 為何基于決策樹的模型經久不衰?何時使用基于決策樹的模型?
為何基于決策樹的模型經久不衰?何時使用基于決策樹的模型?
編者按:保險業數據科學家Alan Marazzi用R語言展示了基于決策樹的模型的強大和簡潔之處。
這是一篇基于決策樹的模型的簡明介紹,盡量使用非技術術語,同時也給出了模型的R語言實現。由于這篇文章已經夠長了,因此我們省略了一些代碼。不過別擔心,你可以在配套的GitHub倉庫中找到完整代碼:https://github.com/alanmarazzi/trees-forest
為何基于決策樹的模型經久不衰
決策樹是一組通常用于分類的機器學習算法。因為它們簡單有效,所以也是初學者首先學習的算法之一。你大概很難在最新的機器學習論文和研究上看到它們,但在真實世界項目中,基于決策樹的模型仍被廣泛使用。
之所以得到如此廣泛的使用,主要原因之一是它們的簡單性和可解釋性。下面是一棵預測天氣是否多云的簡單決策樹。
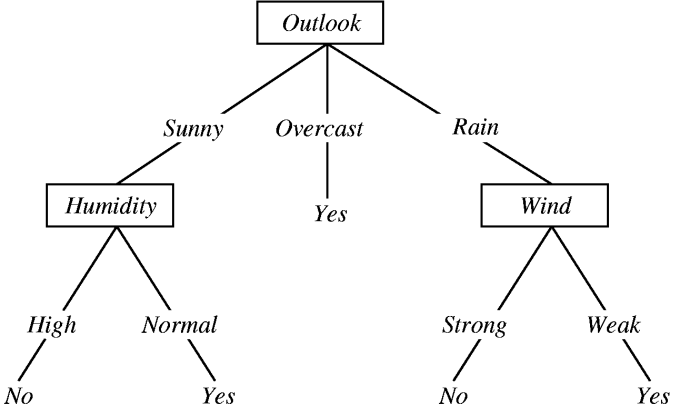
這一方法讓我們可以通過傳入數據預測某個變量,不過,大概更重要的是我們可以推斷預測因子之間的關系。這意味著我們可以從底部開始,看看哪些因素導致了多云。
比如,如果風很小,看起來要下雨了,那說明是多云。對簡單模型而言,這些規則可以被人類所學習和應用,或者我們可以生成一份清單以輔助決策過程。通過可視化決策樹,我們可以理解機器是如何工作的,為何將某些日子分類為多云,將另一些日子分類為非多云。
盡管這看起來挺微不足道的,但在許多情形下,我們需要知道模型為何做出某些預測。考慮一個預測是否接受胸痛患者的模型。在測試了許多高級模型之后,醫生想要搞清楚算法為什么讓某些處以危險之中的患者回家。所以他們在數據上運行了一個基于決策樹的模型,結果發現算法認為患有哮喘的胸痛病人風險很小。
這是一個巨大的錯誤。醫生非常清楚哮喘和胸痛必須立刻治療,這意味著哮喘和胸痛的病人會馬上得到收治。你發現問題所在了吧?用于建模的數據認為這類病人風險很小,是因為所有這類病人都得到了治療,所以極少有人在此之后死亡。
何時使用基于決策樹的模型
如前所述,當可解釋性很重要時,決策樹非常好,即使它可能僅用于理解預測哪里出錯了。實際上,基于決策樹的模型可以變得非常復雜,在損失可解釋性的同時,增加準確性。這里存在著一個權衡。
另一個使用決策樹的理由是它們非常容易理解和解釋。在有一些強預測因子的情形下,決策樹可以用來創建可以同時為機器和人類使用的模型。我剛想到的一個例子是預測顧客是否最終會購買某物的決策樹模型。
評測也是這些方法大放異彩之處:你很快會發現,用于分類時,即使是相當簡單的基于決策樹的模型,也很難被大幅超過。我個人經常在要處理的數據集上運行隨機森林(后文會介紹這一算法),接著嘗試戰勝它。
R語言配置
在開始之前,你可能需要先配置一下R環境。
安裝如下包:
trees_packages <- c("FFTrees", ? ?"evtree", ? ?"party", ? ?"randomForest", ? ?"intubate", ? ?"dplyr")install.packages(trees_packages)
這些是在R語言中使用基于決策樹的模型和數據處理的主要包,但它們不是唯一的。任何你打算使用的基于決策樹的模型,幾乎都有幾十個包可以用,不信的話可以上Crantastic搜索一番。
現在是植樹時刻!我決定使用Titanic數據集,機器學習社區最著名的數據集之一。你可以從Kaggle(c/titanic)或GitHub(alanmarazzi/trees-forest)獲取這一數據集。我將直接從清洗數據和建模開始講起,如果你在數據下載、加載上需要幫助,或者缺乏頭緒,可以參考我之前的文章Data Science in Minutes或者GitHub倉庫中的完整代碼。
預備數據
首先,我們看下要處理的數據是什么樣子的:
我真心不喜歡有大寫字母姓名的數據集,很幸運,我們可以用tolower()函數,一行代碼轉換為小寫字母:
names(titanic) <- tolower(names(titanic))
接著,將sex和embarked變量轉換為因子(類別變量):
titanic$sex <- as.factor(titanic$sex)titanic$embarked <- as.factor(titanic$embarked)
建模時最重要的步驟之一是處理缺失值(NA)。許多R模型可以自動處理缺失值,但大多數只不過是直接移除包含缺失值的觀測。這意味著可供模型學習的訓練數據變少了,這幾乎一定會導致準確率下降。
有各種填充NA的技術:填充均值、中位數、眾數,或使用一個模型預測它們的值。我們的例子將使用線性回歸替換數據集中年齡變量的缺失值。
乍看起來這個想法有點嚇人,有點怪異,你可能會想:“你說的是,為了改進我的模型,我應該使用另一個模型?!”但其實并沒有看起來這么難,特別是如果我們使用線性回歸的話。
首先讓我們看下年齡變量中有多少NA:
mean(is.na(titanic$age))[1] 0.1986532
將近20%的乘客沒有年齡記錄,這意味著如果我們不替換缺失值,直接在數據集上運行模型的話,我們的訓練數據只有714項,而不是891項。
是時候在數據上跑下線性回歸了:
