 NLP領域取得最重大突破!BERT模型開啟了NLP的新時代!
NLP領域取得最重大突破!BERT模型開啟了NLP的新時代!
今天,NLP領域取得最重大突破!谷歌AI團隊新發布的BERT模型,在機器閱讀理解頂級水平測試SQuAD1.1中表現出驚人的成績:全部兩個衡量指標上全面超越人類,并且還在11種不同NLP測試中創出最佳成績。毋庸置疑,BERT模型開啟了NLP的新時代!
今天請記住BERT模型這個名字。
谷歌AI團隊新發布的BERT模型,在機器閱讀理解頂級水平測試SQuAD1.1中表現出驚人的成績:全部兩個衡量指標上全面超越人類!并且還在11種不同NLP測試中創出最佳成績,包括將GLUE基準推至80.4%(絕對改進7.6%),MultiNLI準確度達到86.7% (絕對改進率5.6%)等。
谷歌團隊的Thang Luong直接定義:BERT模型開啟了NLP的新時代!
本文從論文解讀、BERT模型的成績以及業界的評價三方面做介紹。
硬核閱讀:認識BERT的新語言表示模型
首先來看下谷歌AI團隊做的這篇論文。
論文地址:
https://arxiv.org/abs/1810.04805
BERT的新語言表示模型,它代表Transformer的雙向編碼器表示。與最近的其他語言表示模型不同,BERT旨在通過聯合調節所有層中的上下文來預先訓練深度雙向表示。因此,預訓練的BERT表示可以通過一個額外的輸出層進行微調,適用于廣泛任務的最先進模型的構建,比如問答任務和語言推理,無需針對具體任務做大幅架構修改。
論文作者認為現有的技術嚴重制約了預訓練表示的能力。其主要局限在于標準語言模型是單向的,這使得在模型的預訓練中可以使用的架構類型很有限。
在論文中,作者通過提出BERT:即Transformer的雙向編碼表示來改進基于架構微調的方法。
BERT 提出一種新的預訓練目標:遮蔽語言模型(masked language model,MLM),來克服上文提到的單向性局限。MLM 的靈感來自 Cloze 任務(Taylor, 1953)。MLM 隨機遮蔽模型輸入中的一些 token,目標在于僅基于遮蔽詞的語境來預測其原始詞匯 id。
與從左到右的語言模型預訓練不同,MLM 目標允許表征融合左右兩側的語境,從而預訓練一個深度雙向 Transformer。除了遮蔽語言模型之外,本文作者還引入了一個“下一句預測”(next sentence prediction)任務,可以和MLM共同預訓練文本對的表示。
論文的核心:詳解BERT模型架構
本節介紹BERT模型架構和具體實現,并介紹預訓練任務,這是這篇論文的核心創新。
模型架構
BERT的模型架構是基于Vaswani et al. (2017) 中描述的原始實現multi-layer bidirectional Transformer編碼器,并在tensor2tensor庫中發布。由于Transformer的使用最近變得無處不在,論文中的實現與原始實現完全相同,因此這里將省略對模型結構的詳細描述。
在這項工作中,論文將層數(即Transformer blocks)表示為L,將隱藏大小表示為H,將self-attention heads的數量表示為A。在所有情況下,將feed-forward/filter 的大小設置為 4H,即H = 768時為3072,H = 1024時為4096。論文主要報告了兩種模型大小的結果:
: L=12, H=768, A=12, Total Parameters=110M
: L=24, H=1024, A=16, Total Parameters=340M
