 在i.MX RT飛行學習板中的軟件優化辦法,讓C代碼在ARM Cortex-M7內核上極速飛奔
在i.MX RT飛行學習板中的軟件優化辦法,讓C代碼在ARM Cortex-M7內核上極速飛奔
牡丹雖好,仍需綠葉扶持;RT雖快,仍需優化。本文將分享在i.MX RT飛行學習板中的軟件優化辦法,讓C代碼在ARM Cortex-M7內核上極速飛奔!01
概述
i.MX RT飛行學習板,是真的會飛的處理器學習板!它的核心是恩智浦公司的跨界處理器i.MX RT1052, 基于ARM Cortex-M7內核,主頻達600 MHz!對于電機驅動,雖然速度驚人,但是這個學習板要同時運行“4無刷電機FOC驅動 + 飛控算法”,所以依然不是輕易的事情。
牡丹雖好,仍需綠葉扶持,下面將分享多種優化手段,讓C代碼在i.MX RT上極速飛奔,實現這個“單芯片無人機”。先上段熱身視頻。
視頻1 熱身視頻
02
加快代碼速度的秘訣
1、選擇硬件浮點
重要而簡單的第一步是:在編譯器中選擇“硬件雙精度浮點”,圖1是在KEIL中的選擇配置。
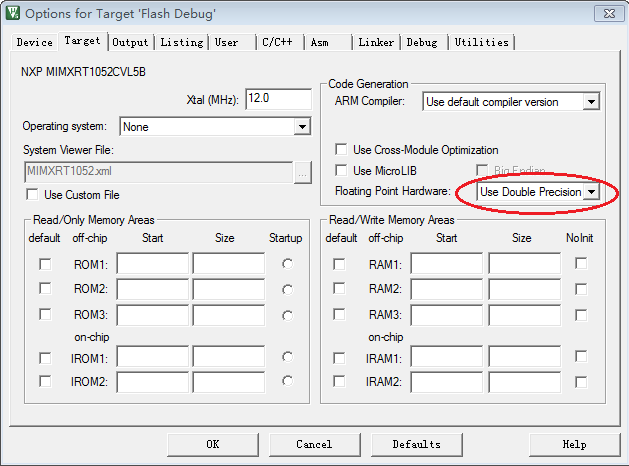
圖1 雙精度浮點
選擇“硬件雙精度浮點”的作用是,當C代碼需要雙精度、單精度浮點運算,編譯器就選擇最優的浮點指令,速度最快!如果選擇“硬件單精度浮點”,單精度浮點運算就用單精度浮點指令,但雙精度浮點運算只能結合多條單精度指令完成,速度較慢。如果不選擇任何硬件浮點,編譯器僅能用定點指令完成浮點運算,速度非常慢。
但要注意,不是任意處理器都支持“硬件浮點”,即便同樣是ARM Cortex-M7內核,有些半導體廠家為了降低成本,會裁掉“雙精度浮點”單元,只留下“單精度浮點”。而i.MX RT支持完整的單、雙精度浮點單元。得益于這個優勢,飛行學習板中的ZLG-Soar飛控軟件,全部核心代碼都使用雙精度浮點指令,不單止精度高、而且速度超快,在相同主頻下,比定點指令的Cortex-M3快20倍以上!
2、關鍵代碼RAM中運行
將代碼放在ITCM相連的RAM中運行,速度最快!
Cortex-M7的中ITCM(Instruction-Tightly Coupled Memories)是專門的指令總線。我們在i.MX RT1052中分配了256Kbytes的內部RAM在ITCM上,而且和Flash相比,內部RAM沒有明顯的讀取延時,所以代碼在這段RAM中運行,速度是最快的,沒有更快!
程序清單1是飛行學習板在KEIL中的分散加載的配置,全部只讀RO數據(即代碼和CONST變量等)放在0x00000400地址開始的ITCM RAM里面。KEIL編譯后,其實全部原始數據都是存在Flash中,但 KEIL自動在main函數前插入一段Flash函數,該函數將相關的代碼從Flash復制到RAM,最后將PC指針改到RAM。這樣代碼就從RAM開始運行。
程序清單1 ITCM RAM分散加載
如果代碼很大,無法全部復制到RAM中運行,那么可以修改分散加載,僅將必要的代碼放在RAM中運行,其他代碼在Flash中運行。
3、關鍵算法寫成宏定義
在ZLG-FOC電機矢量控制庫中,全部核心算法都寫成宏定義的形式,如程序清單2的Clarke變換。
程序清單2 宏定義算法
如果寫成C函數,那么上層代碼調用時,一般先進行入棧操作、保護現場,接著跳轉到該函數運行,然后調用返回指令回到上層代碼,最后進行出棧操作、恢復現場。這個過程必然會延長爭分奪秒的算法執行時間。
可能有的人會說:在函數前面聲明inline,函數不就直接嵌入到上層代碼中,省去這些啰嗦過程嗎?其實不一定,編譯器也是很無奈的,KEIL和IAR的編譯手冊都說得很明白:根據代碼調用與被調用的復雜程度,能嵌進去的,編譯器就幫忙嵌進去,不能嵌進去的,只能按普通函數那樣處理!
但如果將算法寫成宏定義,那么編譯會100%保證代碼會被直接嵌入到上層代碼中!只是對于過長的代碼,宏定義編寫不方便,這時候可以將代碼分拆成多個宏定義組合使用,或者僅把最必要的部分寫成宏定義。
4、盡量用C,少用匯編