age_prediction <- lm(age ~ survived + pclass + fare, data = titanic)summary(age_prediction)
我們干了什么?我們告訴R求解如下線性等式,找出恰當的α、βn的值。
age = α + β1?survived + β2?pclass + β3?fare
然后我們在創建的模型上調用summary()函數,查看線性回歸的結果。R會給出一些統計數據,我們需要查看這些數據以了解數據的情況:
Call:lm(formula = age ~ survived + pclass + fare, data = titanic)Residuals: Min 1Q Median 3Q Max -37.457 -8.523 -1.128 8.060 47.505 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 54.14124 2.04430 26.484 < 2e-16 ***survived ? ?-6.81709 ? ?1.06801 ?-6.383 3.14e-10 ***pclass ? ? ?-9.12040 ? ?0.72469 -12.585 ?< 2e-16 ***fare ? ? ? ?-0.03671 ? ?0.01112 ?-3.302 ?0.00101 ** ---Signif. codes: ?0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 13.03 on 710 degrees of freedom ?(177 observations deleted due to missingness)Multiple R-squared: ?0.1993, ? ?Adjusted R-squared: ?0.1959 F-statistic: ?58.9 on 3 and 710 DF, ?p-value: < 2.2e-16
上面第一行(Call)提示我們是哪個模型產生了這一結果,第二行顯示了殘差,之后是系數。這里我們可以查看系數的估計值,它們的標準差,t值和p值。之后是一些其他統計數據。我們看到R實際上移除了含NA的數據(177 observations deleted due to missingness)。
現在我們可以使用這個模型來填充NA了。我們使用predict()函數:
titanic$age[is.na(titanic$age)] <- predict(age_prediction, ? ?newdata = titanic[is.na(titanic$age),])
邏輯回歸基準
是否幸存這樣的二元分類問題,邏輯回歸很難戰勝。我們將使用邏輯回歸預測泰坦尼克幸存者,并將這一結果作為基準。
別擔心,在R中進行邏輯回歸非常直截了當。我們引入dplyr和intubate庫,然后調用glm()函數運行邏輯回歸。glm()接受三個參數,predictors為預測因子,例如年齡、艙等,response為結果變量,這里我們傳入survived,family指定返回結果的類別,這里我們傳入binomial。
library(dplyr) # 數據處理library(intubate) # 建模工作流# btbt_glb是 %>% 版本的glm函數logi <- titanic %>% select(survived, pclass, sex, age, sibsp) %>% ntbt_glm(survived ~ ., family = binomial)summary(logi)
下面讓我們查看下邏輯回歸模型做出的預測:
# 收集訓練數據上的預測logi_pred <- predict(logi, type = "response")# 預測值在0和1之間,我們將其轉換為`survived`或`not`survivors_logi <- rep(0, nrow(titanic))survivors_logi[logi_pred > .5] <- 1# 這將成為我們的基準table(model = survivors_logi, real = titanic$survived)
上面的混淆矩陣給出了模型在訓練數據上的結果:預測572人死亡(0),319人幸存(1)。矩陣的對角線表明,480項和250項預測正確,而預測死亡的92人實際上幸存了,預測幸存的69人實際上未能幸存。
對這樣開箱即用的模型而言,82%的預測精確度已經相當不錯了。但是我們想在未見數據上測試一下,所以讓我們載入測試集,試下模型在測試集上的效果。
test <- read.csv(paste0("https://raw.githubusercontent.com/", ? ?"alanmarazzi/trees-forest/master/data/test.csv"), ? ?stringsAsFactors = FALSE, ? ?na.strings = "")# 和訓練集一樣,清洗下數據names(test) <- tolower(names(test))test$sex <- as.factor(test$sex)
下面在測試數據上預測幸存率:
test_logi_pred <- predict(logi, test, type = "response")surv_test_logi <- data.frame(PassengerId = test$passengerid, ? ?Survived = rep(0, nrow(test)))surv_test_logi$Survived[test_logi_pred > .5] <- 1write.csv(surv_test_logi, "results/logi.csv", row.names = FALSE)
我們將結果保存為csv,因為測試數據沒有標簽,我們并不知道預測是否正確。我們需要將結果上傳到Kaggle以查看結果。最終模型做出了77.5%的正確預測。
快速和低成本決策樹
終于可以開始植樹了!我們將嘗試的第一個模型是快速和低成本決策樹。這基本上是最簡單的模型。我們將使用R的FFTrees包。
# 臨時復制下數據集,因為FFTrees包里也包含titanic變量titanicc <- titaniclibrary(FFTrees)titanic <- titaniccrm(titanicc)
載入包,我們只需在選中的變量上應用FFTrees。
fftitanic <- titanic %>% select(age, pclass, sex, sibsp, fare, survived) %>% ntbt(FFTrees, survived ~ .)
模型需要跑一會兒,因為要訓練和測試不止一棵FFTree。最終得到的結果是一個FFTree對象,包含了所有測試過的FFTree:
fftitanic[1] "An FFTrees object containing 8 trees using 4 predictors {sex,pclass,fare,age}"[1] "FFTrees AUC: (Train = 0.84, Test = --)"[1] "My favorite training tree is #5, here is how it performed:" trainn 891.00p(Correct) 0.79Hit Rate (HR) 0.70False Alarm Rate (FAR) 0.16d-prime 1.52
我們看到,算法使用最多4個預測因子測試了8棵樹,表現最佳的是5號樹。接著我們看到了這棵樹的一些統計數據。這些輸出很有幫助,但可視化方法能夠更好地幫助我們理解發生了什么:
plot(fftitanic, main = "Titanic", decision.names = c("Not Survived", "Survived"))
這一張圖中有大量信息,從上往下依次為:觀測數目、分類數目、決策樹、診斷數據。讓我們重點關注決策樹。
決策樹的第一個節點考慮sex變量:如果是女性(sex != male),我們將直接退出決策樹,預測幸存。粗暴,但相當有效。如果是男性,將通過第二個節點pclass。這里,如果是三等艙,我們將退出決策樹,預測死亡。接著,如果船費超過£ 26.96(fare),預測幸存。最后一個節點考慮的是age(年齡):如果年齡大于21.35歲,預測死亡。
在圖表的Performance(表現)區域,我們最關心左側的混淆矩陣,我們可以對比之前邏輯回歸得到的混淆矩陣。
此外,我們也可以查看下右側的ROC曲線。FFTrees包在數據上自動運行邏輯回歸和CART(另一種基于決策樹的模型),以供比較。仔細看圖,我們看到,代表邏輯回歸的圓圈基本上完全被5號樹的圓圈蓋住了,意味著這兩個模型表現相當。
現在我們分類測試數據,并提交結果至Kaggle。如同我之前說過的那樣,這些決策樹極為簡單。我上面解釋決策樹如何工作時,解釋每一個節點的句子中都有“如果”,這意味著我們可以依照同樣的結構創建一個基于清單的分類器,或者,我們甚至可以記住這些規則,然后手工分類。
ffpred <- ifelse(test$sex != "male", 1, ? ? ? ? ? ? ? ? ifelse(test$pclass > 2, 0, ifelse(test$fare < 26.96, 0, ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ifelse(test$age >= 21.36, 0, 1))))ffpred[is.na(ffpred)] <- 0
只需4個嵌套的ifelse語句,我們就可以分類整個數據集。我們只有2個NA,所以我決定將它們分類為“未幸存”。接著我們只需將csv格式的結果上傳到Kaggle,看看模型表現如何。
我們的4個if-else語句表現只比基準差了1%. 考慮到模型的簡單性,這是非常出色的成績。
聚會時分
party包使用條件推理樹,比FFTrees更復雜的決策樹。簡單來說,條件推理樹在決定分割節點時,不僅考慮重要性,還考慮數據分布。雖然條件推理樹更復雜,但使用起來很簡單,加載包后只需使用ctree函數即可創建決策樹。
library(party)partyTitanic <- titanic %>% select(age, pclass, sex, sibsp, fare, survived) %>% ntbt(ctree, as.factor(survived) ~ .)
