賴性太強,不能很好地處理無紋理目標。為了處理無紋理目標,目前的文獻中有兩類方法:一類是,學習估計輸入圖像中的目標關鍵點或像素的3D模型坐標;還有一類是,通過離散化姿態空間將6D姿態估計問題轉化為姿態分類問題,或轉化為姿態回歸問題。
這些方法雖然能夠處理無紋理目標,但是精度不夠高。為了提高精度,往往還需要進一步的姿態優化:給定初始姿態估計,對合成RGB圖像進行渲染來和目標輸入圖像進行匹配,然后再計算出新的更準的姿態估計。現有的姿態優化方法通常使用手工制作的圖像特征或匹配得分函數。
在本文工作中,作者提出了DeepIM——一種基于深度神經網絡的迭代6D姿態匹配的新方法。給定測試圖像中目標的初始6D姿態估計,DeepIM能夠給出相對SE(3)變換符合目標渲染視圖與觀測圖像之間的匹配關系。提高精度后的姿態估計迭代地對目標重新渲染,使得網絡的兩個輸入圖像會變得越來越相似,從而網絡能夠輸出越來越精確的姿勢估計。上圖展示了作者提出網絡用于姿態優化的迭代匹配過程。
這項工作主要有以下貢獻:
首先,將深度網絡引入到基于圖像的迭代姿態優化問題,而無需任何手工制作的圖像特征,其能夠自動學習內部優化機制;
其次,提出了一種旋轉和平移解耦的SE(3)變換表示方法,能夠實現精確的姿態估計,并且能使提出的方法適用于目標不在訓練集時的姿態估計問題。
最后,作者在LINEMOD和Occlusion數據集上進行了大量實驗,以評估DeepIM的準確性和各種性能。
兩個數據集上的實驗結果表明,作者提出的方法都比當前最先進的基于RGB的方法性能提高了很多。此外,初步的實驗表明,DeepIM還能夠在對一些訓練集中未出現的物體的姿態進行準確估計。
下面讓我們看看一些算法流程的細節。如上圖所示,作者為了獲得足夠的信息進行姿態匹配,對觀測圖像進行放大,并在輸入網絡前進行渲染。要注意的是,在每次迭代過程中,都會根據上一次得到的姿態估計來重新渲染,這樣才能夠通過迭代來增加姿態估計的準確度。DeepIM的網絡結構圖如下圖所示,輸入觀測圖像、渲染圖像以及對應的掩膜。使用FlowNetSimple網絡第11個卷積層輸出的特征圖作為輸入,然后連接兩個全連接層FC256,最后旋轉和平移的估計分別用兩個全連接層FC3和FC4作為輸入。
通常目標從初始位置到新位置的旋轉與平移變換關系如上顯示。

