

【導(dǎo)讀】TensorFlow.js 的發(fā)布可以說是 JS 社區(qū)開發(fā)者的福音!但是在瀏覽器中訓(xùn)練一些模型還是會(huì)存在一些問題與不同,如何可以讓訓(xùn)練效果更好?本文的作者,是一位前端工程師,經(jīng)過自己不斷的經(jīng)驗(yàn)積累,為大家總結(jié)了 18 個(gè) Tips,希望可以幫助大家訓(xùn)練出更好的模型。
TensorFlow.js 發(fā)布之后我就把之前訓(xùn)練的目標(biāo)/人臉檢測(cè)和人臉識(shí)別的模型往 TensorFlow.js 里導(dǎo),我發(fā)現(xiàn)有些模型在瀏覽器里運(yùn)行的效果還相當(dāng)不錯(cuò)。感覺 TensorFlow.js 讓我們搞前端的也潮了一把。
雖說瀏覽器也能跑深度學(xué)習(xí)模型了,這些模型終歸不是為在瀏覽器里運(yùn)行設(shè)計(jì)的,所以很多限制和挑戰(zhàn)也就隨之而來了。就拿目標(biāo)檢測(cè)來說,不說實(shí)時(shí)檢測(cè),就是維持一定的幀率恐怕都很困難。更別提動(dòng)輒上百兆的模型給用戶瀏覽器和帶寬(手機(jī)端的話)帶來的壓力了。
不過只要我們遵循一定的原則,用卷積神經(jīng)網(wǎng)絡(luò) CNN 和 TensorFlow.js 在瀏覽器里訓(xùn)練個(gè)像樣的深度學(xué)習(xí)模型并非癡人說夢(mèng)。從下面圖里可以看到,我訓(xùn)練的這幾個(gè)模型大小都控制在了 2 MB 以下,最小的才 3 KB。
大家可能心中會(huì)有個(gè)疑問:你腦殘嗎?要用瀏覽器訓(xùn)練模型?對(duì),用自己電腦、服務(wù)器、集群或者云來訓(xùn)練深度學(xué)習(xí)模型肯定是一條正道,但并非人人都有錢用NVIDIA GTX 1080 Ti 或者Titan X(尤其是顯卡集體大漲價(jià)之后)。這時(shí),在瀏覽器中訓(xùn)練深度學(xué)習(xí)模型的優(yōu)勢(shì)就體現(xiàn)出來了,有了 WebGL 和 TensorFLow.js 我用電腦上的 AMD GPU 也能很方便地訓(xùn)練深度學(xué)習(xí)模型。
