 基于深度學習模型的點云目標檢測及ROS實現
基于深度學習模型的點云目標檢測及ROS實現
近年來,隨著深度學習在圖像視覺領域的發展,一類基于單純的深度學習模型的點云目標檢測方法被提出和應用,本文將詳細介紹其中一種模型——SqueezeSeg,并且使用ROS實現該模型的實時目標檢測。
傳統方法VS深度學習方法
實際上,在深度學習方法出現之前,基于點云的目標檢測已經有一套比較成熟的處理流程:分割地面->點云聚類->特征提取->分類,典型的方法可以參考Velodyne的這篇論文:LIDAR-based 3D Object Perception
▌那么傳統方法存在哪些問題呢?
1.第一步的地面分割通常依賴于人為設計的特征和規則,如設置一些閾值、表面法線等,泛化能力差;
2.多階段的處理流程意味著可能產生復合型錯誤——聚類和分類并沒有建立在一定的上下文基礎上,目標周圍的環境信息缺失;
3.這類方法對于單幀激光雷達掃描的計算時間和精度是不穩定的,這和自動駕駛場景下的安全性要求(穩定,小方差)相悖。
因此,近年來不少基于深度學習的點云目標檢測方法被提出,本文介紹的SqueezeSeg就是其中一種,這類方法使用深度神經網絡提取點云特征,以接近于端到端的處理流程實現點云中的目標檢測。
論文:SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud,
https://arxiv.org/pdf/1710.07368.pdf
SqueezeSeg理論部分
▌概括
SqueezeSeg使用的是CNN(卷積神經網絡)+CRF(Conditional Random Field,條件隨機場)這樣的結構。
其中,CNN采用的是Forrest提出的SqueezeNet網絡(詳情見論文:“SqueezeNet: Alexnet-level accuracy with 50x fewer
parameters and < 0.5mb model size”, https://arxiv.org/pdf/1602.07360.pdf ), 該網絡使用遠少于AlexNet的參數數量便達到了等同于AlexNet的精度,極少的參數意味著更快的運算速度和小的內存消耗,這是符合車載場景需求的。
被預處理過的點云數據(二維化)將被以張量的形式輸入到這個CNN中,CNN輸出一個同等寬高的標簽映射(label map),實際上就是對每一個像素進行了分類,然而單純的CNN逐像素分類結果會出現邊界模糊的問題,為解決該問題,CNN輸出的標簽映射被輸入到一個CRF中,這個CRF的形式為一個RNN,其作用是進一步的矯正CNN輸出的標簽映射。最終的檢測結果論文中使用了DBSCAN算法進行了一次聚類,從而得到檢測的目標實體。
下面我們從預處理出發,首先理解這一點云目標檢測方法。
▌點云預處理
傳統的CNN設計多用于二維的圖像模式識別(寬 × imes× 高 × imes× 通道數),三維的點云數據格式不符合該模式,而且點云數據稀疏無規律,這對特征提取都是不利的,因此,在將數據輸入到CNN之前,首先對數據進行球面投影,從而到一個稠密的、二維的數據,球面投影示意圖如下:
其中,?和θ分別表示點的方位角(azimuth)和頂角(altitude),這兩個角如下圖所示:
通常來說,方位角是相對于正北方向的夾角,但是,在我們Lidar的坐標系下,方位角為相對于x方向(車輛正前方)的夾角,?和θ的計算公式為:
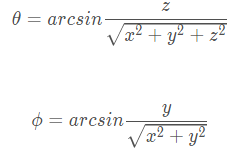
其中,(x,y,z) 為三維點云中每一個點的坐標。所以對于點云中的每一個點都可以通過其 (x,y,z) 計算其 (θ,?) ,也就是說我們將三維空間坐標系中的點都投射到了一個球面坐標系,這個球面坐標系實則已經是一個二維坐標系了,但是,為了便于理解,我們對其角度進行微分化從而得到一個二維的直角坐標系:

那么,球面坐標系下的每一個點都可以使用一個直角坐標系中的點表示,如下:
通過這么一層變換,我們就將三維空間中任意一點的位置(x,y,z) 投射到了2維坐標系下的一個點的位置 (i,j) 我們提取點云中每一個點的5個特征: (x,y,z,intensity,range) 放入對應的二維坐標 (i,j) 內。從而得到一個尺寸為 (H,W,C) 張量(其中C=5),由于論文使用的是Kitti的64線激光雷達,所以 H=64,水平方向上,受Kitti數據集標注范圍的限制,原論文僅使用了正前方90度的Lidar掃描,使用512個網格對它們進行了劃分(即水平上采樣512個點)。所以,點云數據在輸入到CNN中之前,數據被預處理成了一個尺寸為 (64×512×5) 的張量。
