


數據科學家James Le以語言建模為背景,介紹了RNN的概念、變體、應用。
介紹
我大三有一學期去丹麥的哥本哈根交流。我之前沒去過歐洲,去丹麥交流,讓我有機會浸入新文化,遇到新人群,去新地方旅行,以及最重要的,接觸新語言。我為此極度興奮。盡管英語不是我的母語(我的母語是越南語),但我很小的時候就開始學說英語了,它已經成為我的第二本能。而丹麥語則極為復雜,句法結構大不相同,語法也很不一樣。我在出發前通過多鄰國應用學了一點丹麥語;不過,我只掌握了一些簡單的短語,像是你好(Hej)和早上好(God Morgen)。
到了丹麥之后,我需要去便利店買吃的。但是那里的標簽都是丹麥文,我沒法分辨。我花了大概半小時都沒能分清哪個是全麥面包,哪個是白面包。這時我突然想起不久前我在手機上安裝了谷歌翻譯應用。我拿出手機,打開應用,將相機對準標簽……哇,丹麥單詞立刻翻譯成了英文。我發現谷歌翻譯可以翻譯任何相機攝入的單詞,不管是路牌,還是飯館菜單,甚至手寫數字。不用說了,在我交流學習期間,這個應用為我節省了大量時間。
谷歌翻譯是谷歌的自然語言處理研究組開發的產品。這個小組專注于大規模應用的跨語言、跨領域算法。他們的工作包括傳統的NLP任務,以及專門系統的通用語法和語義算法。
從更高的層面來看,NLP位于計算機科學、人工智能、語言學的交匯之處。NLP的目標是處理或“理解”自然語言,以便執行有用的任務,例如情緒分析、語言翻譯、問題解答。完全理解和表示語言的含義是一項非常艱巨的目標;因此人們估計,完美理解自然語言需要AI完備系統。NLP的第一步是語言建模。
語言建模
語言建模的任務是預測下一個出現的單詞是什么。例如,給定句子“I am writing a ……”(我正在寫),下一個單詞可能是“letter”(信)、“sentence”(句子)、“blog post”(博客文章)……更形式化地說,給定單詞序列x1, x2, …, xt,語言模型計算下一個單詞xt+1的概率分布。
最基礎的語言模型是n元語法模型。n元語法是n個連續單詞。例如,給定句子“I am writing a ……”,那么相應的n元語法是:
單元語法:“I”, “am”, “writing”, “a”
二元語法:“I am”, “am writing”, “writing a”
三元語法:“I am writing”, “am writing a”
四元語法:“I am writing a”
n元語法語言建模的基本思路是收集關于不同的n元語法使用頻率的統計數據,并據此預測下一單詞。然而,n元語法語言建模存在稀疏問題,我們無法在語料庫中觀測到足夠的數據以精確建模語言(特別是當n增加時)。
神經概率語言模型的網絡架構概覽(來源:Synced)
不同于n元語法方法,我們可以嘗試基于窗口的神經語言模型,例如前饋神經概率語言模型和循環神經網絡語言模型。這一方法將單詞表示為向量(詞嵌入),將詞嵌入作為神經語言模型的輸入,從而解決了數據稀疏問題。參數在訓練過程中學習。詞嵌入通過神經語言模型得到,語義相近的單詞在嵌入向量空間中更靠近。此外,循環神經語言模型也能捕捉句子層面、語料庫層面、單詞內部的上下文信息。
循環神經網絡語言模型
RNN背后的想法是利用序列化信息。RNN一名中有循環(recurrent)這個單詞,這是因為RNN在序列中的每個元素上執行相同的任務,其輸出取決于之前的計算。理論上,RNN可以利用任意長度序列中的信息,但經驗告訴我們,RNN只限于回顧若干步。這一能力使得RNN可以解決識別連寫筆跡或語音之類的任務。