對(duì)目標(biāo)識(shí)別問題,為了穩(wěn)妥起見通常都會(huì)建議大家用一些現(xiàn)成的架構(gòu)比如YOLO、SSD、殘差網(wǎng)絡(luò) ResNet 或 MobileNet ,但我個(gè)人認(rèn)為如果完全照搬的話,在瀏覽器上訓(xùn)練效果肯定是不好的。在瀏覽器上訓(xùn)練就要求模型要小、要快、要越容易訓(xùn)練越好。下面我們就從模型架構(gòu)、訓(xùn)練和調(diào)試等幾個(gè)方面來看看如何才能做到這三點(diǎn)。
模型架構(gòu)
▌1. 控制模型大小
控制模型的規(guī)模很重要。如果模型架構(gòu)太大太復(fù)雜,訓(xùn)練和運(yùn)行的速度都會(huì)降低,從瀏覽器載入模型度速度也會(huì)變慢。控制模型的規(guī)模說起來簡(jiǎn)單,難的是取得準(zhǔn)確率和模型規(guī)模之間的平衡。如果準(zhǔn)確率達(dá)不到要求,模型再小也是廢物。
▌2. 使用深度可分離卷積操作
與標(biāo)準(zhǔn)卷積操作不同,深度可分離卷積先對(duì)每個(gè)通道進(jìn)行卷積操作,之后再進(jìn)行1X1跨通道卷積。這樣做的好處是可以大大減小參數(shù)個(gè)數(shù),所以模型運(yùn)行速度會(huì)有很大提升,資源的消耗和訓(xùn)練速度也會(huì)有所提升。深度可分離卷積操作的過程如下圖所示:
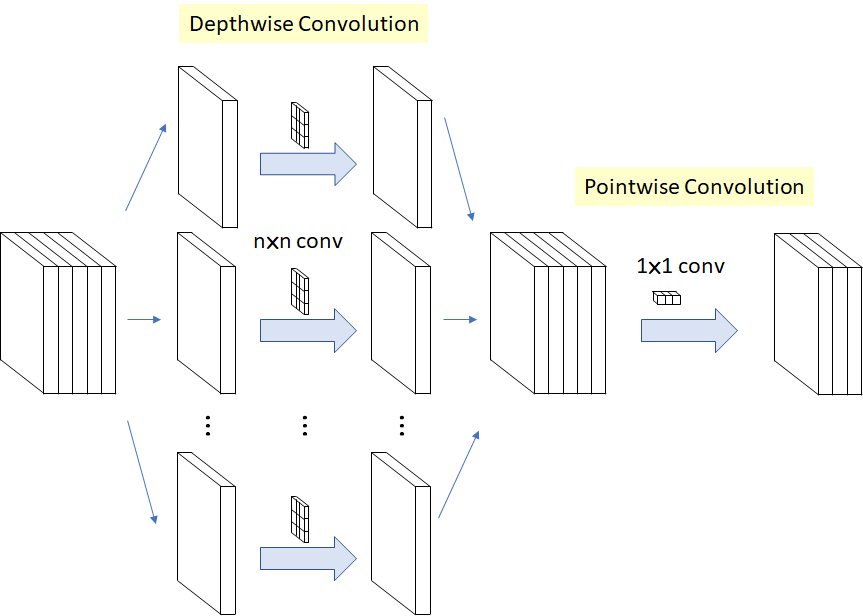
MobileNet 和 Xception 都使用了深度可分離卷積,TensorFlow.js 版本的 MobileNet 和 PoseNet 中你也能見到深度可分離卷積的身影。雖然深度可分離卷積對(duì)模型準(zhǔn)確率的影響還有爭(zhēng)議,但從我個(gè)人的經(jīng)驗(yàn)來看在瀏覽器里訓(xùn)練模型用它肯定沒錯(cuò)。