一般來說旋轉變換會影響最后的平移變換,即兩者是耦合在一起的。如果將旋轉中心從相機坐標系的原點轉移到目標中心,就能解耦旋轉和平移。但這樣就需要能夠識別每個目標并單獨存儲對應的坐標系,這會使得訓練變得復雜且不能對未知目標進行姿態匹配。
在本文的工作中,作者讓坐標軸平行于當前相機坐標軸,這樣可以算得相對旋轉,后續實驗證明這樣效果更好。剩下的還要解決相對平移估計問題,一般的方法是直接在三維空間中計算原位置與新位置的xyz距離,但是這種方式既不利于網絡訓練,也不利于處理大小不一、表觀相似的目標或未經訓練的新目標。
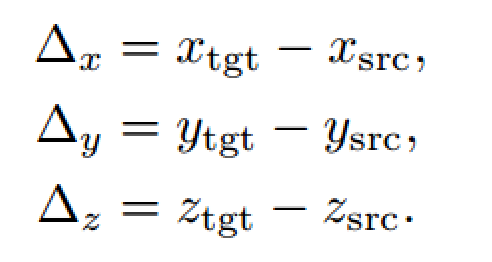
本文作者采用在二維圖像空間中進行回歸估計平移變換,vx和vy分別是圖像水平方向和垂直方向上像素移動的距離,vz表示目標尺度變化。其中,fx和fy是相機焦距,由于是常數,在實際訓練中作者將其設為1。
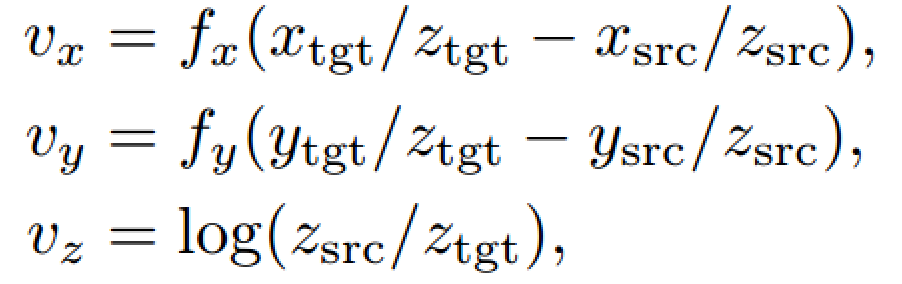
這樣一來,旋轉和平移解耦了,這種表示方法不需要目標的任何先驗知識,并且能處理一些特殊情況,比如兩個外觀相似的物體,唯一的區別就是大小不一樣。
關于模型訓練的損失函數,通常直接的方法是將旋轉和平移分開計算,比如用角度距離表示旋轉誤差,L1距離表示平移誤差,但這種分離的方法很容易讓旋轉和平移兩種損失在訓練時失衡。本文作者提出了一種同時計算旋轉和平移的Point Matching Loss函數,來表達姿態真值和估計值之間的損失。其中,xj表示目標模型上的三維點,n是總共用來計算損失函數的點個數,本文中n=3000。
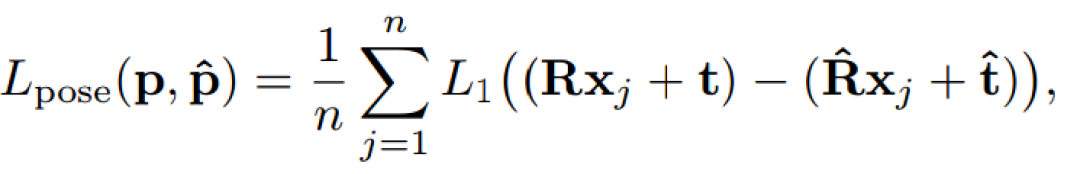
最后總的損失函數由L=αLpose +βLflow+γLmask組成,其中(α,β,γ)分別為(0.1,0.25,0.03)
實驗部分,作者主要使用了LINEMOD和OCCLUSION數據集。如下表顯示,在LINEMOD數據集上作者分別用PoseCNN和Faster R-CNN初始化DeepIM網絡,發現即便兩個網絡性能差異很大,但是經過DeepIM之后仍能得到差不多的結果。
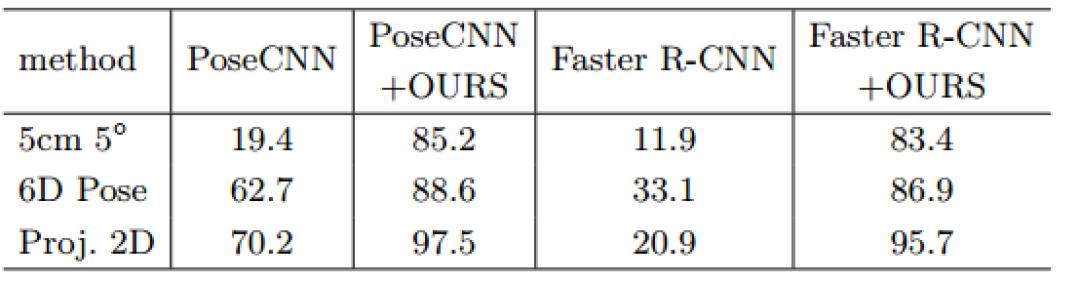
LINEMOD數據集上的方法對比結果如下表顯示,作者提出的方法是最好的。
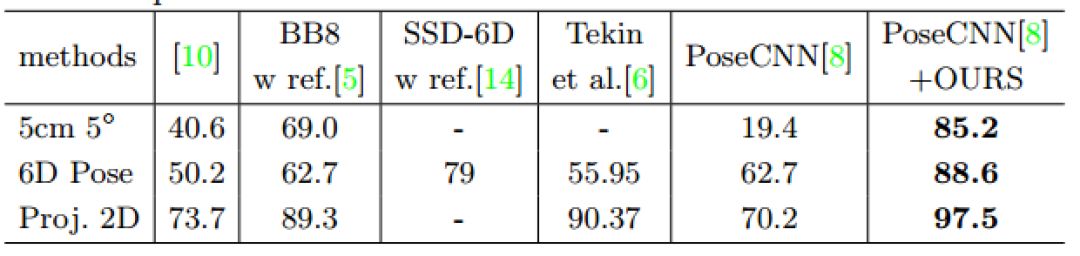
在目標有遮擋的數據集上的實驗,本文提出的方法效果也相當不錯哦。
除此之外,本文方法在ModelNet數據集上的表現也相當驚艷,要注意的是,這些物體都不曾出現在訓練集中哦。
利用這種方法實現6D位姿估計是十分有效的,希望能為小伙伴們的研究應用帶來啟發和幫助~
-
神經網絡
+關注
關注
42文章
4803瀏覽量
102581 -
圖像
+關注
關注
2文章
1092瀏覽量
40974 -
函數
+關注
關注
3文章
4366瀏覽量
64025
原文標題:DeepIM:基于深度網絡的6D位姿迭代新方法
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于LabVIEW8.2提取ECG特征點的新方法
人工神經網絡實現方法有哪些?
深度神經網絡是什么
如何構建神經網絡?
傳感器故障檢測的Powell神經網絡方法
一種改進的基于卷積神經網絡的行人檢測方法
DENSER是一種用進化算法自動設計人工神經網絡(ANNs)的新方法








 工商網監
工商網監

評論