 AI智能體學習如何跑步、躲避跨越障礙物
AI智能體學習如何跑步、躲避跨越障礙物
近年來,深度學習受到全球關注。成就最為突出的便是深度強化學習,例如Alpha Go等。本文作者Artem Oppermann基于此,對深度強化學習訓練AI智能體所需要的數學背景知識——馬爾科夫鏈做了深入淺出的介紹。
近年來,世界各地的研究員和媒體對深度學習極其關注。而深度學習方面成就最為突出的就是深度強化學習——從谷歌Alpha Go擊敗世界頂級棋手,到DeepMind的AI智能體自學走路、跑步以及躲避障礙物,如下圖所示:
圖2:AI智能體學習如何跑步、躲避跨越障礙物
圖3:AI智能體學習如何跑步、躲避跨越障礙物
還有一些AI智能體打破了自2014年以來人類玩家在雅達利游戲中的最高紀錄。
圖4:AI智能體學習如何玩兒雅達利游戲
而這一切最令人驚奇的是這些AI智能體中,沒有一個是由人類明確編程或者指導他們如何完成這些任務的。他們僅僅是通過深度學習和強化學習的力量在自學!
本文作者Artem Oppermann在Medium中開設了《自學AI智能體》的“連載”課程,本文是其第一篇文章,詳細介紹了AI智能體自學完成任務這一過程背后需要了解的數學知識——馬爾可夫鏈。
Nutshell中的深度強化學習
深度強化學習可以概括為構建一種算法(或AI智能體),直接從與環境的交互中學習。
圖5:深度強化學習示意圖
環境可以是真實世界,電腦游戲,模擬,甚至棋盤游戲,比如圍棋或象棋。就像人類一樣,人工智能代理人從其行為的結果中學習,而不是從明確的教導中學習。
在深度強化學習中,智能體是由神經網絡表示的。神經網絡直接與環境相互作用。它觀察環境的當前狀態,并根據當前狀態和過去的經驗決定采取何種行動(例如向左、向右移動等)。根據采取的行動,AI智能體收到一個獎勵(Reward)。獎勵的數量決定了在解決給定問題時采取的行動的質量(例如學習如何走路)。智能體的目標是學習在任何特定的情況下采取行動,使累積的獎勵隨時間最大化。
馬爾可夫決策過程
馬爾可夫決策過程(MDP)是一個離散時間隨機控制過程。
MDP是迄今為止我們對AI智能體的復雜環境建模的最佳方法。智能體要解決的每個問題都可以看作是S1、S2、S3、……Sn(狀態可以是圍棋/象棋的棋局配置)的序列。智能體采取行動并從一個狀態移動到另一個狀態。
馬爾可夫過程
馬爾可夫過程是一個描述可能狀態序列的隨機模型,其中當前狀態僅依賴于以前的狀態。這也被稱為馬爾科夫性質(公式1)。對于強化學習,這意味著AI智能體的下一個狀態只依賴于最后一個狀態,而不是之前的所有狀態。

公式1:馬爾可夫性質
馬爾可夫過程是一個隨機過程。這意味著從當前狀態s到下一個狀態s'的轉變“只能在一定概率下發生”(公式2)。在馬爾科夫過程中,一個被告知向左移動的智能體只會在一定概率下向左移動,例如0.998。在概率很小的情況下,由環境決定智能體的最終位置。

公式2:從狀態s到狀態s'的轉變概率
Pss '可以看作是狀態轉移矩陣P中的一個條目,它定義了從所有狀態s到所有后續狀態s'的轉移概率(公式3)。

公式3:轉移概率矩陣
馬爾可夫獎勵(Reward)過程
馬爾可夫獎勵過程是一個元組

公式4:在狀態s中期望獲得獎勵
總獎勵Gt(公式5),它是智能體在所有狀態序列中所獲得的預期累積獎勵。每個獎勵都由所謂的折扣因子γ∈[0,1]加權。

公式5:所有狀態的獎勵總額
價值函數(Value Function)
另一個重要的概念是價值函數v(s)中的一個。價值函數將一個值映射到每個狀態s。狀態s的值被定義為AI智能體在狀態s中開始其進程時將得到的預期總獎勵(公式6)。

公式6:價值函數,從狀態s開始的期望返回值
價值函數可以分解為兩個部分:
處于狀態s時,智能體收到的即使獎勵(immediate reward)R(t+1);
在狀態s之后的下一個狀態的折現值(discounted value)v(s(t+1));

公式7:價值函數的分解
貝爾曼方程
馬爾可夫獎勵過程的貝爾曼方程
分解后的值函數(公式8)也稱為馬爾可夫獎勵過程的貝爾曼方程。
該函數可以在節點圖中可視化(圖6),從狀態s開始,得到值v(s)。在狀態s中,我們有特定的概率Pss '到下一個狀態s'中結束。在這種特殊情況下,我們有兩個可能的下一個狀態為了獲得值v(s),我們必須總結由概率Pss'加權的可能的下一個狀態的值v(s'),并從狀態s中添加直接獎勵。 這就產生了公式9,如果我們在等式中執行期望算子E,那么這只不是公式8。

