 Github熱門:國內互聯網名企AI算法工程師筆試面經總結
Github熱門:國內互聯網名企AI算法工程師筆試面經總結
國慶第六天,也不忘記要充電。GitHub上有位id為imhuay的熱心人建立了一個關于國內知名互聯網企業筆試和面試經驗的資源庫,詳盡地總結百度騰訊頭條小米滴滴等名企網招、校招筆試面試時的內容和套路,非常值得參考,而且是純中文的哦!
國慶長假就要結束了,假期歇得怎么樣,是不是有點歇懶了呢?上班在即,要不要提前充充電?
近日,ICLR2019論文投稿列表公布,一篇BigGAN論文引發業界熱議。
兩相結合說明了什么?不怕別人比你優秀,怕的是比你優秀的人比你還勤奮!
勞逸結合十分重要,但相信也有不少人都準備提前充電吧。
最近,在GitHub上有位id為imhuay的熱心人帶頭建立了一個關于國內知名互聯網企業筆試和面試經驗的資源庫,光從名稱上就能看出其內容有多豐富:《2018/2019/校招/春招/秋招/算法/機器學習(MachineLearning)/深度學習(Deep Learning)/自然語言處理(NLP)/C/C++/Python/面試筆記》。
其中除了初步梳理和介紹的機器學習領域重要的基礎知識和脈絡結構之外,還總結了一些國內互聯網名企網招、校招筆試面試時的內容和套路,非常值得立志進入這些企業的小伙伴們參考,而且是純中文的哦!
目前,該資源庫在Github上已經獲得4200多星,可以說是很火熱了。
Github資源庫地址:
https://github.com/imhuay/Algorithm_Interview_Notes-Chinese
這個庫有三個貢獻者,多虧他們,才能集聚如此豐富的題庫。在此,首先向這三位開發者致謝。
下面我們一起來看看,這個資源庫收集了哪些寶貴資源。
主頁面很簡潔,就是一份按內容劃分的主目錄。除了最后一項“筆試面經”之外,其他的目錄標題都是和計算機相關的熱門主題詞。里面是相關主題詞下的一些知識介紹和技術資料,同樣值得參考。
計算機相關熱門話題知識介紹和總結
比如“機器學習”這個條目,點擊進去可以看到一些子目錄,包括“機器學習基礎”、“機器學習算法”、“機器學習實踐”、“集成學習”。
繼續點擊可以看到相關主題下的資料,比如下面就是“機器學習基礎”子目錄下關于“生成模型與判別模型”的介紹。

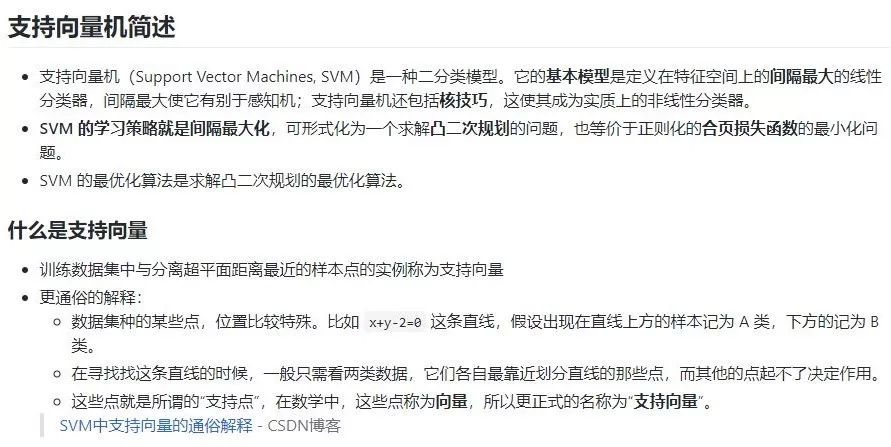
