

前幾天,谷歌AI團隊發布了一款新的語言表征模型——BERT,是來自Transformer的雙向編碼器表征。它的效果很強大,在11項NLP任務中都刷新了最佳成績。
https://arxiv.org/abs/1810.04805
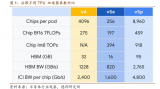
在計算力方面,關于BERT選擇TPU還是GPU仍然存在爭議。BERT用了四天時間,在4個TPU pod上完成的(共有256個TPU芯片),這是否意味著只有谷歌才能訓練像BERT這樣的模型呢?難道GPU已經走到盡頭了嗎?這里需要明確兩點基礎知識:
一臺TPU是一個矩陣乘法單元,它僅可以進行矩陣乘法和矩陣操作。在計算矩陣乘法時,它的速度很快。
進行矩陣乘法的過程中,最慢的部分就是從主記憶體中得到元素,并將其載入處理器中。
換句話說,矩陣相乘中,最燒錢的部分是內存負載。對BERT來說,矩陣相乘應該占計算負載的90%。了解了這些背景,我們可以對這一問題進行小小的技術分析。
TPU和GPU的帶寬模型
TPU上的Transformer
BERT中常見的操作是矩陣乘法:AB=C,其中A的尺寸為256×256,B為1024×1024。TPU在對矩陣執行相乘的過程中,會將矩陣分解成更小的128×128矩陣。這就意味著我們需要對A加載16個128×128的tile,從B中加載64個tile。總共就是1664=1024個128×128的負載量。在16位的條件下,這就是32MB的數據。
現在我們進一步簡化它。我們假設,在進行兩個記憶負載時沒有延遲時間,這也是有可能的,因為通常你可以在線程并行下隱藏內存訪問延遲。簡單地說,這意味著,當我們等待一個128×128的矩陣副本完成時,已經完成了下一個。這樣一來,我們只需要等待第一個內存副本的完成,不用等待其他的。這就是GPU速度快的核心原因,以及為什么我們要在GPU中使用多個線程,無延遲的重疊內存傳輸與實際情況相差無幾。使用了這種簡化,我們現在可以直接使用內存帶寬計算為矩陣乘法加載內存所需要的時間。如果我們查看TPU的帶寬,就會放發現有600GB/s,所以我們需要5.2e-05秒來傳輸32MB的數據。
GPU上的Transformer
對于GPU,過程相同,只不過使用更小的tile和更多處理器。和TPU相似,我們同時使用兩個負載來隱藏內存延遲。對GPU來說,16位數據的tile尺寸是96×96的。如果我們用一個V100 Tesla GPU,那么需要同時運行160個tile,還會有稍許延遲。與TPU相比,這意味著,和兩個能處理128×128的矩陣的單元不同,GPU有160個單元(80個SM,160個線程塊,每個線程塊有兩個96×96的矩陣)。這也能保證我們可以通過并行隱藏內存延遲。
重復以上計算過程,可以得到下面的結果:
對矩陣A,我們有33個96×96的tile;對矩陣B,我們有121個96×96的tile。總共需要33*121=3993次負載,數據總量為70MB。V100每秒運行速度為900GB,所以內存負載可能會花7.6r-05秒。所以,我們的模型判斷,在這一場景下,一臺GPU比一臺TPU慢32% 。注意,對一臺RTX 2080 Ti GPU來說,矩陣tile是一樣的,但是內存帶寬減少到了616GB/s,說明RTX 2080 Ti比TPU慢了54%。
注意,可用Tensor Core的TPU和GPU都能在一次運行中分別計算矩陣乘法tile,所以,就速度來說二者是差不多的,區別就在于內存是如何被載入的。
在GPU上BERT的訓練時間
利用這一數據,用V100和RTX 2080 Ti構成的GPU群組,以及高速網絡和好的并行算法(例如用微軟的CNTK),我們能在64臺GPU上(相當于四個TPU pod)、用5天多的時間或8天半的時間訓練出BERT。在有八臺GPU的設備上,使用任意軟件和并行算法(PyTorch或者TensorFlow),我們訓練BERT需要42天或者68天。對于標準的四個GPU的臺式機,我們需要99天。
帶寬模型的限制
帶寬模型最大的限制就是這些計算是針對特定矩陣大小的,計算的難度在各種尺寸之間都不同。例如,如果你的batch size是128,那么GPU的速度會比TPU稍快一點。如果batch size小于128,GPU的速度就會快很多。增加矩陣B的尺寸會讓TPU比GPU快得多。在BERT的原始論文中,研究人員是針對TPU進行矩陣尺寸的調整,如果你用GPU訓練的話就不要參考了。
未來可能遇到的限制包括融合運算,TPU可以計算額外的操作,例如非線性激活函數或矩陣乘法中的偏差。這意味著,TPU不需要從較慢的全局內存中進行加載。另外,GPU也支持這種操作,但是英偉達還未將它們實現,所以GPU用戶可能無法使用這一方法。所以,用戶可能會遇到1.6%的速度變慢,例如,如果你應用一個非線性函數和一個偏見,那么TPU可能會比GPU快3.2%。
32位、16位和8位的區別
如果在32位情況下重復上面的計算過程,那么TPU會比之前快5.3倍。所以數據類型的尺寸在TPU和GPU的選擇上還是很重要的。
TPU不支持8位訓練,但是圖靈GPU可以。所以,我們也可以看看8位矩陣乘法會有怎樣的表現。我此前總結了8位模型的表現,發現并不難訓練。如果我們重復上面的訓練,用8位GPU訓練,就會發現GPU比TPU快了3倍。在四臺RTX 2080 Ti上的8位訓練需要21天。
結語
TPU在訓練類似BERT的模型時,比GPU快32%到54%。你也可以用40到70天的時間,在八臺GPU上復現BERT。而用四臺普通GPU,在16位的情況下訓練出BERT需要99天,在8位情況下則需要21天。
-
編碼器
+關注
關注
45文章
3754瀏覽量
136706 -
gpu
+關注
關注
28文章
4888瀏覽量
130455
原文標題:面向BERT的TPUs和GPUs性能分析比較
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
一文理清CPU、GPU和TPU的關系
從CPU、GPU再到TPU,Google的AI芯片是如何一步步進化過來的?
CORAL-EDGE-TPU:珊瑚開發板TPU
TPU透明副牌.TPU副牌料.TPU抽粒廠.TPU塑膠副牌.TPU再生料.TPU低溫料
供應TPU抽粒工廠.TPU再生工廠.TPU聚醚料.TPU聚酯料.TPU副牌透明.TPU副牌.TPU中低溫料
CPU,GPU,TPU,NPU都是什么
MCU、DSP、GPU、MPU、CPU、DPU、FPGA、ASIC、SOC、ECU、NPU、TPU、VPU、APU、BPU、ECU、FPU、EPU、這些主控異同點有哪些?
一文了解CPU、GPU和TPU的區別
一文搞懂 CPU、GPU 和 TPU
如何利用Google Colab的云TPU加速Keras模型訓練
CPU和GPU與TPU是如何工作的到底有什么區別
谷歌發布多模態Gemini大模型及新一代TPU系統Cloud TPU v5p
Groq推出大模型推理芯片 超越了傳統GPU和谷歌TPU





 工商網監
工商網監

評論