讓我們嘗試類比一下。假設你看了最近的《復仇者聯盟3:無限戰爭》(順便提一下,這是一部現象級電影)。其中有許多超級英雄,有多條故事線,缺乏漫威電影宇宙的先驗知識的觀眾可能感到迷惑。然而,如果你按順序看過之前的漫威系列(鋼鐵俠、雷神、美國隊長、銀河護衛隊),那你就有了上下文可以正確地將所有情節聯系起來。這意味著你記住你看過的東西以理解《無限戰爭》中的混沌。
無限戰爭(圖片來源:digitalspy.com)
類似地,RNN記得一切。其他神經網絡中,所有輸入都是彼此獨立的。但在RNN中,所有的輸入都彼此相關。比方說你需要預測給定句子的下一個單詞,所以之前單詞之間的關系有助于預測更好的輸出。換句話說,RNN在訓練自身時記住一切關系。
RNN通過簡單的循環記住從之前的輸入中學到的東西。該循環接受上一時刻的信息,并將它附加到當前時刻的輸入上。下圖顯示了基本的RNN結構。在某一具體時步t,Xt是網絡的輸入,ht是網絡的輸出。A是一個RNN單元,其中包含類似前饋網絡的神經網絡。
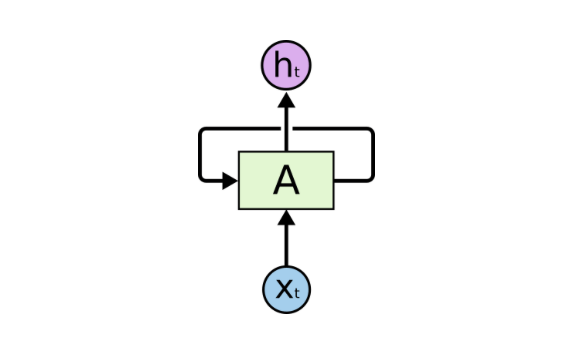
圖片來源:colah.github.io
這一循環結構讓神經網絡可以接受輸入序列。下面的展開圖有助于你更好地理解RNN:
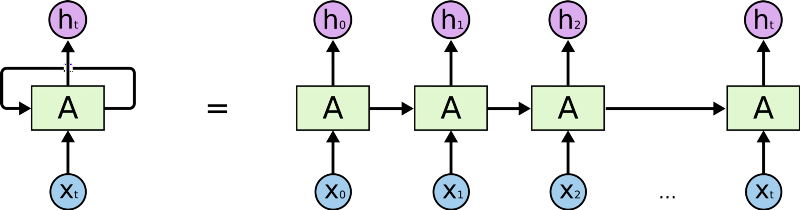
圖片來源:colah.github.io
首先,RNN接受輸入序列中的X0,接著輸出h0,h0和X1一起作為下一步的輸入。接著,下一步得到的h1和X2一起作為再下一步的輸入,以此類推。這樣,RNN在訓練時得以保留上下文的記憶。
如果你偏愛數學,許多RNN使用下面的等式定義隱藏單元的值:
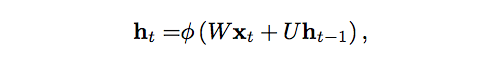
圖片來源:lingvo-masino
其中,ht是t時刻的隱藏狀態,?是激活函數(Tanh或Sigmoid),W是輸入到t時刻的隱藏層的權重矩陣,U是t-1時刻的隱藏層到t時刻的隱藏層的權重矩陣,ht-1是t時刻的隱藏狀態。
RNN在訓練階段通過反向傳播學習U和W。這些權重決定了之前時刻的隱藏狀態和當前輸入的重要性。基本上,它們決定了生成當前輸出時,隱藏狀態和當前輸入所起到的作用。激活函數?給RNN加上了非線性,從而簡化了進行反向傳播時的梯度計算。
RNN的劣勢
RNN不是完美的。它有一個重大缺陷,稱為梯度消失問題,阻止它取得高精確度。隨著上下文長度的增加,展開的RNN中的網絡層也增加了。因此,隨著網絡的加深,反向傳播中由后往前傳播的梯度變得越來越小。學習率變得很低,期望這樣的模型學習到語言的長期依賴不太現實。換句話說,RNN在記憶序列中很久之前出現的單詞上遇到了困難,只能基于最近的一些單詞做出預測。
圖片來源:anishsingh20
RNN的擴展
這些年來,研究人員研發了更復雜的RNN變體,以應對標準RNN模型的不足。讓我們簡短地總結以下其中最重要的一些變體:
雙向RNN不過是堆疊組合了2個RNN。雙向RNN的輸出基于2個RNN的隱藏狀態得出。背后的直覺是輸出可能不僅取決于序列中之前的元素,還取決于未來的元素。
長短時記憶網絡(LSTM)現在相當流行。LSTM繼承了標準RNN的架構,在隱藏狀態上做了改動。LSTM的記憶(稱為單元)接受之前的狀態和當前輸入作為輸入。在LSTM內部,這些單元決定哪些信息保留在記憶中,哪些信息從記憶移除。接著,LSTM組合之前狀態、當前記憶和輸入。這一過程有效解決了梯度消失問題。
門控循環單元網絡(GRU)擴展了LSTM,通過門控網絡生成信號以控制當前輸入和之前記憶如何工作以更新當前激活,以及當前網絡狀態。閥門自身的權重根據算法選擇更新。
