 如何實現自動識別并提取圖片中的文本內容
如何實現自動識別并提取圖片中的文本內容
【導讀】提到 Dropbox,大家可能都知道這是一個文件同步、備份、共享的云存儲軟件。其實 Dropbox 可以實現的功能遠不止這些。今天就為大家介紹 Dropbox 一個非常強大又實用的功能——自動識別并提取圖片中的文本內容,包含 PDF 文檔中的圖片。比如,當用戶搜索其中某個文件中出現的一段文本時(英文文本),在搜索結果中就會顯示出這個文件。下面我們就為大家介紹這樣的功能是如何實現的。
前言
自動識別圖片中的文字功能有很多好處,最顯著的提升是能夠讓 Dropbox 用戶搜索從前無法搜索的內容。Dropbox 用戶上傳的圖片和 PDF 文檔總數已經超過了兩百億,這其中有超過百分之十的文件真正的內容都是文本,但格式是圖片,比如說手機拍攝的小票或者白板的照片。這些就是我們要進行文字識別的對象了。PDF 文件中有 25% 左右是文檔的掃描件,這些也屬于我們想實現自動文字識別的對象。
對用戶來說,文檔和文檔的掃描件好像差不太多,但對計算機來說區別可就大了。文檔可以進行索引并搜索,而圖片說白了只是一些像素點罷了。像 TXT、DOCX 和 html 格式的文件一般來說都可以進行索引,而像 JPEG、PNG 和 GIF 這些圖片格式一般來說是不能直接進行索引的。對 PDF 文件來說要分情況,比如 PDF 里的圖片也是不能夠索引的。圖像文本自動識別功能可以智能地區分所有的文檔和文檔中包含哪類數據。
分析
講如何實現之前我們先要對這個問題進行一些初步的分析,具體來說就是回答下面三個問題:
什么文件需要進行文字識別
如何判斷文件是否包含有文字
對于 PDF 文件是否所有頁都需要全部識別?識別多少是有用的?
需要進行識別的主要是當前沒有可用索引文本內容的文件,包括圖片格式和還有一部分 PDF 文檔,但其實這部分文件只占所有文件的很小一部分,所以解決這個問題很重要的一個步驟就是建立一個機器學習模型來判斷文件是否包含可識別的文字。比如說某文檔的照片我們就需要進行識別,但如果只是自拍拍到了衣服上的字,這時候識別恐怕就沒有什么意義了。這里我們使用了一個卷積神經網絡來進行二元分類。
我們經過統計發現 JPEG 這一最常見的圖片格式中有大約 9% 可能包含文字。PDF 文件的每一頁則可能屬于下面三種情形之一:
非圖片,只有可索引的文字
含有文字的圖片
完全沒有文字內容的圖片
這三類中我們感興趣的其實只有第二類。我們發現第二類情況在三種情況之中約占 28%。PDF文件的數量雖然只有 JPEG 圖片數量的一半,但每個 PDF 文件平均有 8.8 頁。所以綜合看來要處理的 PDF 文件個數超過 JPEG 圖片量十多倍。不過用下面這個很簡單的辦法就能大大降低需要處理的 PDF 文件數目。
文件總頁數
有些 PDF 文件頁數很多,可能好幾千頁的都有。如果我們沒頭沒腦的通通識別會很占時間和資源。我們統計了一下 PDF 文件的頁數,發現超過一半的文件都只有一頁,超過十頁的文件大約只占 PDF 文件總數的 10%。所以我們設定了一個標準,不管文件有多長只識別前面十頁。