為了進行比較,論文選擇,它與OpenAI GPT具有相同的模型大小。然而,重要的是,BERT Transformer 使用雙向self-attention,而GPT Transformer 使用受限制的self-attention,其中每個token只能處理其左側的上下文。研究團隊注意到,在文獻中,雙向 Transformer 通常被稱為“Transformer encoder”,而左側上下文被稱為“Transformer decoder”,因為它可以用于文本生成。BERT,OpenAI GPT和ELMo之間的比較如圖1所示。
圖1:預訓練模型架構的差異。BERT使用雙向Transformer。OpenAI GPT使用從左到右的Transformer。ELMo使用經過獨立訓練的從左到右和從右到左LSTM的串聯來生成下游任務的特征。三個模型中,只有BERT表示在所有層中共同依賴于左右上下文。
輸入表示(input representation)
論文的輸入表示(input representation)能夠在一個token序列中明確地表示單個文本句子或一對文本句子(例如, [Question, Answer])。對于給定token,其輸入表示通過對相應的token、segment和position embeddings進行求和來構造。圖2是輸入表示的直觀表示:
圖2:BERT輸入表示。輸入嵌入是token embeddings, segmentation embeddings 和position embeddings 的總和。
具體如下:
使用WordPiece嵌入(Wu et al., 2016)和30,000個token的詞匯表。用##表示分詞。
使用學習的positional embeddings,支持的序列長度最多為512個token。
每個序列的第一個token始終是特殊分類嵌入([CLS])。對應于該token的最終隱藏狀態(即,Transformer的輸出)被用作分類任務的聚合序列表示。對于非分類任務,將忽略此向量。
句子對被打包成一個序列。以兩種方式區分句子。首先,用特殊標記([SEP])將它們分開。其次,添加一個learned sentence A嵌入到第一個句子的每個token中,一個sentence B嵌入到第二個句子的每個token中。
對于單個句子輸入,只使用 sentence A嵌入。
關鍵創新:預訓練任務
與Peters et al. (2018) 和 Radford et al. (2018)不同,論文不使用傳統的從左到右或從右到左的語言模型來預訓練BERT。相反,使用兩個新的無監督預測任務對BERT進行預訓練。
任務1: Masked LM
從直覺上看,研究團隊有理由相信,深度雙向模型比left-to-right 模型或left-to-right and right-to-left模型的淺層連接更強大。遺憾的是,標準條件語言模型只能從左到右或從右到左進行訓練,因為雙向條件作用將允許每個單詞在多層上下文中間接地“see itself”。
為了訓練一個深度雙向表示(deep bidirectional representation),研究團隊采用了一種簡單的方法,即隨機屏蔽(masking)部分輸入token,然后只預測那些被屏蔽的token。論文將這個過程稱為“masked LM”(MLM),盡管在文獻中它經常被稱為Cloze任務(Taylor, 1953)。
在這個例子中,與masked token對應的最終隱藏向量被輸入到詞匯表上的輸出softmax中,就像在標準LM中一樣。在團隊所有實驗中,隨機地屏蔽了每個序列中15%的WordPiece token。與去噪的自動編碼器(Vincent et al., 2008)相反,只預測masked words而不是重建整個輸入。
雖然這確實能讓團隊獲得雙向預訓練模型,但這種方法有兩個缺點。首先,預訓練和finetuning之間不匹配,因為在finetuning期間從未看到[MASK]token。為了解決這個問題,團隊并不總是用實際的[MASK]token替換被“masked”的詞匯。相反,訓練數據生成器隨機選擇15%的token。例如在這個句子“my dog is hairy”中,它選擇的token是“hairy”。然后,執行以下過程:
數據生成器將執行以下操作,而不是始終用[MASK]替換所選單詞:
80%的時間:用[MASK]標記替換單詞,例如,my dog is hairy → my dog is [MASK]
10%的時間:用一個隨機的單詞替換該單詞,例如,my dog is hairy → my dog is apple
10%的時間:保持單詞不變,例如,my dog is hairy → my dog is hairy. 這樣做的目的是將表示偏向于實際觀察到的單詞。
Transformer encoder不知道它將被要求預測哪些單詞或哪些單詞已被隨機單詞替換,因此它被迫保持每個輸入token的分布式上下文表示。此外,因為隨機替換只發生在所有token的1.5%(即15%的10%),這似乎不會損害模型的語言理解能力。
使用MLM的第二個缺點是每個batch只預測了15%的token,這表明模型可能需要更多的預訓練步驟才能收斂。團隊證明MLM的收斂速度略慢于 left-to-right的模型(預測每個token),但MLM模型在實驗上獲得的提升遠遠超過增加的訓練成本。
任務2:下一句預測
許多重要的下游任務,如問答(QA)和自然語言推理(NLI)都是基于理解兩個句子之間的關系,這并沒有通過語言建模直接獲得。
在為了訓練一個理解句子的模型關系,預先訓練一個二進制化的下一句測任務,這一任務可以從任何單語語料庫中生成。具體地說,當選擇句子A和B作為預訓練樣本時,B有50%的可能是A的下一個句子,也有50%的可能是來自語料庫的隨機句子。例如:
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
團隊完全隨機地選擇了NotNext語句,最終的預訓練模型在此任務上實現了97%-98%的準確率。
實驗結果
如前文所述,BERT在11項NLP任務中刷新了性能表現記錄!在這一節中,團隊直觀呈現BERT在這些任務的實驗結果,具體的實驗設置和比較請閱讀原論文。
圖3:我們的面向特定任務的模型是將BERT與一個額外的輸出層結合而形成的,因此需要從頭開始學習最小數量的參數。在這些任務中,(a)和(b)是序列級任務,而(c)和(d)是token級任務。在圖中,E表示輸入嵌入,Ti表示tokeni的上下文表示,[CLS]是用于分類輸出的特殊符號,[SEP]是用于分隔非連續token序列的特殊符號。
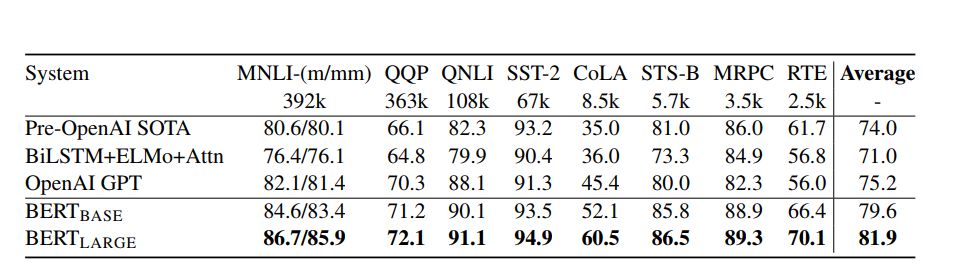
圖4:GLUE測試結果,由GLUE評估服務器給出。每個任務下方的數字表示訓練樣例的數量。“平均”一欄中的數據與GLUE官方評分稍有不同,因為我們排除了有問題的WNLI集。BERT 和OpenAI GPT的結果是單模型、單任務下的數據。所有結果來自https://gluebenchmark.com/leaderboard和https://blog.openai.com/language-unsupervised/
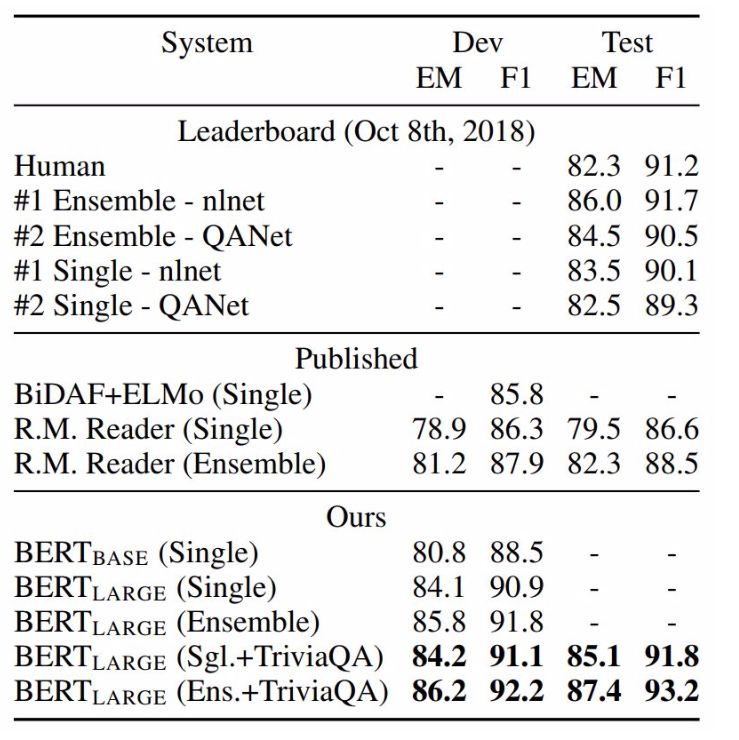
圖5:SQuAD 結果。BERT 集成是使用不同預訓練檢查點和微調種子(fine-tuning seed)的 7x 系統。
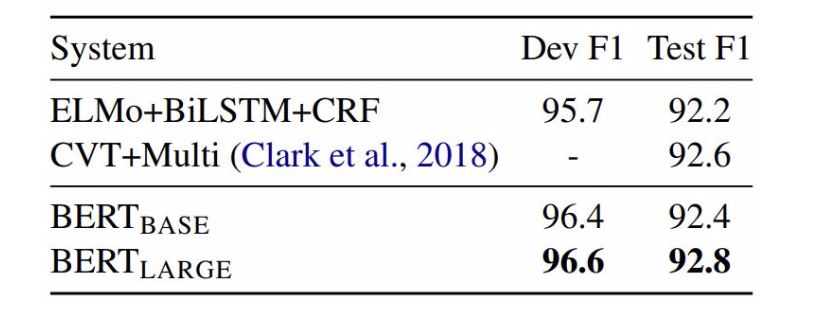
圖6:CoNLL-2003 命名實體識別結果。超參數由開發集選擇,得出的開發和測試分數是使用這些超參數進行五次隨機重啟的平均值。
超過人類表現,BERT刷新了11項NLP任務的性能記錄
論文的主要貢獻在于:
證明了雙向預訓練對語言表示的重要性。與之前使用的單向語言模型進行預訓練不同,BERT使用遮蔽語言模型來實現預訓練的深度雙向表示。