神經圖靈機通過結合外部記憶資源擴展了標準RNN的能力,模型可以通過注意力過程與外部記憶資源交互。就像阿蘭·圖靈的圖靈機,有限狀態機和無限存儲紙帶。
使用RNN語言模型生成文本的有趣例子
好了,現在讓我們來看一些使用循環神經網絡生成文本的有趣例子:
Obama-RNN(機器生成的政治演說):這里作者使用RNN生成了模仿奧巴馬的政治演說。模型使用奧巴馬演講稿(4.3 MB / 730895單詞)作為輸入,生成了多個版本的演說,主題廣泛,包括就業、反恐戰爭、民主、中國……極其滑稽!
Harry Potter(AI撰寫的《哈利波特》):在《哈利波特》的前4部上訓練LSTM循環神經網絡,然后根據所學生成一個新章節。去看看吧。我打賭即使JK羅琳也會對此印象深刻的。
Seinfeld Scripts(計算機版本的《宋飛正傳》):使用第3季的劇本作為輸入,生成了關于主角的3頁劇本。生成的劇本風格奇特,提問浮夸,充斥各種術語——和《宋飛正傳》的風格相匹配。
RNN的真實世界應用
RNN的美妙之處在于應用的多樣性。我們使用RNN的時候,可以處理多種多樣的輸入和輸出。讓我們重新回顧下開頭提到的谷歌翻譯的例子。這是神經機器翻譯的一個例子,通過一個巨大的循環神經網絡建模語言翻譯。這類似語言建模,輸入是源語言的單詞序列,輸出是目標語言的單詞序列。
圖片來源:sdl.com
標準的神經機器翻譯是一個端到端的神經網絡,其中源語言的句子由一個RNN編碼(稱為編碼器),另一個RNN預測目標單詞(稱為解碼器)。RNN編碼器逐符號地讀取源語言的句子,并在最后的隱藏狀態中總結整個句子。RNN解碼器通過反向傳播學習這一總結,并返回翻譯好的版本。
機器翻譯方面的一些論文:
A Recursive Recurrent Neural Network for Statistical Machine Translation(用于統計機器翻譯的遞歸循環神經網絡,微軟亞研院和中科大聯合研究)
Sequence to Sequence Learning with Neural Networks(神經網絡的序列到序列學習,谷歌)
Joint Language and Translation Modeling with Recurrent Neural Networks(循環神經網絡的語言、翻譯聯合建模,微軟研究院)
除了之前討論的語言建模和機器翻譯,RNN在其他一些自然語言處理任務中也取得了巨大的成功:
1 情感分析一個簡單的例子是分類推特上的推文(積極、消極)。
情感分析方面的論文:
Benchmarking Multimodal Sentiment Analysis(多模態情感分析評測,新加坡NTU、印度NIT、英國斯特林大學聯合研究)
2 圖像說明
搭配卷積神經網絡,RNN可以用于為沒有標注的圖像生成描述的模型。給定需要文本描述的圖像,輸出是單詞組成的序列或句子。輸入的尺寸也許是固定的,但輸出長度是可變的。
關于圖像說明的論文:
Explain Images with Multimodal Recurrent Neural Networks(使用多模態循環神經網絡解釋圖像,百度研究院、UCLA聯合研究)
Long-Term Recurrent Convolutional Networks for Visual Recognition and Description(用于視覺識別和描述的長期循環卷積網絡,伯克利)
Show and Tell: A Neural Image Caption Generator(看圖說話:神經圖像說明生成器,谷歌)