▌CNN結構
SqueezeSeg的CNN部分幾乎完全采用的SqueezeNet網絡結構,SqueezeNet是一個參數量極少但是能夠達到AlexNet精度的CNN網絡,在對實時性有要求的點云分割應用場景中采用頗有意義。其網絡結構如下:
該網絡最大的特色為兩個結構,被稱為 fireModules 和 fireDeconvs,這兩種網絡層的具體結構如下:
由于輸入的張量的高度(64)要小于其寬度(512),該網絡主要對寬度進行降維,通過添加最大池化層(Max Pooling)降低數據的寬度。到Fire9輸出的是降維后的特征映射。為了得到一個完整的映射標簽,還需要對特征映射進行還原(即還原到原尺寸),conv14層的輸出即對每個點的分類概率映射。輸出最后被輸入到一個條件隨機場中進行進一步的矯正。
SqueezeSeg中采用的CRF
在深度學習技術不斷進步的同時,概率圖形模型已被開發為用于提高像素級標記任務準確性的有效方法。馬爾可夫隨機場(Markov Random Fields, MRF)及其變體——條件隨機場(Conditional Random Fields, CRF)已經成為計算機視覺中最成功的概率圖模型之一。
由于CNN網絡的下采樣層(如最大池化層)的存在,使得數據的一些底層細節在CNN被拋棄,近而造成CNN輸出的預測分類存在邊界模糊的問題。高精度的逐像素分類不僅依賴于高層特征,也受到底層細節信息的影響,細節信息對于標簽分類的一致性至關重要。打個比方,如果點云中兩個點相近,同時具有類似的強度值(intensity),那么它們就有可能屬于同一個目標(即具有一樣的分類)。
CRF推理應用于語義標記的關鍵思想是將標簽分配(對于像素分割來說就是像素標簽分配)問題表達為包含類似像素之間具有一定標簽協議的假設的概率推理問題。CRF推理能夠改進像素級標簽預測,以產生清晰的邊界和細粒度的分割。因此,CRF可用于克服利用CNN進行像素級標記任務的缺點。為了彌補下采樣過程中細節信息的損失,SqueezeSeg在最后使用RNN實現一個CRF推理,以對label map進行進一步精煉,這里作者參考了論文: Conditional Random Fields as Recurrent Neural Networks ,該論文提出了mean-field 近似推理,以帶有高斯pairwise的勢函數的密集CRF作為RNN,在前向過程中對CNN粗糙的輸出精細化,同時在訓練時將誤差返回給CNN。結合了CNN與RNN的模型可以正常的利用反向傳播來端對端的訓練。SqueezeSeg的CRF部分結構如下圖所示:
我們將CNN的輸出結果作為CRF的輸入,根據原始點云計算高斯濾波器,其有兩個高斯核,如下所示:
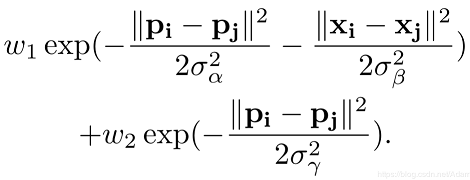
其中x為點的三維坐標 (x,y,z) ,p為點經過球面投影得到的方位角和頂角 (θ,?),其他參數為經驗性閾值。該高斯核衡量了兩點之間特征的差異,兩點之間差異越大( x xx 和 p pp 相差越多),高斯核的值就越小,兩點之間的相關性也就越小。在輸入圖像使用該高斯濾波器的過程稱為message passing,可以初步聚合鄰域點的概率。接著,通過1x1大小的卷積核去微調每一個點的概率分布權重,這一個過程稱為re-weighting and compatibilty transformation,卷積核的值是通過學習得到。最后,以殘差方式將最初的便簽映射加到re-weighting的輸出結果并用softmax歸一化。在實際操作中,整個CRF以RNN層重復循環三次,并得到最終精煉后的標簽映射。
使用SqueezeSeg實現一個ROS節點進行點云目標識別與分割
SqueezeSeg的模型訓練代碼在本文中不在贅述,感興趣的同學可以直接去看作者的開源代碼:
SqueezeSeg作者開源的模型訓練代碼:
https://github.com/BichenWuUCB/SqueezeSeg
上面的代碼為TensorFlow實現,基于上述倉庫,我們實現一個ROS節點,調用一個已經訓練好的SqueezeSeg模型,對輸入的點云進行目標識別和分割。所以在運行下述實例代碼之前,需要自行安裝好TensorFlow-GPU版本(CPU版本亦可,但是運行速度相對要慢一些),本文假定大家已經安裝好TensorFlow環境,我們來繼續關注基于SqueezeSeg的ROS應用開發,我們采用論文作者公開的數據(來源于Kitti,采集自HDL-64雷達,同時已經完成了前向90度的切割,并且被保存成了npy文件)。