其他目錄結構與此類似,比如下圖是“機器學習算法”子目錄下對支持向量機(SVM)的介紹。
再來看看同樣熱門的“自然語言處理”,子目錄分別為:自然語言處理基礎、詞向量、句向量。
里面內容同樣相當豐富,以“自然語言處理基礎”為例,下圖分別為Seq2Seq模型和語言模型的介紹。
除了知識總結與資料介紹,相信小伙伴們最關心的還是國內互聯網名企的筆試面經了。
百度、騰訊、頭條等名企筆試面經:一面二面三面
點擊主目錄下的“筆試面經”,百度、騰訊、360、字節跳動等互聯網名企赫然在列,我們來看看這些大牛企業筆試面試都考點啥。
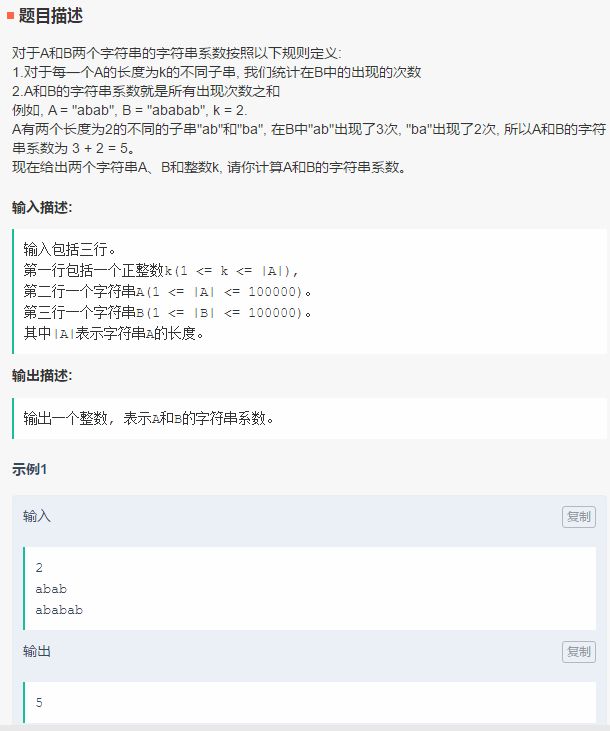
先看騰訊的筆試,更新時間為9月16日,主目錄中給出了3道筆試題,分別是字符串系數、小Q與牛牛的游戲、三元組。
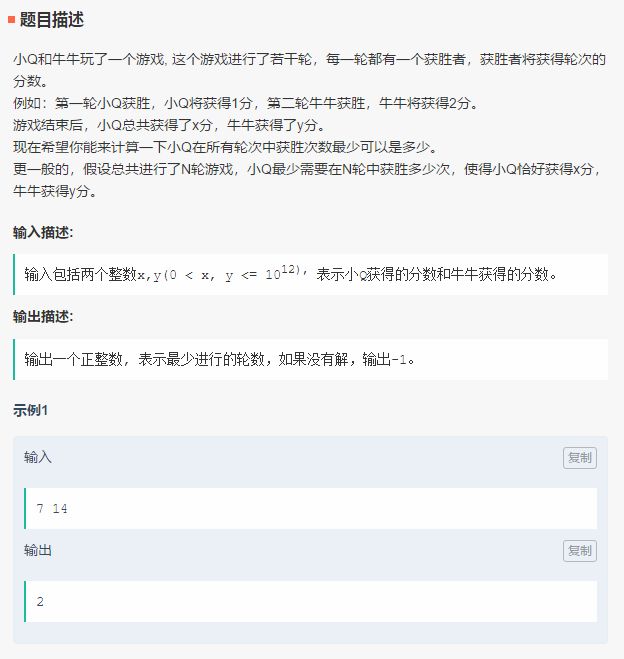
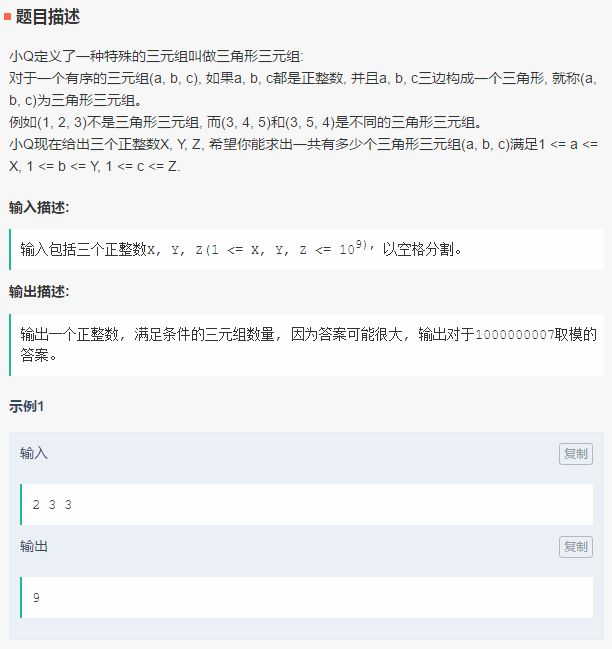
每道題的下方都給出了相應的代碼和解法,涉及Python和C++語言。下圖為第二題的解法代碼。
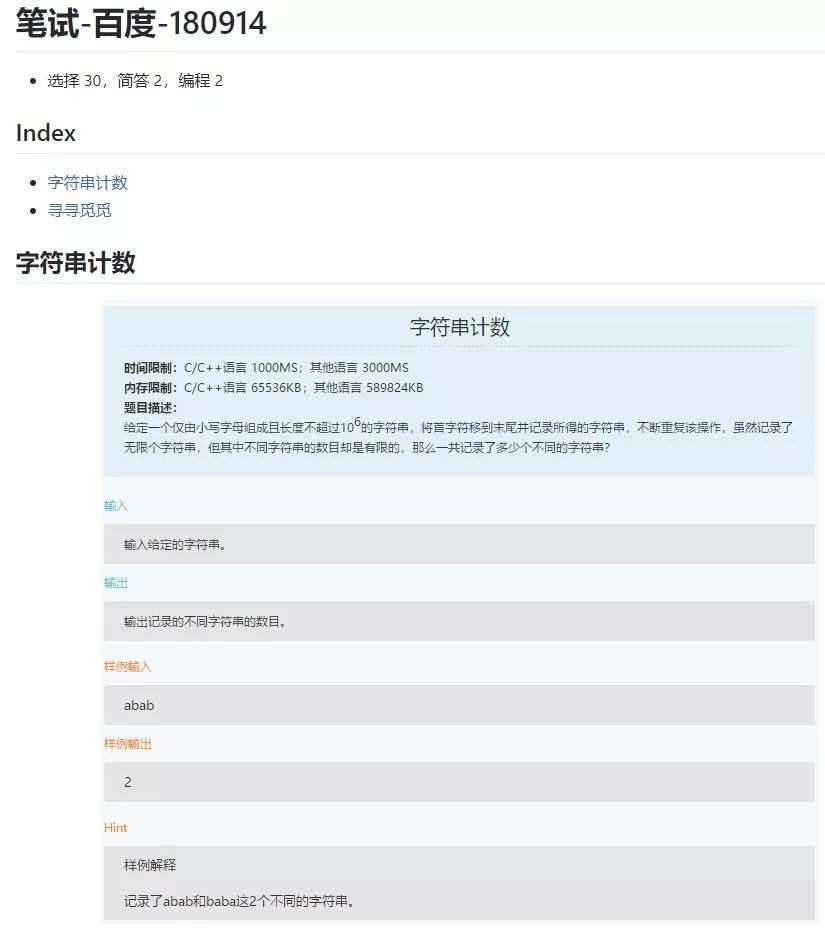
再來看看百度的筆試,更新時間為9月14日。呈現形式基本一致,收錄兩道筆試題,字符串計數、尋尋覓覓。
主目錄下還有不少企業的筆試題收錄,感興趣的小伙伴可以自行食用。
https://github.com/imhuay/Algorithm_Interview_Notes-Chinese/tree/master/D-%E7%AC%94%E8%AF%95%E9%9D%A2%E7%BB%8F
互聯網名企筆試面經:面試部分
接下來看面試,這里給出了一位小伙伴面試字節跳動深度學習/NLP方向職位的面試流程,一共四面,全程第一視角,生動形象,簡直有身臨其境之感!其中還不時穿插面試人自己的內心OS(“不會、瞎說的、尬聊”什么的,小編也是服氣),可以說是很耿直了!
不過面試時這再正常不過了,不信你去試試,畢竟你跺你也麻!
來看看這位老兄的面試經歷吧!不容易啊!
一面:
自我介紹,聊項目,深度學習基本問題
【算法】手寫 K-Means。磕磕絆絆算是寫出來一個框架,內部細節全是問題,面試官比較寬容,勉強算過了
二面:
自我介紹,聊項目,深度學習基本問題