Deep Visual-Semantic Alignments for Generating Image Descriptions(用于生成圖像說明的深度視覺-語義對齊,斯坦福)
Translating Videos to Natural Language Using Deep Recurrent Neural Networks(基于深度循環神經網絡翻譯視頻至自然語言,德州大學、麻省大學洛威爾分校、伯克利聯合研究)
YouTube自動生成的字幕;圖片來源:filmora.wondershare.com/vlogger
3 語音識別
比如SoundHound和Shazam這樣的聽音識曲應用。
語音識別方面的論文:
Sequence Transduction with Recurrent Neural Networks(基于循環神經網絡的序列轉換,多倫多大學)
Long Short-Term Memory Recurrent Neural Network Architectures for Large-Scale Acoustic Modeling(用于大規模聲學建模的長短期記憶循環網絡架構,谷歌)
Towards End-to-End Speech Recognition with Recurrent Neural Networks(通向端到端語音識別的循環神經網絡,DeepMind、多倫多大學聯合研究)
Shazam應用
結語
復習一下本文的關鍵點:
語言建模是一個預測下一個單詞的系統。它是一個可以幫助我們衡量我們在語言理解領域的進展的基準任務,同時也是其他自然語言處理系統(比如機器翻譯、文本總結、語音識別)的子部件。
循環神經網絡接受任意長度的序列化輸入,在每一步應用相同的權重,并且可以在每步生成輸出(可選)。總體上來說,RNN是一個構建語言模型的出色方法。
此外,RNN還可以用于句子分類、詞性標記、問題回答……
順便提一下,你看了今年的Google I/O大會嗎?谷歌基本上已經成了一家AI優先的公司。谷歌引入的出類拔萃的AI系統之一是Duplex,一個可以通過電話完成真實世界任務的系統。接收完成特定任務的指示(例如安排預約)后,Duplex可以和電話另一頭的人自然地對話。
Duplex的核心是基于TFX構建的RNN,在匿名化的電話交談數據語料庫上訓練,以達到高準確率。RNN利用了谷歌的自動語音識別技術的輸出、音頻的特征、談話的歷史、談話的參數等信息。而TFX的超參數優化進一步改善了模型。
很好,AI對話的未來已經取得了第一個重大突破。這一切都要感謝語言建模的發電廠,循環神經網絡。
-
循環神經網絡
+關注
關注
0文章
38瀏覽量
3121 -
rnn
+關注
關注
0文章
89瀏覽量
7125
原文標題:語言建模的發電廠——循環神經網絡
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
BP神經網絡與卷積神經網絡的比較
BP神經網絡的優缺點分析
什么是BP神經網絡的反向傳播算法
BP神經網絡與深度學習的關系
人工神經網絡的原理和多種神經網絡架構方法

卷積神經網絡與傳統神經網絡的比較
循環神經網絡的常見調參技巧
循環神經網絡的優化技巧
RNN模型與傳統神經網絡的區別
LSTM神經網絡的結構與工作機制
LSTM神經網絡與傳統RNN的區別
LSTM神經網絡的基本原理 如何實現LSTM神經網絡
Moku人工神經網絡101






 工商網監
工商網監

評論