這樣算下來 90% 的 PDF 文檔我們都能實現完全索引。較長的文檔我們雖然沒有完全實現識別和索引,但能搜十頁也比完全搜索不到好的多了。
自動文字識別系統
▌圖片的渲染
對于 PDF 文件中圖片的渲染由兩種可行的方式:一個是將頁面中的圖片一張張提取出來,另一個是將一頁文件當一整張圖片來處理。這兩種方法我們都測試了,不過 Dropbox 的文件預覽功能已經有了完善的 PDF 渲染能力,所以最終我們選擇了第二個方法。這樣處理的話,像 PowerPoint 或者 Post Script 這樣的文件格式,只要能支持預覽,我們就能進行識別,而且詞與詞、段與段之間的順序不會被打亂。
我們的渲染功能是基于谷歌的 PDFium 開發的。這其實也是 Chrome 瀏覽器所使用的 PDF 渲染引擎。渲染的過程中我們使用了并行處理來降低延遲。
▌文件圖像分類
模型方面我們先用了 GoogLeNet 來進行特征提取,然后用了一個線性分類器來實現有無文字的分類。訓練所用的圖片有些是網上公開的,有些是用戶和 Dropbox 員工提供的,一共有幾千張。
我們發現一開始訓練模型的時候準確率略低,模型把天際線、光溜溜的墻和開放水域這類圖片都判斷為有文字了。其實我們人眼都不太容易看出這些圖片有什么共同點,不過模型認為只要是背景比較均一,有橫線的就是有文字。最后是通過人工標記和給訓練集中加入這類圖片才克服了這個問題,從而把準確率提上來了。
▌識別圖片的四個角
用戶上傳的圖片因為拍照角度的原因,一般來說都不是我們想要的矩形和直角,所以必須進行矯正。要矯正的話,就要取得圖片中文件四個角的坐標,這個功能我們也是用卷積神經網絡來實現的。具體地說,就是把 Densenet-121 的輸出換成了四個角的坐標。
訓練這個模型用了幾百張圖。標記數據集的過程,需要一張一張地把文件的四個邊找出來。這項工作我們是在亞馬遜上眾包完成的。有的圖某個角可能壓根沒拍著,那這個角的坐標就跑到圖片外面去了,這時候就只能靠人工腦補了。
為了加快速度,訓練模型的時候用的圖片分辨率比實際的圖片分辨率低,所以輸出的坐標也是低分辨率圖片上的坐標。為了提高精度,我們在四個角附近,用高分辨率的圖片把模型重跑了一遍。這樣既提升了訓練的速度,又能得到高精度圖片上四個角的坐標。
▌單詞提取
這一部分以矯正過的圖片作為輸入,輸出的則是單詞的內容和定界框。單詞就按照識別出的順序一一加入索引。如果文件超過一頁,則繼續建立索引一直達到 10 頁的限制就停。
上面講的的這幾個部分組合起來看是這樣的:
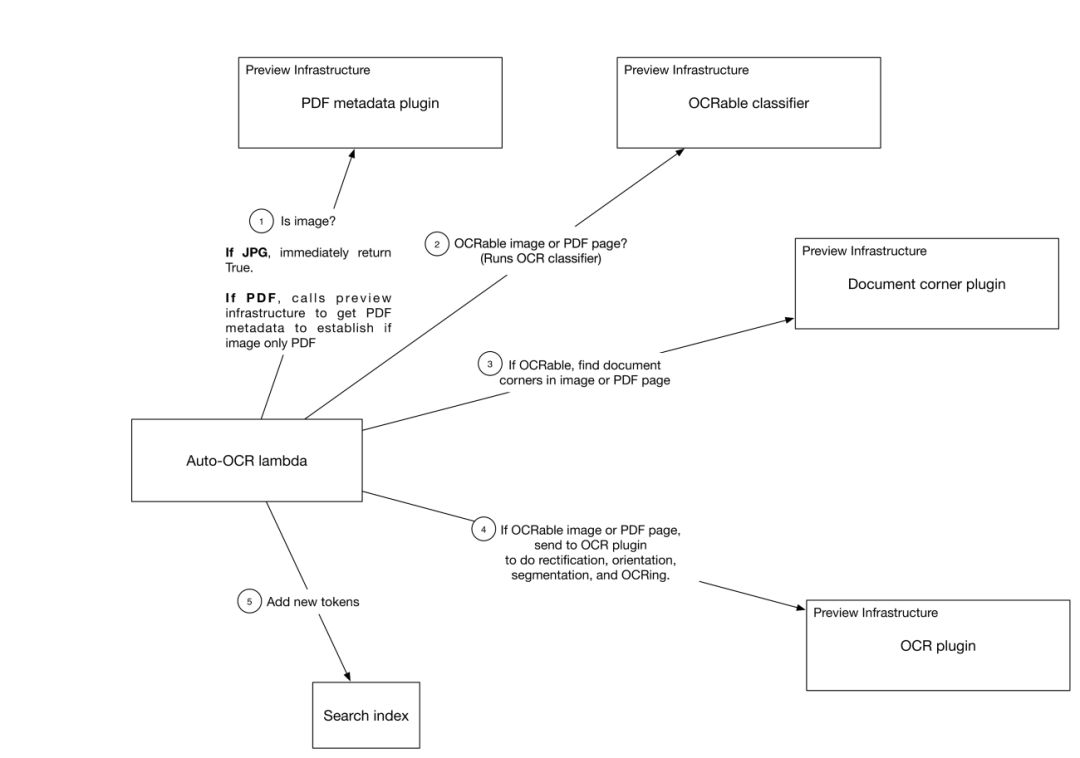
圖中標出的步驟我們來分別介紹一下:
通過檢查文件格式判斷是否含有圖片;判斷用戶權限
判斷圖片或 PDF 文件是否含有可識別的文字
判斷圖片的四個角以便進行矯正
提取單詞
加入索引
圖中有一個我們之前沒有介紹過的 Auto-OCR lambda 模塊,這其實是一個 Cape 微服務。Cape 是 Dropbox 在 16 年底推出的一個異步事件流處理框架,Dropbox 很多功能都用到了Cape。有了這個 Cape 微服務,當用戶對文件進行增改的時候文字識別功能就能自動觸發了,也就是圖中列出來的步驟 1 到 5。