第一層我推薦用標(biāo)準(zhǔn)的 conv2d 操作來保持提取完特征的通道之間的關(guān)系。因?yàn)榈谝粚右话銋?shù)不多,所以對(duì)性能的影響不大。
其他卷積層就可以都用深度可分離卷積了。比如這里我們就使用了兩個(gè)過濾器。
這里 tf.separableConv2d 使用的卷積核結(jié)構(gòu)分別是[3,3,32,1]和[1,1,32,64]。
▌3.運(yùn)用跳躍連接和密集塊
隨著網(wǎng)絡(luò)層數(shù)的增加,梯度消失問題出現(xiàn)的可能性也會(huì)增大。梯度消失會(huì)造成損失函數(shù)下降太慢訓(xùn)練時(shí)間超長(zhǎng)或者干脆失敗。ResNet 和 DenseNet 中采用的跳躍連接則能避免這一問題。簡(jiǎn)單說來跳躍連接就是把某些層的輸出跳過激活函數(shù)直接傳給網(wǎng)絡(luò)深處的隱藏層作為輸入,如下圖所示:
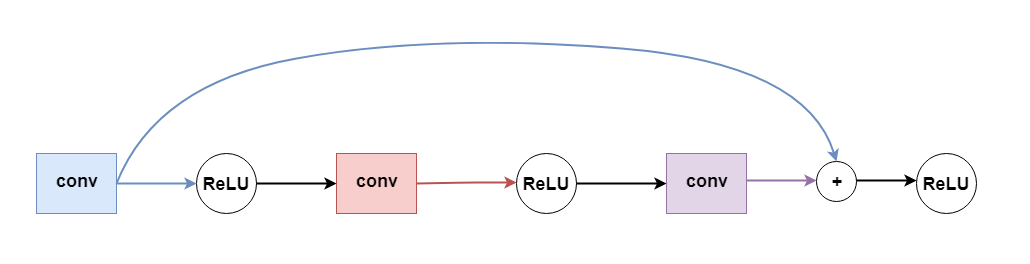
這樣就避免了因?yàn)榧せ詈瘮?shù)和鏈?zhǔn)角髮?dǎo)造成的梯度消失問題,我們也能根據(jù)需求增加網(wǎng)絡(luò)的層數(shù)了。
顯然跳躍連接隱含的一個(gè)要求就是連接的兩層輸出和輸入的格式必須能對(duì)應(yīng)得上。我們要用殘差網(wǎng)絡(luò)的話,那最好保證兩層的過濾器數(shù)目和填充都一致而且步幅為1(不過肯定有其它做法來保證格式對(duì)應(yīng))。
一開始我模仿殘差網(wǎng)絡(luò)的思路隔一層加一個(gè)跳躍連接(如下圖)。不過我發(fā)現(xiàn)密集塊效果更好,模型收斂的速度比加跳躍連接快得多。
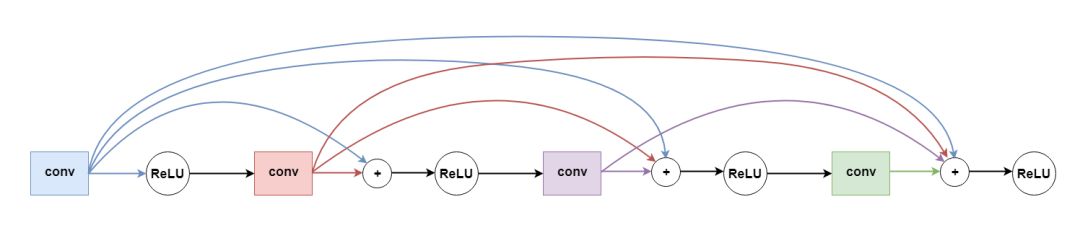
下面我們就來看看具體的代碼,這里的密集塊有四個(gè)深度可分離卷積層,其中第一層我把步幅設(shè)為 2 來改變輸入的大小。
▌4.激活函數(shù)選ReLU
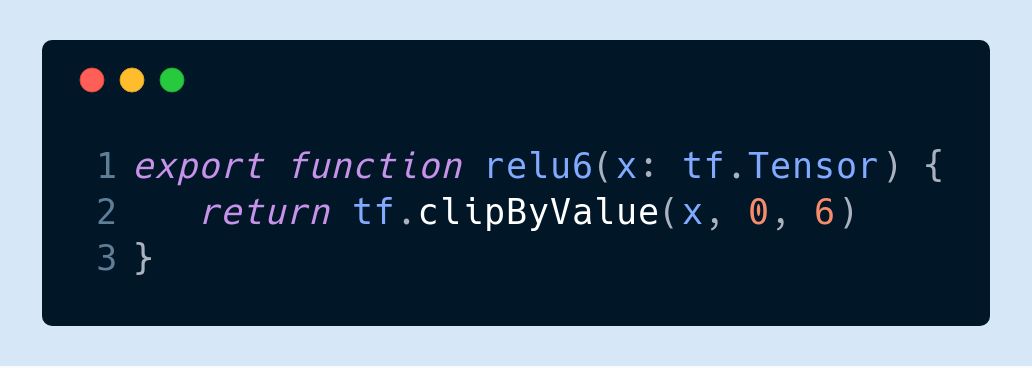