盡量用C,少用匯編?晚上加班眼花,寫反了吧?沒寫錯,“匯編比C快”是好多年前、奔騰電腦時代的事情!現在是人工智能、大數據的時代,KEIL和IAR 的C編譯器經過幾十年的發展,都變得非常聰明了(GCC筆者使用不多,不敢莽加評論)。首先,人腦能想到的最優指令,C編譯器很多時候也能想到,可能比人腦想得更優!再者,用匯編寫代碼,即便絞盡腦汁,頂多就單個函數速度最優,僅此而已!而C編譯器還會“綜合統籌”,例如,前后重復的代碼,它會合拼在一起;廢話、沒用的代碼,它會刪除;函數反復跳轉時的出入棧過程,它會想辦法減少……再配合上面提到的“算法寫成宏定義”,C代碼的運行速度將更快!
就如我們敬愛的周工教導說:豬腦不如人腦、人腦不如電腦,i.MX RT在極速飛奔下就是很好的體現。
5、巧妙浮點出入棧
圖2顯示了Cortex-M7的浮點寄存器,S0-S31是浮點的通用寄存器,其他是控制或狀態等寄存器。如果軟件使能了浮點單元,那么在中斷發生后,M7默認會將S0-S15、FPSCR等17個浮點寄存器硬件入棧,中斷完成后硬件出棧。雖然說是“硬件”,其實硬件也要花時間一個一個寄存器弄的,只不過比軟件處理,省了調用指令的時間。
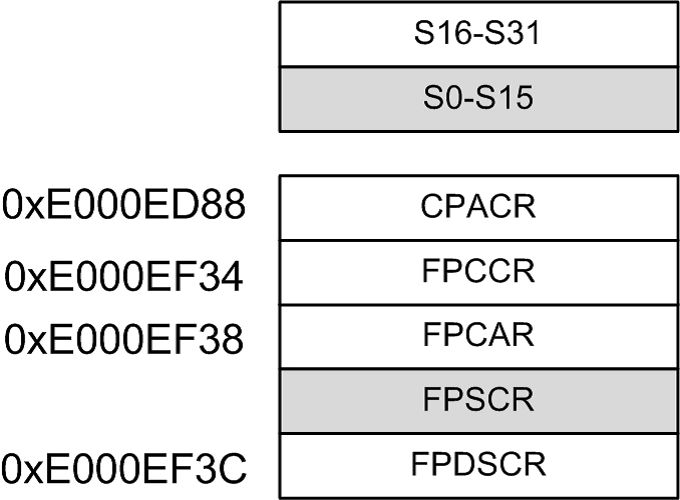
圖2 Cortex-M7浮點寄存器
這里提出一個問題:假如有10個中斷程序輪流產生,處理器就自動對17個浮點寄存器出入棧操作,但如果僅只有一個中斷使用了浮點指令,其他9個都不使用,那么大部分浮點出入棧的操作都是浪費時間的!
如何解決這個問題呢?
ARM提出一種LAZY模式(其實一點都不懶),在中斷發生后,硬件只給17個浮點寄存器預留堆棧空間,但不入棧,只有中斷函數調用了第一條浮點指令前(例如浮點加、減、乘、除),硬件才補充入棧;中斷完成后,如果真的發生過硬件浮點入棧,才會相應地出棧。這樣大大提高了浮點出入棧的效率!這種LAZY模式夠聰明吧,真不知ARM怎樣起名的,可能懶的極端就是聰明吧。
6、代碼清晰、聰明
圖3中的兩條蛇在樹上互相糾纏,分不清尾巴是誰的。寫代碼也同樣道理,如果習慣性地想到一點寫一點、寫前不規劃、寫后懶修改,就像圖3左邊的代碼,一堆if/else,邏輯模糊、難懂、難改,運行速度沒保證。而右邊的代碼是經過分析推理的聰明辦法,用switch case替代一堆if/else,邏輯清晰、易懂、易改,運行速度有保證!
圖3 清晰聰明的代碼
前面介紹了很多在i.MX RT上加快代碼速度的方法,但都是輔助的,最核心的還是:花點心思規劃代碼要怎樣寫,代碼要清晰、聰明。
03
總結
牡丹雖好,仍需綠葉扶持,RT雖快,但仍需優化才能發揮到極致的速度,將不可能的事情變為現實!就如我們ZLG的i.MX RT飛行學習板,是業界唯一的“4無刷電機FOC +飛控算法”的無人機方案。
11月初期的廣州還是茵茵綠草,我們踏青放飛去。
視頻2 踏青放飛
-
處理器
+關注
關注
68文章
19259瀏覽量
229655 -
編譯器
+關注
關注
1文章
1624瀏覽量
49108 -
C代碼
+關注
關注
1文章
89瀏覽量
14297
原文標題:i.MX RT飛行學習板——如何讓C代碼在M7上極速飛奔?
文章出處:【微信號:Zlgmcu7890,微信公眾號:周立功單片機】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
初識Layerscape和I.MX系列處理器
【大聯大品佳 NXP i.MX RT1050試用體驗】芯林至尊,寶刀RT1050,初識i.MX RT系列跨界處理器 (之一)
Cortex-M7 + M4內核的MCU資料大合集
Cortex-M7 + M4內核的MCU性能及特點是什么
ZLG攜手NXP舉行i.MX RT 跨界處理器全國巡回研討會
高達600MHz主頻的Cortex-M7 MCU

基于i.MX RT1061處理器的OK1061-S開發板介紹

支持高級語音命令和人臉識別應用的NXP i.MX RT106L和RT106F處理器
恩智浦i.MX RT1170開創GHz MCU時代
恩智浦i.MX RT1170在將該系列帶上了更高的層面
恩智浦推出核跨界MCU的第二款產品i.MX RT1160
NXP推出基于i.MX RT117H的智能人機界面解決方案
基于 NXP i.MX RT1050 的 3D 打印機方案





 工商網監
工商網監
評論