得益于 Dropbox 預覽功能所提供的基礎設施,這一系列從讀取文件,判斷類型,矯正到最后識別操作的效率很高,而且這套系統對文件的操作(比如渲染)是進行了緩存的,所以當用戶上傳同一個文件不會造成系統資源的二次開銷。增加支持的文件類型和操作也是非常容易,只要為新的文件類型開發一個預覽插件就行了。現在對 PDF 文件的識別也是通過插件來實現的。
為了提供系統的穩定性,我們在插件的調用過程中使用了指數補償算法并加入了隨機值。拿第一步調用的插件來說,重試之后失敗率降低了 88%。
性能優化
剛開始測試的時候我們發現所使用的機器學習模型所占的資源和帶來的延遲完全在我們能接受的范圍之外,所以必須進行優化。我們決定先從配置參數著手,因為我們發現如果模型的性能遭遇瓶頸,很多時候簡單地改變配置參數就能收到很好的效果。下面我們就來舉幾個例子說明一下。
我們的第一個改動是關閉了 TensorFlow 的多核支持。Dropbox 系統并行是在 CPU 層面實現的。每個核只運行一個單線程的程序,這樣可以避免對數據的損壞也能降低惡意軟件入侵的風險。然而,TensorFlow 默認是開啟多核支持的。這樣相當于每一個核又在跑多線程了,由此引起的上下文切換使得系統吞吐量損失了約 2/3。
關閉多核支持后性能還是不夠好。所以我們又換成了支持 AVX2 指令集的 TensorFlow 并將模型和環境用 TensorFlow XLA 提前編譯成一個 C++ 庫。此外我們還調整了一些隱藏層的節點數量。
圖像四個角坐標和文本方向的判斷我們所采用的模型架構是 Densenet-121。相比之前用過的 Inception-Resnet-v2 來說速度大概快了一倍,坐標識別的準確率只是稍遜,而且是可以忽略不計的程度。
其實我們所作的這些工作都是為了加深對文件結構和內容的理解,讓用戶使用 Dropbox 時可以有更好的體驗。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100719 -
自動識別
+關注
關注
3文章
221瀏覽量
22831 -
機器學習
+關注
關注
66文章
8407瀏覽量
132567
原文標題:Dropbox如何使用機器學習從數十億圖片中自動提取文字
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI提取圖片里包含的文字信息-解決文字無法復制的痛點
求助帖 labview自動識別
請問USB自動識別芯片RH7901是怎樣自動識別充電設備的?
NLPIR在文本信息提取方面的優勢介紹
基于AI通用文字識別能力,檢測和識別文檔翻拍、街景翻拍等圖片中的文字
如何實現系統自動識別并切斷電池供電的呢?
基于SAW技術的車輛自動識別系統的實現
基于機器學習的日志自動識別
使用MATLAB編程軟件和機器視覺實現汽車車牌自動識別
圖片文字識別:揭開數字世界的神秘面紗
水位自動識別攝像機






 工商網監
工商網監
評論