


現在電商行業勢頭正好,對在線零售商來說,他們不受庫存或空間的限制,而實體店則必須在有限的空間中存儲產品。
但是,在線購物也有它的局限之處,最大的難題之一就是檢驗產品的真偽。它的質量是否如宣傳所說的那么好?消費者留言的評價是真實的嗎還是虛假宣傳?這是消費者決定購買的重要因素。
所以,我們決定用NLP技術在這一主題中進行探索,本文將幫助你了解用主題建模分析在線產品評論的重要性。
商品評論的重要性
前幾天,我從某網站買了一部智能手機,價格符合我的預期,并且評分為4.5分(滿分為5)。
但是,拿到手之后我才發現,電池續航遠不及平均水平。在購買時我只看了評分,卻沒關注評論,所以我知道肯定不只我一個人不滿意!
所以網購看評論應該是必不可少的參考,可以,如果評論有成百上千條,根本看不過來怎么辦?這就需要用到自然語言處理技術了。
明確問題
我們應該如何用NLP分析大量商品評論呢?首先讓我們明確這一問題。
從賣家角度,他們可以從評論中估計顧客對商品的反應。想從大量評論中找到關鍵信息,這樣的智能系統需要做到兩點:
能讓顧客從中迅速提取出關鍵主題
賣家也能通過這些主題獲得用戶反饋
為了解決這一任務,我們將在亞馬遜的汽車評論數據上使用主題建模(LDA),數據集可以在這個地址中下載:snap.stanford.edu/data/amazon/productGraph/categoryFiles/reviewsAutomotive5.json.gz。
為什么用主題建模
和這項技術的名稱一樣,主題建模是自動確定文本目標中主題的過程,同時從文本語料中展示隱藏語義。主題模型有多重用途,包括:
文件聚合
組織大型文本數據
從未被組織的文本中進行信息檢索
特征選擇
一個好的主題模型,如果在與股票市場相關的文本上訓練時,應該會生成類似“出價”、“買賣”、“分紅”、“交易”等主題。下圖展示了一個典型的主題模型工作的流程:
在我們的案例中,文本數據來自“汽車”類目下的商品評論。這里,我們的目標是從評論中提取一些重要的有代表性的單詞。這些關鍵詞可以幫助我們了解某位顧客的態度。
Python實現
在這一部分,我們會用到Jupyter Notebook(或你在Python下使用的任意IDE)。這里我們會用到“隱含狄利克雷分布(LDA)”的概念,如果對這一概念不了解的讀者,可以參考這一博文:www.cnblogs.com/huangshiyu13/p/6148217.html
首先我們要下載所需的庫:
import nltk
from nltk importFreqDist
nltk.download('stopwords') # run this one time
import pandas as pd
pd.set_option("display.max_colwidth", 200)
import numpy as np
import re
import spacy
import gensim
from gensim import corpora
# libraries for visualization
import pyLDAvis
import pyLDAvis.gensim
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
要導入數據,首先要將數據提取到你的工作類別中,然后使用pandas中的read_json( )函數在pandas的數據框架中讀取。
df = pd.read_json('Automotive_5.json', lines=True)
df.head()
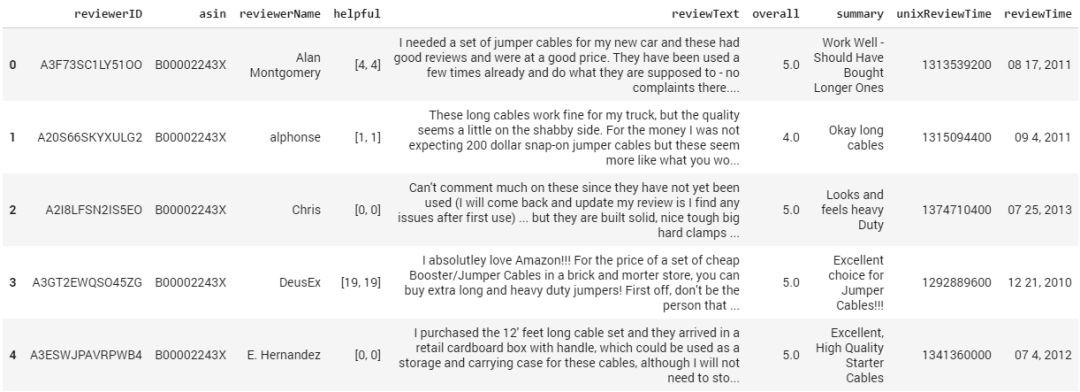
如你所見,數據包含以下類目:
評論者的ID
產品ID
評論者的用戶名
該評論的有用性
評論文本
產品評分
評論總結
評論執行時間
評論原始時間(raw)
在這篇文章中,我們只使用“評論文本”這一類。
數據處理
在開始文本挖掘前,數據處理和清洗是很重要的一步。在這一步中,我們會刪除標點、停止詞等,讓評論的形式盡可能統一。處理好之后,就可以檢查數據中最常出現的詞語了。所以,讓我們在這里定義一個函數,可以通過條形圖展示數據中最常見的n個詞語。
# function to plot most frequent terms
def freq_words(x, terms = 30):
all_words = ' '.join([text for text in x])
all_words = all_words.split()
fdist = FreqDist(all_words)
words_df = pd.DataFrame({'word':list(fdist.keys()), 'count':list(fdist.values())})
# selecting top 20 most frequent words
d = words_df.nlargest(columns="count", n = terms)
plt.figure(figsize=(20,5))
ax = sns.barplot(data=d, x= "word", y = "count")
ax.set(ylabel = 'Count')
plt.show()
函數定義如下。
freq_words(df['reviewText'])
如圖,最常見的詞語是“the”、“and”、“to”等等,這些詞對我們并沒有什么幫助,所以也要刪除這些詞語。在這之前,讓我們先刪除標點和數字。