公式8:價值函數分解

圖6:從s到s'的隨機轉變

公式9:執行期望算子E后的貝爾曼方程
馬爾可夫決策過程——定義
馬爾可夫決策過程是一個有決策的馬爾可夫獎勵過程。
馬爾可夫決策過程是馬爾可夫獎勵過程的決策。 馬爾可夫決策過程由一組元組

公式10:期望獎勵取決于狀態s中的行為
策略
在這一點上,我們將討論智能體如何決定在特定狀態下必須采取哪些行動。 這由所謂的策略π(公式11)決定。 從數學角度講,策略是對給定狀態的所有行動的分配。 策略確定從狀態s到智能體必須采取的操作a的映射。

公式11:策略作為從s到a的一個映射
該策略導致狀態價值函數v(s)的新定義(公式12),我們現在將其定義為從狀態s開始的預期返回,然后遵循策略π。

公式12:狀態值函數
動作價值函數
除狀態值函數之外的另一個重要功能是所謂的動作值函數q(s,a)(公式13)。 動作值函數是我們通過從狀態s開始,采取行動a然后遵循策略π獲得的預期回報。 請注意,對于狀態s,q(s,a)可以采用多個值,因為智能體可以在狀態s中執行多個操作。 Q(s,a)的計算是通過神經網絡實現的。 給定狀態作為輸入,網絡計算該狀態下每個可能動作的質量作為標量(圖7)。 更高的質量意味著在給定目標方面采取更好的行動。

圖7:動作價值函數說明
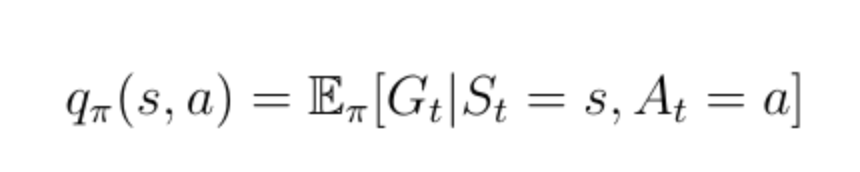
公式13:動作價值函數
狀態值函數v(s)可以分解為以下形式:

公式14:狀態價值函數分解
同樣的分解也適用于動作價值函數:

公式15:動作價值函數分解
在這一點上,我們討論v(s)和q(s,a)如何相互關聯。 這些函數之間的關系可以在圖中再次可視化:

圖8:v(s)和q(s,a)之間關系的可視化
在這個例子中,處于狀態s允許我們采取兩種可能的行動a,根據定義,在特定狀態下采取特定的行動給了我們動作值q(s,a)。價值函數v(s)是概率q(s,a)的和,由在狀態s中采取行動a的概率來賦予權重。

公式16:狀態值函數是動作值的加權和
現在讓我們考慮圖9中的相反情況。二叉樹的根現在是一個我們選擇采取特定動作的狀態。 請記住,馬爾可夫過程是隨機的。 采取行動并不意味著你將以100%的確定性結束你想要的目標。 嚴格地說,你必須考慮在采取行動后最終進入其他狀態的概率。 在采取行動后的這種特殊情況下,你可以最終處于兩個不同的下一個狀態s':

圖9:v(s)與q(s,a)關系的可視化
為了獲得動作值,你必須用概率加權的折現狀態值來最終得到所有可能的狀態(在本例中僅為2),并加上即時獎勵:
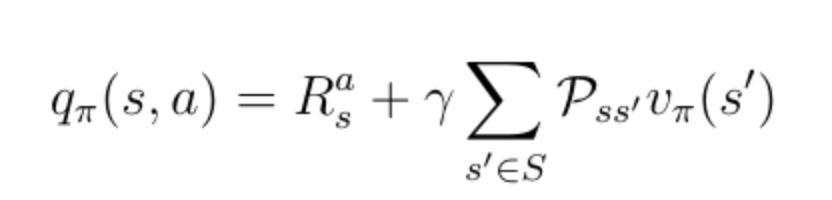
公式17:q(s,a)和v(s)之間的關系
既然我們知道了這些函數之間的關系,我們就可以將公式16中的v(s)插入公式17中的q(s,a)中。我們得到公式18,可以看出當前的q(s,a)和下一個動作值q(s,a)之間存在遞歸關系。

公式18:動作值函數的遞歸性質
這種遞歸關系可以再次在二叉樹中可視化(圖10)。
圖10:q(s,a)遞歸行為的可視化
-
智能體
+關注
關注
1文章
163瀏覽量
10604 -
強化學習
+關注
關注
4文章
268瀏覽量
11278
原文標題:AlphaGo等智能體是如何煉成的?你需要懂得馬爾科夫鏈
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論