運行模型后,我們可以調用這個包的繪圖函數可視化得到的決策樹,plot(ctree_relust)。這里我們不在乎其他花里胡哨的東西,只在意最終得到的決策樹。所以會使用一些可選參數讓輸出整潔一點。
plot(partyTitanic, main = "Titanic prediction", type = "simple", inner_panel = node_inner(partyTitanic, pval = FALSE), terminal_panel = node_terminal(partyTitanic, abbreviate = TRUE, digits = 1, fill = "white"))
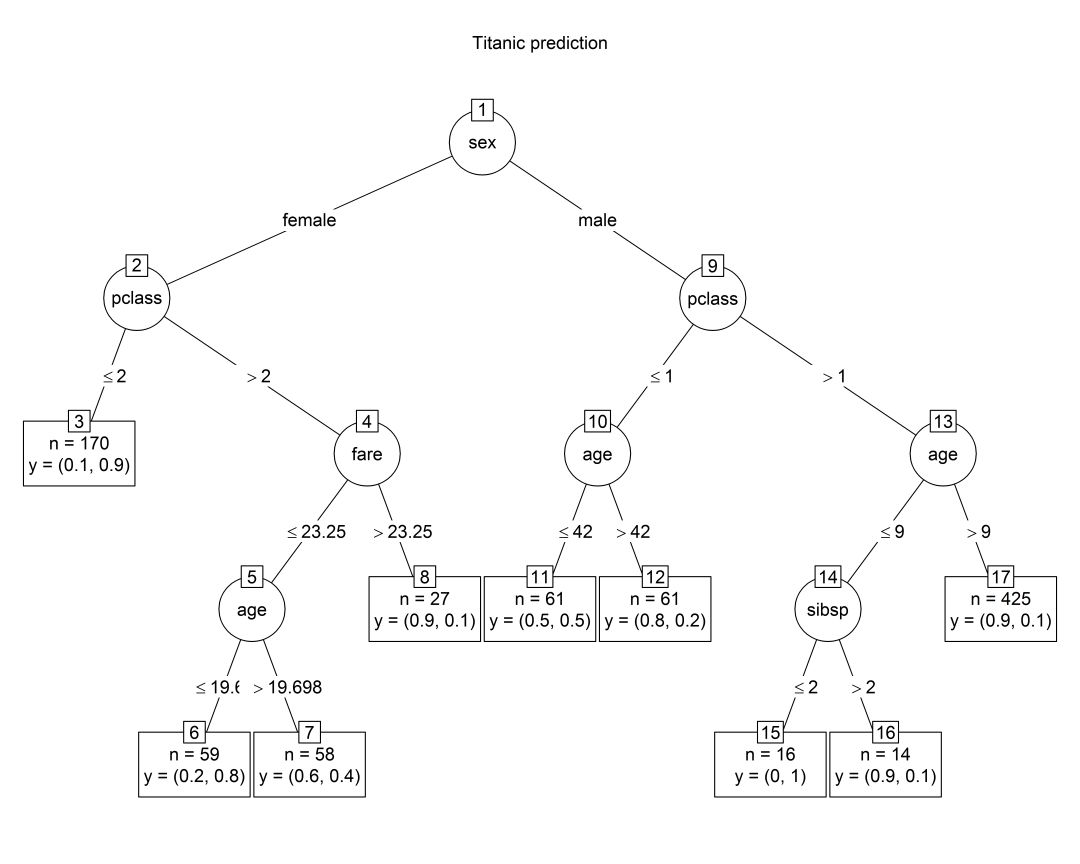
不幸的是較大的樹占用更多空間,如果再加上一些節點,圖就基本上看不清了。將這棵樹和上面那棵FFTree比較一下,我們看到現在這棵樹更復雜:之前我們直接預測每個男性死亡,現在這個模型嘗試將男性分為多種情況。
增加的復雜性降低了15%的訓練誤差。和上面的FFTree相比,這是一項改進。
train_party <- Predict(partyTitanic)table(tree = train_party, real = titanic$survived)
不過,很遺憾,我們下面將學到機器學習最重要的一課。事實上,在測試集上的分類正確率只有73.7%!