在瀏覽器里訓(xùn)練深度網(wǎng)絡(luò)的話激活函數(shù)不用看直接選 ReLU 就行了,主要原因還是梯度消失。不過大家可以試試 ReLU 的不同變種,比如
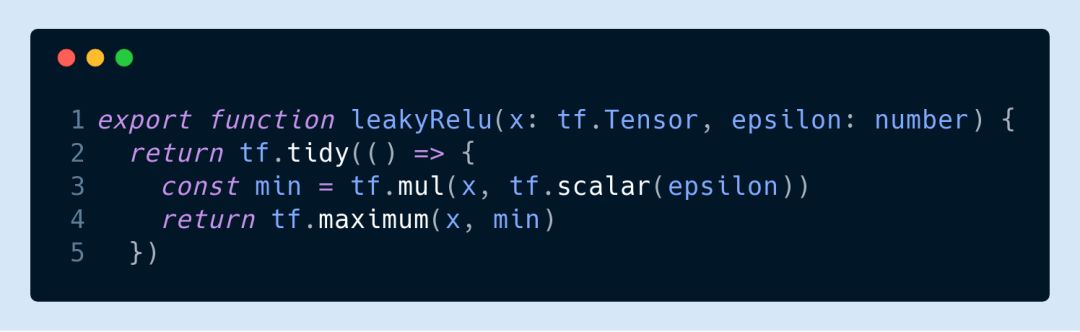
和 MobileNet 用的 ReLU-6 (y = min(max(x, 0), 6)):
訓(xùn)練過程
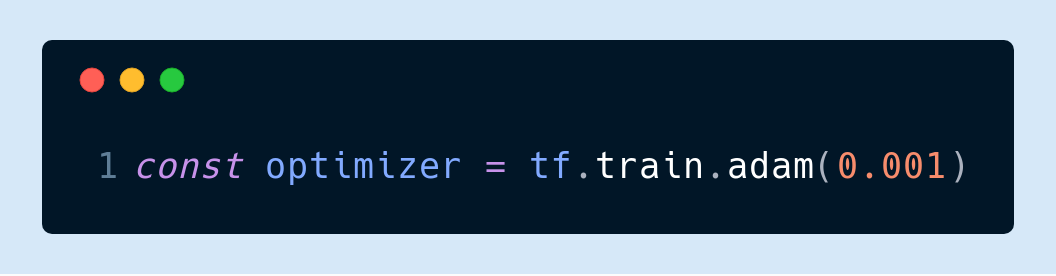
▌5.優(yōu)化器選Adam
這也是我個(gè)人的經(jīng)驗(yàn)只談。之前用 SGD 經(jīng)常會(huì)卡在局部極小值或者出現(xiàn)梯度爆炸。我推薦大家一開始把學(xué)習(xí)速率設(shè)為 0.001 然后其他參數(shù)都用默認(rèn):
▌6.動(dòng)態(tài)調(diào)整學(xué)習(xí)速率
一般來說當(dāng)損失函數(shù)不再下降的時(shí)候我們就該停止訓(xùn)練了,因?yàn)樵儆?xùn)練就過擬合了。不過如果我們發(fā)現(xiàn)損失函數(shù)出現(xiàn)上下震蕩的情況,則可能通過減小學(xué)習(xí)速率讓損失函數(shù)變得更小。
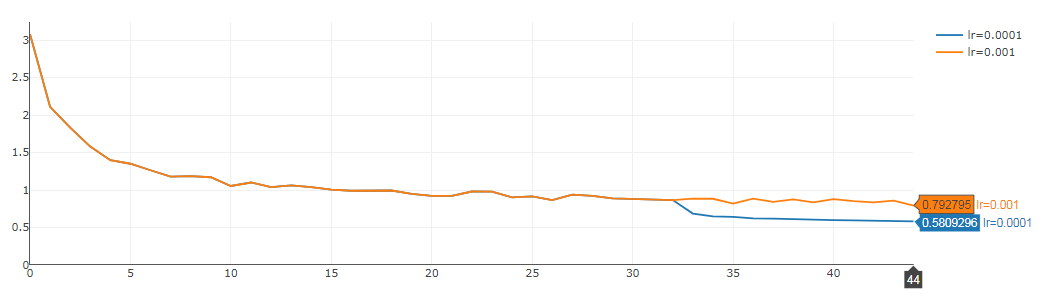
下面這個(gè)例子中我們可以看到學(xué)習(xí)速率一開始設(shè)的是 0.01,然后從 32 期開始出現(xiàn)震蕩(黃線)。這里通過將學(xué)習(xí)速率改為 0.001(藍(lán)線)使損失函數(shù)又減小了大概 0.3。
▌7.權(quán)重初始化原則
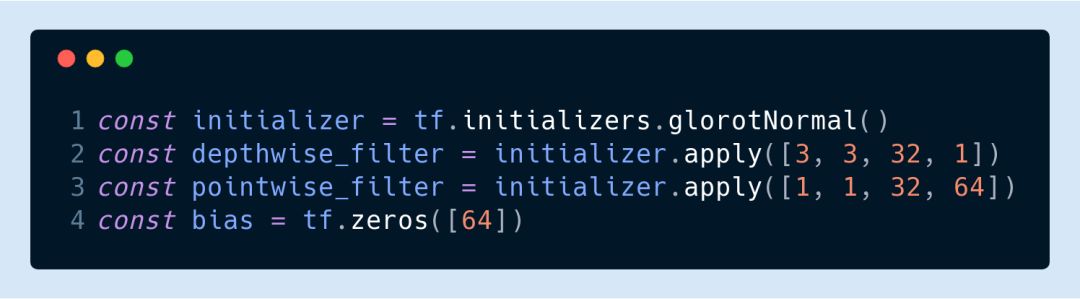
我個(gè)人喜歡把偏置量設(shè)為 0,權(quán)重則用傳統(tǒng)的正態(tài)分布。我一般用的是 Glorot 正態(tài)分布初始化法:
▌8.把數(shù)據(jù)集順序打亂
老生常談了。TensorFlow.js 中我們可以用 tf.utils.shuffle 來實(shí)現(xiàn)。

▌9. 保存模型
