 OpenAI的研究人員提出了一種全新的AI安全策略——迭代放大法
OpenAI的研究人員提出了一種全新的AI安全策略——迭代放大法
近日,OpenAI的研究人員提出了一種全新的AI安全策略——迭代放大法(iterated amplification),通過描述如何將一個復雜的任務分解成簡單的子任務而不是提供標簽數據或獎勵函數,實現了對于復雜行為和目標的描述。雖然這一方法還處于比較初級的階段,但研究人員認為這種方法將為AI安全提供一種大規模的實現手段。
如果我們想要訓練一個機器學習模型完成特定的任務,我們一定需要訓練信號來評價模型的表現并幫助模型不斷學習和改進。例如監督學習中的標簽和強化學習中的獎勵函數就是訓練訊號。機器學習體系中的一個重要假設就是這些訊號已經存在,并且算法可以按照它來學習。但實際情況是訓練信號可能來自于不知道的某個地方。如果我們沒有訓練信號就意味著我們沒有辦法學習。如果我們得到的是錯誤信號,那么算法可能會得到無意識的甚至危險的結果。所以對于新的任務和AI安全來說,提高得到訓練訊號的能力是十分必要且極具價值的。
那么讓我們看看目前是怎么獲取訓練信號的呢?有時候我們可以利用算法得到,比如在圍棋游戲中可以通過計數評分得到信號。不過大多數真實世界的任務并沒有一個數學形式表達的信號,但通常我們可以人工的手段來獲取訓練信號。但實際情況是,很多復雜的任務已經遠遠超過了人類的認知能力,我們沒辦法判斷模型的輸出是否正確,例如設計一個復雜的運輸系統或者管理龐大計算機網絡安全細節的管理系統這樣的任務,或者是預測全球長期氣候趨勢這種復雜的任務。
需要不同訓練信號的問題,訓練序號可以來自表達式評價、人類反饋,但有的任務超出了人類的能力。
本文提出的迭代放大,是一種在確定性假設下為后續任務生成訓練假設的方法。實際上,雖然人類不能在全局上直接把握復雜的問題,但我們可以假設人類可以有效的評估復雜任務中的一小塊任務是否符合要求。例如在計算機網絡安全的例子中,人們可以將“防御一系列針對于服務器和路由器的攻擊”分解為“針對服務器的攻擊”和“針對路由的攻擊”以及“兩個攻擊間可能的相關性”。此外,我們還可以假設,人類可以承擔很少的一部分任務,例如“識別出日志中的一行可疑記錄”。如果人類的分解任務能力和分擔任務能力得以落實,這兩項假設得以成立,那我們就可以為一項龐大的任務建立訓練信號,這些訊號來自于人類針對分解任務訊號的組合。
迭代放大的機制
研究人員在實際訓練放大的過程中,首先訓練AI系統從一個很小的子任務開始學習,通過尋求人類的幫助(標簽/獎勵信號)來學會解決這一子問題。隨后讓系統學習一個稍大的問題,這時候需要人類將較大的任務進行分解,AI系統依靠上一步的學習來解決這些問題。研究人員將這種解決方案用于那些稍微困難的問題,在這些問題中系統從人類處得到訓練信號,來直接訓練二級任務(此時無需人類幫助)。
隨著訓練的進行,研究人員繼續為AI提供更為復雜的復合任務,不斷構建出訓練信號。如果這個過程得以完成,AI系統將學會解決高度復雜的問題,盡管這個系統一開始沒有從任務中獲得直接的訓練信號。
這一過程在一定程度上與AlphaGo Zero專家迭代過程很像,不過個專家迭代在強化現存的訓練信號,而迭代放大則從零開始構建訓練信號。它也和最近的一些問題分解的算法很像,但區別在于它可以用于沒有先前訓練信號的問題。
實 驗
先前的實驗表明,直接用AI系統解決超越人類能力的問題十分困難,同時利用人類作為訓練信號也會引入復雜性。所以研究人員的第一個實驗在于嘗試放大了算法的訓練信號,來驗證這種方法可以在簡單任務的有效性。同時也限制了對于監督學習的注意力。研究人員在5個示例算法任務上進行了嘗試。這五個算法示例都有具體的數學表達,但研究人員先排除算法信號,了利用一步步從簡單到復雜的方法從零開始解決。利用迭代放大的方法,從一些不直接的子任務中間接學習出訓練信號。
在五個任務中(排列、序列賦值、通配符匹配、最短路徑、查找并集),新的方法可以與表達式方法獲得同等甚至更好的效果。
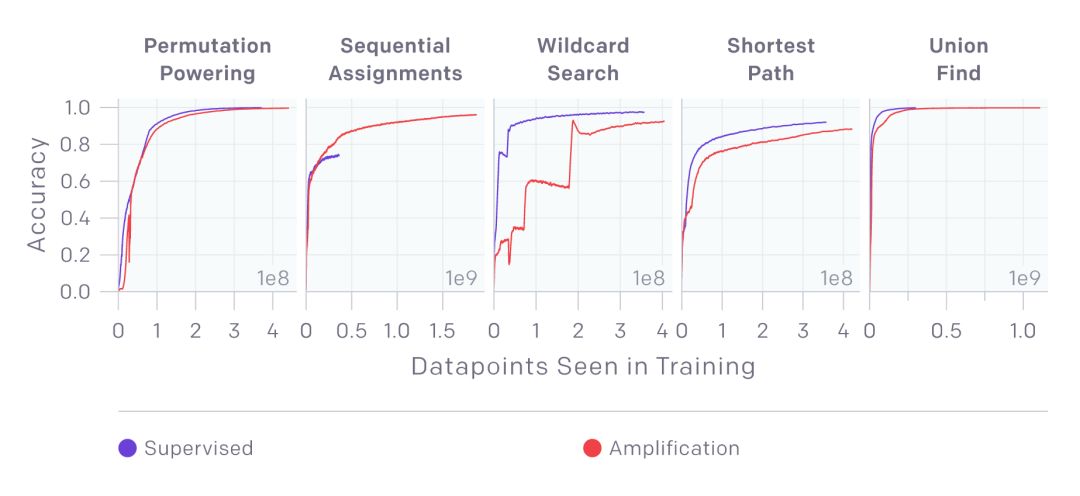
在沒有label的情況下迭代放大法獲得了與監督學習相同甚至更好的結果
放大法在尋求解決那些超越人類直接認知和能力的問題,通過迭代的過程使得人類可以提供間接的監督信號。這項工作同時也建立在人類反饋的基礎上,通過實現獎勵預測系統,接下來的版本將會包含來自于真實人類的反饋。目前研究人員僅僅在探索的初級階段,隨著研究的深入和規模的擴大將會為很多復雜的問題帶來新的可能。
人類反饋
-
AI
+關注
關注
87文章
30728瀏覽量
268886 -
函數
+關注
關注
3文章
4327瀏覽量
62573 -
機器學習
+關注
關注
66文章
8406瀏覽量
132563
原文標題:OpenAI提出全新AI安全策略—迭代放大法,助力機器實現復雜目標學習
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ZigBee接入EPA網絡的安全策略
一種參數自調節優化控制策略
一種參數自調節優化控制策略
基于多維整數空間的安全策略沖突檢測與消解
基于可信計算的多級安全策略TCBMLSP分析
研究人員提出了一種柔性可拉伸擴展的多功能集成傳感器陣列





 工商網監
工商網監
評論