你也許會問,這怎么可能?我們剛看到的是過擬合現象。模型考慮的一些變量最終看來其實是噪聲。結果在訓練集上改善了,但在未見數據上的表現變差了。有多種應對這一問題的方式,比如剪枝。剪枝的意思是削減分支,比如通過降低樹的最大深度達成。剪枝搭配交叉驗證,很可能改善測試數據上的結果。
集成模型
目前為止,我們開發的都是單個學習者,意味著我們通過一個模型找到解決方案。另一系列的機器學習算法是集成,通過許多所謂的弱小學習者創建的模型。背后的理論是通過使用許多學習者(在我們的例子中是決策樹),結合他們的選擇,我們能得到良好的結果。
集成模型因模型創建方法、組合結果方式的不同而不同。可能看起來有點雜亂,但部分集成方法通常是開箱即用的,是一個很好的優化結果的選擇。
集成的目的是為了減少方差。比如,我們上面在訓練集上得到了良好的結果,但在測試集上的誤差率卻很大。如果我們有不同的訓練集,不同的模型,那么各自會有不同的偏差,集成之后就能得到更好的結果。
我們將查看三種不同的集成算法:Bagging、隨機森林、Boosting。
Bagging
bagging的主要思路相當簡單:如果我們在不同的訓練集上訓練許多較大的決策樹,我們將得到許多高方差、低偏差的模型。平均每棵樹的預測,我們就能得到方差和偏差相對較低的分類。
你可能已經發現一個問題,我們并沒有許多訓練集。為了應對這一問題,我們通過bootstrap方法創建這些訓練集。bootstrap不過是一種有放回的重復取樣方法。
x <- rnorm(100) # 生成隨機向量# 定義固定取樣函數boot_x <- function(x, size) { ? ?sample(x, size, replace = TRUE)}# 循環取樣,直到取滿需要的樣本bootstrapping <- function(x, reps, size) { ? ?y <- list() ? ?for (i in seq_len(reps)) { ? ? ? ?y[[i]] <- boot_x(x, size) ? ?} ? ?y}# 結果是一個列表z <- bootstrapping(x, 500, 20)
為了在泰坦尼克數據上運行bagging,我們可以使用randomForest包。這是因為bagging和隨機森林差不多,唯一的區別是在創建決策樹時考慮多少預測因子。bagging中,我們考慮數據集中的每個預測因子,我們可以通過設置mtry參數做到這一點。
library(randomForest)# 如果你希望重現結果,別忘了設置一樣的隨機數種子set.seed(123)# 創建bagging模型titanic_bag <- titanic %>% select(survived, age, pclass, sex, sibsp, fare, parch) %>% ntbt_randomForest(as.factor(survived) ~ ., mtry = 6)
注意,這里我們將survived作為因子(as.factor)傳入,這樣就可以使函數創建分類樹,而不是回歸樹(是的,決策樹同樣可以用于回歸)。
bagging默認創建500棵樹,如果你想要增加更多樹,可以傳入ntree參數,設定一個更高的數值。
上面的代碼有一個問題,直接跳過NA,不作預測。為了在避免進一步特征工程的前提下,生成符合Kaggle要求的結果,我決定將測試集中的NA用中位數替換。不幸的是,這個問題限制了預測能力,結果是66.5%的正確預測率。
隨機森林
隨機森林是最著名的機器學習算法之一,原因是它開箱即用的效果好到沒道理。隨機森林幾乎和bagging一樣,只不過使用較弱的學習者,創建決策樹時只考慮有限數量的預測因子。
你可能會問使用全部預測因子和僅使用部分預測因子有什么區別。答案是使用所有預測因子時,在不同的bootstrap取樣的數據集上創建決策樹時,前兩個分割很可能是一樣的,因為創建決策樹時考慮的是預測因子的重要性。所以使用bagging創建的500棵樹會很相似,相應地,做出的預測也會很相似。
為了限制這一行為,我們使用隨機森林,通過mtry參數限制預測因子。我們使用交叉驗證決定“最好”的參數值,或者嘗試一些經驗法則,比如ncol(data)/3和sqrt(ncol(data)),不過在這個例子中我將mtry參數值定為3.