js 可以通過 FileSaver.js 來實(shí)現(xiàn)模型的存儲(chǔ)(或者叫下載)。比如下面的代碼就可以把模型所有的權(quán)重保存起來:

保存成什么格式是自己定的,但 FileSaver.js 只管存,所以這里要用JSON.strinfify 把 Blob 轉(zhuǎn)成字符串:

調(diào)試
▌10.保證預(yù)處理和后處理的正確性
雖然是句廢話但“垃圾數(shù)據(jù)垃圾結(jié)果”實(shí)在是至理名言。標(biāo)記要標(biāo)對(duì),每層的輸入輸出也要前后一致。尤其是對(duì)圖片做過一些預(yù)處理和后處理的話更要仔細(xì),有時(shí)候這些小問題還比較難發(fā)現(xiàn)。所以雖然費(fèi)些功夫但磨刀不誤砍柴工。
▌11.自定義損失函數(shù)
TensorFlow.js 提供了很多現(xiàn)成的損失函數(shù)給大家用,而且一般說來也夠用了,所以我不太建議大家自己寫。如果實(shí)在要自己寫的話,請(qǐng)一定注意先測(cè)試測(cè)試。
▌12.在數(shù)據(jù)子集試試過擬合
我建議大家模型定義好之后先挑個(gè)十幾二十張圖試試看損失函數(shù)有沒有收斂。最好能把結(jié)果可視化一下,這樣就能很明顯地看出這個(gè)模型有沒有成功的潛質(zhì)。
這樣做我們也能早早地發(fā)現(xiàn)模型和預(yù)處理時(shí)的一些低級(jí)錯(cuò)誤。這其實(shí)也就是 11 條里說的測(cè)試測(cè)試損失函數(shù)。
性能
▌13.內(nèi)存泄漏
不知道大家知不知道 TensorFlow.js 不會(huì)自動(dòng)幫你進(jìn)行垃圾回收。張量所占的內(nèi)存必須自己手動(dòng)調(diào)用 tensor.dispose() 來釋放。如果忘記回收的話內(nèi)存泄漏是早晚的事。
判斷有沒有內(nèi)存泄漏很容易。大家把 tf.memory() 每次迭代都輸出來看看張量的個(gè)數(shù)。如果沒有一直增加那說明沒泄漏。

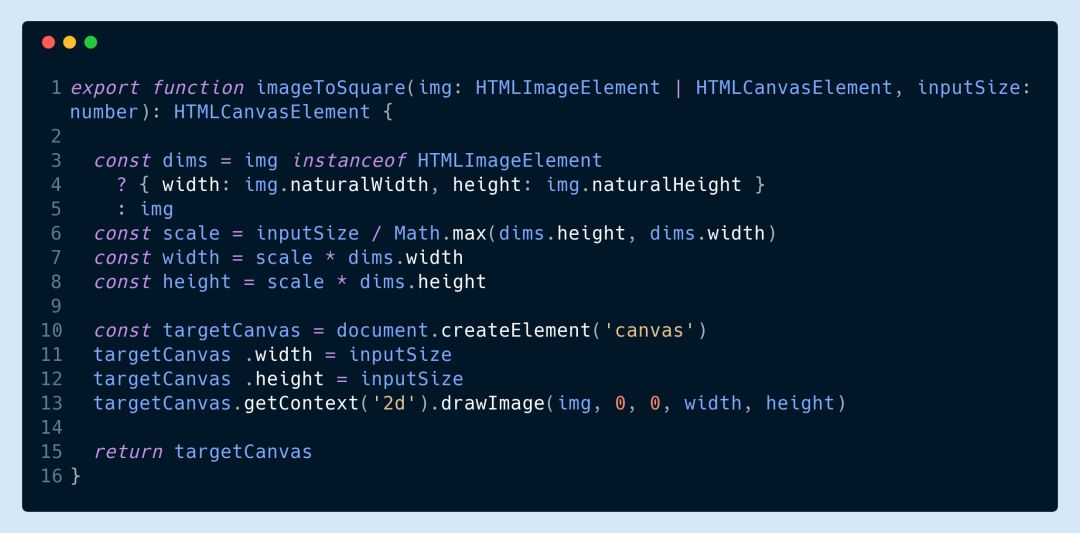