# remove unwanted characters, numbers and symbols
df['reviewText'] = df['reviewText'].str.replace("[^a-zA-Z#]", " ")
接著刪除停止詞和少于兩個字母的單詞:
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
# function to remove stopwords
def remove_stopwords(rev):
rev_new = " ".join([i for i in rev if i notin stop_words])
return rev_new
# remove short words (length < 3)
df['reviewText'] = df['reviewText'].apply(lambda x: ' '.join([w for w in x.split() if len(w)>2]))
# remove stopwords from the text
reviews = [remove_stopwords(r.split()) for r in df['reviewText']]
# make entire text lowercase
reviews = [r.lower() for r in reviews]
再對常出現的詞進行可視化:
freq_words(reviews, 35)
我們可以看出有了變化,像“電池”、“價格”、“產品”、“汽油”等與汽車較相關的詞語出現了。但是,仍然有一些中性詞存在,例如“the”、“this”、“much”、“they”等等。
為了進一步去除文本中的噪音,我們可以用spaCy庫中的詞形還原處理。它可以將詞語還原到原始形式,減少單詞的重復。
!python -m spacy download en # one time run
nlp = spacy.load('en', disable=['parser', 'ner'])
def lemmatization(texts, tags=['NOUN', 'ADJ']): # filter noun and adjective
output = []
for sent in texts:
doc = nlp(" ".join(sent))
output.append([token.lemma_ for token in doc if token.pos_ in tags])
return output
我們對評語進行符號化,然后對其進行詞形還原。
tokenized_reviews = pd.Series(reviews).apply(lambda x: x.split())
print(tokenized_reviews[1])
['these', 'long', 'cables', 'work', 'fine', 'truck', 'quality', 'seems', 'little', 'shabby',
'side', 'for', 'money', 'expecting', 'dollar', 'snap', 'jumper', 'cables', 'seem', 'like',
'would', 'see', 'chinese', 'knock', 'shop', 'like', 'harbor', 'freight', 'bucks']
reviews_2 = lemmatization(tokenized_reviews)
print(reviews_2[1]) # print lemmatized review
['long', 'cable', 'fine', 'truck', 'quality', 'little', 'shabby', 'side', 'money', 'dollar',
'jumper', 'cable', 'chinese', 'shop', 'harbor', 'freight', 'buck']
可以看到,這一過程并不僅僅還原了詞形,而且只留下了名詞和形容詞。之后,我們將這次詞語在變換成正常形式。
reviews_3 = []
for i in range(len(reviews_2)):
reviews_3.append(' '.join(reviews_2[i]))
df['reviews'] = reviews_3
freq_words(df['reviews'], 35)
這樣可以看出常見詞都是和汽車相關的,我們可以繼續搭建主題模型了。
搭建一個LDA模型
首先,我們要對語料創建術語詞典,其中每個唯一的詞語都被看做一個index
dictionary = corpora.Dictionary(reviews_2)
之后,我們要用創建好的詞典將評論轉化成文件術語矩陣。
doc_term_matrix = [dictionary.doc2bow(rev) for rev in reviews_2]
# Creating the object for LDA model using gensim library
LDA = gensim.models.ldamodel.LdaModel
# Build LDA model
lda_model = LDA(corpus=doc_term_matrix,