【算法】找數組中前 k 大的數字。我說了兩個思路:最小堆和快排中的 partition 方法;讓我選一個實現,我選的堆方法,然后又讓我實現調整堆的方法。
三面:
自我介紹。為什么會出現梯度消失和梯度爆炸。
分別說了下前饋網絡和 RNN 出現梯度消失的情況,有哪些解決方法。
因為提到了殘差和門機制,所以又問,分別說下它們為什么能緩解梯度消失
因為說殘差的時候提到了 ResNet,讓我介紹下 ResNet(沒用過,隨便說了幾句)
其他加速網絡收斂的方法(除了殘差和門機制)
我從優化方法的角度說了一點(SGB 的改進:動量方法、Adam)
提示我 BN,然后我就把 BN 的做法說了一下
然后問 BN 為什么能加速網絡的收斂(從數據分布的角度隨便說了幾句)
傳統的機器學習方法(簡歷上寫用過 GBDT),簡單介紹下 XGBoost
CART 樹怎么選擇切分點(基尼系數)
基尼系數的動機、原理(不會)
【算法】直方圖蓄水問題,LeetCode 42. 接雨水;
當時太緊張沒想出 O(N) 解法,面試一結束就想出來了,哎~
附 AC 代碼
class Solution {
public:
int trap(vector
int n = H.size();
vector
vector
for(int i=1; i
dp_fw[i] = max(dp_fw[i-1], dp_fw[i]);
for(int i=n-2; i>=0; i--) // 記錄每個位置右邊的最高點
dp_bw[i] = max(dp_bw[i+1], dp_bw[i]);
int ret = 0;
for (int i=1; i
ret += min(dp_fw[i], dp_bw[i]) - H[i];
return ret;
}
};
四面(非加面)
因為流程出了問題,其實還是三面
【算法】和為 K 的連續子數組,返回首尾位置
LeetCode 560. 和為K的子數組
很熟悉的題,但就是沒想出來;然后面試官降低了難度,數組改成有序且為正整數,用雙指針勉強寫了出來;但是邊界判斷有問題,被指了出來;然后又問無序的情況或者有負數的情況能不能也用雙指針做,尬聊了幾分鐘,沒說出個所以然。
如何無監督的學習句子表示
我說 Self-Attention,讓我把公式寫出來,因為寫的不清楚,讓我寫原始的 Attention
然后問怎么訓練,損失函數是什么(沒說出來,除了詞向量我基本沒碰過無監督任務,而且我認為詞向量也算不上無監督...)