▌14.調(diào)整畫布大小,而不是張量大小
在調(diào)用 TF . from pixels 之前,要將畫布轉(zhuǎn)換成張量,請(qǐng)調(diào)整畫布的大小,否則你會(huì)很快耗盡 GPU 內(nèi)存。
如果你的訓(xùn)練圖像大小都一樣,這將不會(huì)是一個(gè)問題,但是如果你必須明確地調(diào)整它們的大小,你可以參考下面的代碼。(注意,以下語句僅在 tfjs - core 的當(dāng)前狀態(tài)下有效,我當(dāng)前正在使用 tfjs - core 版本 0.12.14)
▌15.慎選批大小
每一批的樣本數(shù)選多少,也就是批大小顯然取決于我們用的什么 GPU 和網(wǎng)絡(luò)結(jié)構(gòu),所以大家最好試試不同的批大小看看怎么最快。我一般從 1 開始試,而且有時(shí)候我發(fā)現(xiàn)增加批大小對(duì)訓(xùn)練的效率也沒啥幫助。
▌16.善用IndexedDB
我們訓(xùn)練的數(shù)據(jù)集因?yàn)槎际菆D片所以有時(shí)候還是挺大的。如果每次都下載的話肯定效率低,最好是用 IndexedDB 來存儲(chǔ)。IndexedDB 其實(shí)就是瀏覽器里嵌入的一個(gè)本地?cái)?shù)據(jù)庫,任何數(shù)據(jù)都能以鍵值對(duì)的形式進(jìn)行存儲(chǔ)。讀取和保存數(shù)據(jù)也只要幾行代碼就能搞定。
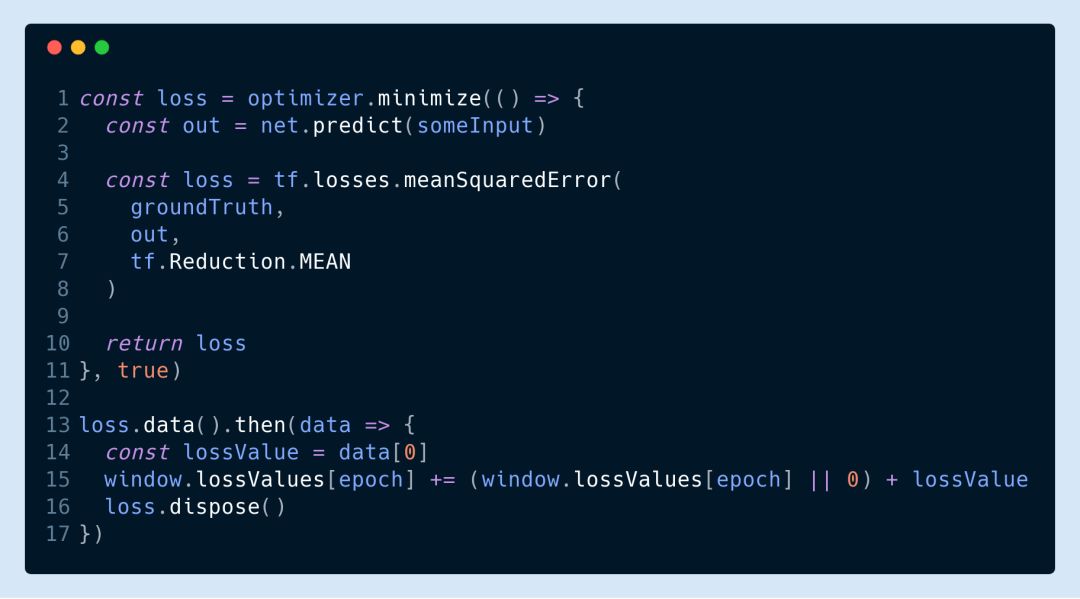
▌17.異步返回?fù)p失函數(shù)值
要實(shí)時(shí)監(jiān)測(cè)損失函數(shù)值的話可以用下面的代碼這來自己算然后異步返回:
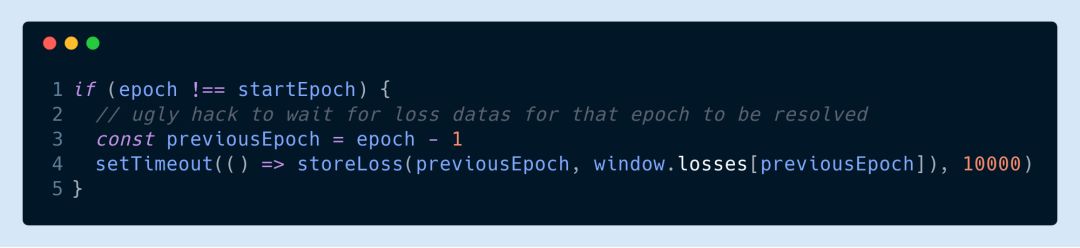
需要注意的是如果每期訓(xùn)練完要把損失函數(shù)值存到文件里的話這樣的代碼就有點(diǎn)問題了。因?yàn)楝F(xiàn)在損失函數(shù)的值是異步返回了所以我們得等最后一個(gè) promise 返回才能存。不過我一般都暴力地在一期結(jié)束之后直接等個(gè) 10 秒再存:
▌18.權(quán)重的量化
為了實(shí)現(xiàn)又小又快的目標(biāo),在模型訓(xùn)練完成之后我們應(yīng)該對(duì)權(quán)重進(jìn)行量化來壓縮模型。權(quán)重量化不光能減小模型的體積,對(duì)提高模型的速度也很有幫助,而且?guī)缀跞呛锰帥]壞處。這一步就讓模型又能小又能快,非常適合我們?cè)跒g覽器里訓(xùn)練深度學(xué)習(xí)模型。
在瀏覽器里訓(xùn)練深度學(xué)習(xí)模型的十八招(實(shí)際十七招)就總結(jié)到這里,希望大家讀了這篇文章能夠有所收獲。
如果有問題也歡迎在后臺(tái)給我們留言,大家一起討論!
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4811瀏覽量
103100 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122603
原文標(biāo)題:前端工程師掌握這18招,就能在瀏覽器里玩轉(zhuǎn)深度學(xué)習(xí)
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
AI語音識(shí)別-我給瀏覽器加了個(gè)語音搜索功能
11個(gè)你應(yīng)當(dāng)使用FIREFOX瀏覽器的理由
Web瀏覽器,Web瀏覽器是什么意思
使用WebBrower制作瀏覽器_Delphi教程
四大瀏覽器續(xù)航對(duì)決,結(jié)果Chrome瀏覽器完勝
基于JavaScript瀏覽器兼容性測(cè)試方法
瀏覽器怎么了 核心功能被弱化
區(qū)塊鏈瀏覽器可以查詢哪些信息
IE瀏覽器正式退役,由Edge瀏覽器來接任它的工作
瀏覽器支持javascript怎么設(shè)置
瀏覽器需要支持javascript怎么解決
寫一個(gè)Chrome瀏覽器插件





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論