id2word=dictionary,
num_topics=7,
random_state=100,
chunksize=1000,
passes=50)
上述代碼的執行可能需要一段時間。注意,我在這一模型中,用num_topics參數將主題的數量定為7,你可以修改這一數字。
接著就可以生成LDA模型學習到的主題。
lda_model.print_topics()
[(0, '0.030*"car" + 0.026*"oil" + 0.020*"filter" + 0.018*"engine" + 0.016*"device" + 0.013*"code"
+ 0.012*"vehicle" + 0.011*"app" + 0.011*"change" + 0.008*"bosch"'),
(1, '0.017*"easy" + 0.014*"install" + 0.014*"door" + 0.013*"tape" + 0.013*"jeep" + 0.011*"front" +
0.011*"mat" + 0.010*"side" + 0.010*"headlight" + 0.008*"fit"'),
(2, '0.054*"blade" + 0.045*"wiper" + 0.019*"windshield" + 0.014*"rain" + 0.012*"snow" +
0.012*"good" + 0.011*"year" + 0.011*"old" + 0.011*"car" + 0.009*"time"'),
(3, '0.044*"car" + 0.024*"towel" + 0.020*"product" + 0.018*"clean" + 0.017*"good" + 0.016*"wax" +
0.014*"water" + 0.013*"use" + 0.011*"time" + 0.011*"wash"'),
(4, '0.051*"light" + 0.039*"battery" + 0.021*"bulb" + 0.019*"power" + 0.018*"car" + 0.014*"bright"
+ 0.013*"unit" + 0.011*"charger" + 0.010*"phone" + 0.010*"charge"'),
(5, '0.022*"tire" + 0.015*"hose" + 0.013*"use" + 0.012*"good" + 0.010*"easy" + 0.010*"pressure" +
0.009*"small" + 0.009*"trailer" + 0.008*"nice" + 0.008*"water"'),
(6, '0.048*"product" + 0.038*"good" + 0.027*"price" + 0.020*"great" + 0.020*"leather" +
0.019*"quality" + 0.010*"work" + 0.010*"review" + 0.009*"amazon" + 0.009*"worth"')]
Topic 3中含有“towel”、“clean”、“wax”、“water”等詞語,表明這一話題和汽車清潔有關。Topic 6含有“price”、“quality”和“worth”等詞語,說明和產品的價格有關。
主題可視化
為了在二維空間中對我們的主題進行可視化,我們用的是pyLDAvis庫。
# Visualize the topics
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim.prepare(lda_model, doc_term_matrix, dictionary)
vis
其他分析網站評論的方法
除了主題建模,還有很多其他的NLP方法可以用來分析理解網絡評論:
文本總結:對評語進行關鍵點總結。
實體識別(entity recognition):從評論中提取出實體,分析哪種產品更受歡迎。
確定流行趨勢:根據評論的時間,可以掌握某一商品的受歡迎趨勢。
語義分析:對零售商來說,理解評論的語義情感對改善產品和服務是非常有幫助的。
下一步工作
信息檢索讓我們省去了瀏覽大量評論的時間,也讓我們知道了顧客對產品說了些什么。但是,它并沒有展示出評論是積極的、中立的、還是消極的。這就是信息檢索之后要做的工作。我們不僅要提取出話題,還要分析其中的情感。在接下來的文章中我們會具體講解,請大家關注。
-
數據集
+關注
關注
4文章
1224瀏覽量
25495 -
電商
+關注
關注
1文章
469瀏覽量
29199
原文標題:NLP實戰:用主題建模分析網購評論(附Python代碼)
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
失效分析的重要性
UPS的重要性
基于CD-RBM深度學習的產品評論情感分析
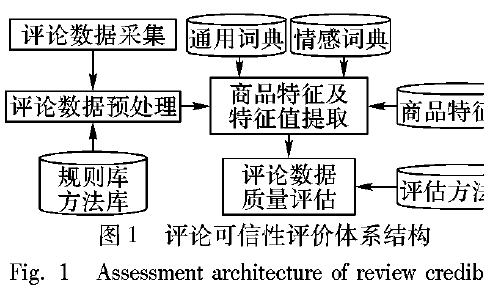
在線商品評論可信性的評價方法詳細資料說明
在線商品評論的可信程度如何使用大數據技術分析
怎么樣實現電商平臺商品評論可信性的自動評估
預測產品在線評論有用程度的模型
基于規則的商品評論搭配抽取方法

Python如何進行特征重要性分析

Python中進行特征重要性分析的9個常用方法
產品評論獲取API接口






 工商網監
工商網監

評論