我建議你試驗不同的值,然后查看發生了什么,以更好地理解隨機森林算法。
set.seed(456)titanic_rf <- titanic %>% select(survived, age, pclass, sex, sibsp, fare, parch) %>% ntbt_randomForest(as.factor(survived) ~ ., mtry = 3, n.trees = 5000)
結果是74.6%,比bagging要好不少(譯者注:這里的比較不是很公平,因為之前bagging只用了500棵樹,而這里隨機森林用了5000棵樹,感興趣的讀者可以試下統一數量后再做比較),但還是比邏輯回歸差一點。
隨機森然有很多實現,也許我們可以嘗試下party包,用下條件推斷樹構成的隨機森林。
set.seed(415)titanic_rf_party <- titanic %>% select(survived, age, pclass, sex, sibsp, fare, parch) %>% ntbt(cforest, as.factor(survived) ~ ., controls = cforest_unbiased(ntree = 5000, mtry = 3))
如你所見,代碼和之前差不多,但是結果是不是差不多呢?
這個結果差不多可以算是和邏輯回歸打了個平手。
Boosting
和之前“奮發”學習的算法不同,boosting緩慢學習。實際上,為了避免過擬合,bagging和隨機森林需要創建幾千棵決策樹,然后平均所有預測。boosting的方式與此不同:創建一棵樹,結果基于第一棵樹的結果創建另一棵樹,以此類推。
boosting比其他基于決策樹的算法學得慢,這有助于防止過擬合,但也要求我們小心地調整學習速度。從下面的代碼中,我們能看到,boosting的參數和隨機森林比較相似。
library(gbm)set.seed(999)titanic_boost <- titanic %>% select(survived, age, pclass, sex, sibsp, fare, parch) %>% ntbt(gbm, survived ~ ., distribution = "bernoulli", n.trees = 5000, interaction.depth = 3)
我們使用gbm包中的同名函數(ntbt),并指定distribution參數為bernoulli(伯努利分布),告訴函數這是一個分類問題。n.trees參數指定創建決策樹的數目,interaction.depth指定樹的最大深度。
76%,和邏輯回歸、隨機森林、FFTrees的結果差不多。
我們學到了
復雜模型 > 簡單模型 == 假。邏輯回歸和FFTrees很難戰勝,而且我們只需一點特征工程就可以進一步提升簡單模型的表現。
特征工程 > 復雜模型 == 真。特征工程是一項藝術。它是數據科學家最強大的武器之一,我們可以使用特征工程改進預測。
創建模型 == 樂!數據科學家很有意思。盡管R有時會讓人有點沮喪,但總體而言學習R回報豐厚。如果你希望進一步了解細節,或者想要一個逐步的指南,你可以訪問文章開頭提到的GitHub倉庫,里面有完整的代碼。
如果你喜歡這篇文章,請留言、轉發。你也可以訂閱我的博客rdisorder.eu
-
數據集
+關注
關注
4文章
1208瀏覽量
24719 -
決策樹
+關注
關注
3文章
96瀏覽量
13558 -
r語言
+關注
關注
1文章
30瀏覽量
6293
原文標題:別迷失在森林里
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于決策樹,這些知識點不可錯過
介紹支持向量機與決策樹集成等模型的應用
決策樹的生成資料
決策樹的構建設計并用Graphviz實現決策樹的可視化
決策樹的原理和決策樹構建的準備工作,機器學習決策樹的原理
決策樹和隨機森林模型
詳談機器學習的決策樹模型

什么是決策樹模型,決策樹模型的繪制方法





 工商網監
工商網監
評論