數據下載地址:
https://www.dropbox.com/s/pnzgcitvppmwfuf/lidar_2d.tgz?dl=0
國內讀者如無法訪問,可以使用此地址下載:
https://pan.baidu.com/s/1kxZxrjGHDmTt-9QRMd_kOA
將數據下載好以后解壓到ROS package的 script/data/ 目錄下,解壓以后的目錄結構為:
squeezeseg_ros/script/data/lidar_2d/
完整代碼見文末github倉庫。
采用作者開源的數據的一個很重要的原因在于手頭沒有64線的激光雷達,首先我們看看launch文件內容:
npy_path參數即為我們的數據的目錄,我們將其放在package的script/data目錄下,npy_file_list是個文本文件的路徑,它記錄了驗證集的文件名,pub_topic指定我們最后發布出去的結果的點云topic名稱,checkpoint參數指定我們預先訓練好的SqueezeSeg模型的目錄,它是一個TensorFlow 的checkpoint文件,gpu參數指定使用主機的那一快GPU(即指定GPU的ID),通常我們只有一塊GPU,所以這里設置為0,如果主機沒有安裝GPU(當然TensorFlow-gpu也就無法工作),則會使用CPU。squeezeseg_ros_node.py即為我們調用模型的接口,最后我們在啟動Rviz,加載設定好的Rviz配置文件,即可將模型的識別結果可視化出來。
具體到squeezeseg_ros_node.py中,首先加載參數并且配置checkpoint路徑:
rospy.init_node('squeezeseg_ros_node')npy_path=rospy.get_param('npy_path')npy_file_list=rospy.get_param('npy_file_list')pub_topic=rospy.get_param('pub_topic')checkpoint=rospy.get_param('checkpoint')gpu=rospy.get_param('gpu')FLAGS=tf.app.flags.FLAGStf.app.flags.DEFINE_string('checkpoint',checkpoint,"""Pathtothemodelparamterfile.""")tf.app.flags.DEFINE_string('gpu',gpu,"""gpuid.""")npy_tensorflow_to_ros=NPY_TENSORFLOW_TO_ROS(pub_topic=pub_topic,FLAGS=FLAGS,npy_path=npy_path,npy_file_list=npy_file_list)
循環讀取npy數據文件,讀取文件的代碼如下:
#Readall.npydatafromlidar_2dfolderdefget_npy_from_lidar_2d(self,npy_path,npy_file_list):self.npy_path=npy_pathself.npy_file_list=open(npy_file_list,'r').read().split(' ')self.npy_files=[]foriinrange(len(self.npy_file_list)):self.npy_files.append(self.npy_path+self.npy_file_list[i]+'.npy')self.len_files=len(self.npy_files)
調用深度學習模型對點云進行分割和目標檢測識別,并將檢測出來的結果以PointCloud2的msg格式發到指定的topic上:
#Readall.npydatafromlidar_2dfolderdefget_npy_from_lidar_2d(self,npy_path,npy_file_list):self.npy_path=npy_pathself.npy_file_list=open(npy_file_list,'r').read().split(' ')self.npy_files=[]foriinrange(len(self.npy_file_list)):self.npy_files.append(self.npy_path+self.npy_file_list[i]+'.npy')self.len_files=len(self.npy_files)defprediction_publish(self,idx):clock=Clock()record=np.load(os.path.join(self.npy_path,self.npy_files[idx]))lidar=record[:,:,:5]#toperformpredictionlidar_mask=np.reshape((lidar[:,:,4]>0),[self._mc.ZENITH_LEVEL,self._mc.AZIMUTH_LEVEL,1])norm_lidar=(lidar-self._mc.INPUT_MEAN)/self._mc.INPUT_STDpred_cls=self._session.run(self._model.pred_cls,feed_dict={self._model.lidar_input:[norm_lidar],self._model.keep_prob:1.0,self._model.lidar_mask:[lidar_mask]})label=pred_cls[0]#pointcloudforSqueezeSegsegmentsx=lidar[:,:,0].reshape(-1)y=lidar[:,:,1].reshape(-1)z=lidar[:,:,2].reshape(-1)i=lidar[:,:,3].reshape(-1)label=label.reshape(-1)cloud=np.stack((x,y,z,i,label))header=Header()header.stamp=rospy.Time().now()header.frame_id="velodyne_link"#pointcloudsegmentsmsg_segment=self.create_cloud_xyzil32(header,cloud.T)#publishself._pub.publish(msg_segment)rospy.loginfo("Pointcloudprocessed.Took%.6fms.",clock.takeRealTime())
不同于一般的PointCloud2 msg,這里的每一個點除了包含x,y,z,intensity字段以外,還包含一個label字段(即分類的結果),構建5字段的PointCloud2 msg的代碼如下:
#createpc2_msgwith5fieldsdefcreate_cloud_xyzil32(self,header,points):fields=[PointField('x',0,PointField.FLOAT32,1),PointField('y',4,PointField.FLOAT32,1),PointField('z',8,PointField.FLOAT32,1),PointField('intensity',12,PointField.FLOAT32,1),PointField('label',16,PointField.FLOAT32,1)]returnpc2.create_cloud(header,fields,points)
使用launch文件啟動節點:
roslaunchsqueezeseg_rossqueeze_seg_ros.launch
彈出Rviz界面,識別分割如下:
在我的 CPU:i7-8700 + GPU:GTX1070的環境下,處理一幀數據的耗時大約在50ms以內,如下:
對于semantic segmentationz這類任務而言,其速度已經比較可觀了,通常雷達頻率約為10HZ,該速度基本達到要求。
-
無人駕駛汽車
+關注
關注
17文章
151瀏覽量
37597 -
深度學習
+關注
關注
73文章
5527瀏覽量
121879
原文標題:無人駕駛汽車系統入門:基于深度學習的實時激光雷達點云目標檢測及ROS實現
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
采用華為云 Flexus 云服務器 X 實例部署 YOLOv3 算法完成目標檢測

基于深度學習的三維點云分類方法







 工商網監
工商網監
評論