論文表明,預先訓練的表示免去了許多工程任務需要針對特定任務修改體系架構的需求。 BERT是第一個基于微調的表示模型,它在大量的句子級和token級任務上實現了最先進的性能,強于許多面向特定任務體系架構的系統。
BERT刷新了11項NLP任務的性能記錄。本文還報告了 BERT 的模型簡化研究(ablation study),表明模型的雙向性是一項重要的新成果。相關代碼和預先訓練的模型將會公布在goo.gl/language/bert上。
BERT目前已經刷新的11項自然語言處理任務的最新記錄包括:將GLUE基準推至80.4%(絕對改進7.6%),MultiNLI準確度達到86.7% (絕對改進率5.6%),將SQuAD v1.1問答測試F1得分紀錄刷新為93.2分(絕對提升1.5分),超過人類表現2.0分。
BERT模型重要意義:宣告NLP范式的改變
北京航空航天大學計算機專業博士吳俁在知乎上寫道:BERT模型的地位類似于ResNet在圖像,這是里程碑式的工作,宣告著NLP范式的改變。以后研究工作估計很多都要使用他初始化,就像之前大家使用word2vec一樣自然。
BERT一出,那幾個他論文里做實驗的數據集全被轟平了,大家洗洗睡了。心疼swag一秒鐘,出現3月,第一篇做這個數據集的算法,在超了baseline 20多點的同時也超過人了。
通過BERT模型,吳俁有三個認識:
1、Jacob在細節上是一等一的高手
這個模型的雙向和Elmo不一樣,大部分人對論文作者之一Jacob的雙向在novelty上的contribution 的大小有誤解,我覺得這個細節可能是他比Elmo顯著提升的原因。Elmo是拼一個左到右和一個右到左,他這個是訓練中直接開一個窗口,用了個有順序的cbow。
2、Reddit對跑一次BERT的價格討論
For TPU pods:
4 TPUs * ~$2/h (preemptible) * 24 h/day * 4 days = $768 (base model)
16 TPUs = ~$3k (large model)
For TPU:
16 tpus * $8/hr * 24 h/day * 4 days = 12k
64 tpus * $8/hr * 24 h/day * 4 days = 50k
For GPU:
"BERT-Large is 24-layer, 1024-hidden and was trained for 40 epochs over a 3.3 billion word corpus. So maybe 1 year to train on 8 P100s? "
3、不幸的是,基本無法復現,所以模型和數據誰更有用也不好說。
BERT的成功也說明,好的深度學習研究工作的三大條件: 數據,計算資源,工程技能點很高的研究員(Jacob在微軟時候,就以單槍匹馬搭大系統,而中外聞名)。
-
編碼器
+關注
關注
45文章
3638瀏覽量
134427 -
nlp
+關注
關注
1文章
488瀏覽量
22033
原文標題:NLP歷史突破!谷歌BERT模型狂破11項紀錄,全面超越人類!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
圖解2018年領先的兩大NLP模型:BERT和ELMo
解析:華為石墨烯電池的重大突破真的是在超級快充技術領域嗎?
NLP的介紹和如何利用機器學習進行NLP以及三種NLP技術的詳細介紹

用圖解的方式,生動易懂地講解了BERT和ELMo等模型
詳解谷歌最強NLP模型BERT

史上最強通用NLP模型誕生
NLP 2019 Highlights 給NLP從業者的一個參考
2021 OPPO開發者大會:NLP預訓練大模型
NLP入門之Bert的前世今生






 工商網監
工商網監
評論