如何無監督的學習一個短視頻的特征表示
抽取關鍵幀,然后通過 ResNet 等模型對每一幀轉化為特征表示,然后對各幀的特征向量做拼接或者直接保存為二維特征(瞎說的,別說視頻,我連圖像都沒做過)
再來看一個今日頭條算法工程實習生崗位的面試:
一面:
自我介紹;二分查找;
Algorithm_for_Interview/常用子函數/二分查找模板.hpp
判斷鏈表是否有環;
Algorithm_for_Interview/鏈表/鏈表中環的入口結點.hpp
將數組元素劃分成兩部分,使兩部分和的差最小,數組順序可變;
Algorithm_for_Interview/查找與排序/暴力搜索_劃分數組使和之差最小.hpp
智力題,在一個圓環上隨機添加3個點,三個點組成一個銳角三角形的概率;
../數學問題/#1
推導邏輯斯蒂回歸、線性支持向量機算法;
../機器學習/邏輯斯蒂回歸推導
../機器學習/線性支持向量機推導
二面:
在一個圓環上隨機添加3點,三個點組成一個銳角三角形的概率,用積分計算上述概率。用程序解決上述問題。
多次采樣求概率,關鍵是如何判斷采樣的三個點能否構成銳角三角形,不同的抽象會帶來不同的復雜度。
最直接的想法是,根據邊長關系,此時需要采樣三個 x 坐標值,相應的 y 坐標通過計算得出,然后計算三邊長度,再判斷,循環以上過程,計算形成銳角的比例。
更簡單的,根據 ../數學/#1 中提到的簡單思路,原問題可以等價于“拋兩次硬幣,求兩次均為正面的概率”——此時,只需要采樣兩個(0, 1)之間的值,當兩個值都小于 0.5 意味著能構成銳角三角形。
深度學習,推導反向傳播算法,知道什么激活函數,不用激活函數會怎么樣,ROC與precesion/recall評估模型的手段有何區別,什么情況下應該用哪一種?深度學習如何參數初始化?
介紹kaggle項目,titanic,用到了哪些框架,用到了哪些算法;
三面:
自我介紹。分層遍歷二叉樹,相鄰層的遍歷方向相反,如第一層從左到右遍歷,下一層從右向左遍歷;
介紹AdaBoost算法。介紹梯度下降,隨機梯度下降。寫出邏輯斯蒂回歸的損失函數。C++,虛函數,虛析構函數。
先說到這里,Github庫中還有更多資料,只待你去探索。當然,也歡迎你把自己的面試經驗簡單總結,留給后來的小伙伴們參考哦~
-
互聯網
+關注
關注
54文章
11166瀏覽量
103449 -
機器學習
+關注
關注
66文章
8424瀏覽量
132763 -
GitHub
+關注
關注
3文章
472瀏覽量
16480
原文標題:【Github 4K星】BAT頭條滴滴小米等筆試面經+深度學習/算法/NLP資源匯總!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

GpuGeek云平臺正式上線,專注AI算法工程師需求
云互聯網是什么意思
Coremail亮相世界互聯網大會“互聯網之光”博覽會

圖像算法工程師的利器——SpeedDP深度學習算法開發平臺


FPGA算法工程師、邏輯工程師、原型驗證工程師有什么區別?
微軟GitHub推出Models服務,賦能AI工程師
GitHub推出GitHub Models服務,賦能開發者智能選擇AI模型
【HZHY-AI300G智能盒試用連載體驗】+ 智能工業互聯網網關
esp8266已連接到Wifi但無法連接到互聯網,為什么?
AIGC遇上ChatGPT,互聯網公司的創意設計師,還能做什么?
什么是衛星互聯網?衛星互聯網的組成






 工商網監
工商網監
評論