 谷歌再次發布BERT的多語言模型和中文模型
谷歌再次發布BERT的多語言模型和中文模型
今天,在開源最強NLP模型BERT的TensorFlow代碼和預訓練模型的基礎上,谷歌AI團隊再次發布一個多語言模型和一個中文模型。
上周,谷歌AI團隊開源了備受關注的“最強NLP模型”BERT的TensorFlow代碼和預訓練模型,不到一天時間,收獲3000多星!
今天,谷歌再次發布BERT的多語言模型和中文模型!
BERT,全稱是BidirectionalEncoderRepresentations fromTransformers,是一種預訓練語言表示的新方法。
BERT有多強大呢?它在機器閱讀理解頂級水平測試SQuAD1.1中表現出驚人的成績:全部兩個衡量指標上全面超越人類!并且還在11種不同NLP測試中創出最佳成績,包括將GLUE基準推至80.4%(絕對改進7.6%),MultiNLI準確度達到86.7% (絕對改進率5.6%)等。
新智元近期對BERT模型作了詳細的報道和專家解讀:
NLP歷史突破!谷歌BERT模型狂破11項紀錄,全面超越人類!
狂破11項記錄,谷歌年度最強NLP論文到底強在哪里?
解讀谷歌最強NLP模型BERT:模型、數據和訓練
如果你已經知道BERT是什么,只想馬上開始使用,可以下載預訓練過的模型,幾分鐘就可以很好地完成調優。
戳這里直接使用:
https://github.com/google-research/bert/blob/master/multilingual.md
模型
目前有兩種多語言模型可供選擇。我們不打算發布更多單語言模型,但可能會在未來發布這兩種模型的BERT-Large版本:
BERT-Base, Multilingual:102 languages, 12-layer, 768-hidden, 12-heads, 110M parameters
BERT-Base, Chinese:Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
多語言模型支持的語言是維基百科上語料最大的前100種語言(泰語除外)。多語言模型也包含中文(和英文),但如果你的微調數據僅限中文,那么中文模型可能會產生更好的結果。
結果
為了評估這些系統,我們使用了XNLI dataset,它是MultiNLI的一個版本,其中dev集和test集已經(由人類)翻譯成15種語言。需要注意的是,訓練集是機器翻譯的(我們使用的是XNLI提供的翻譯,而不是Google NMT)。
以下6種主要語言的評估結果:
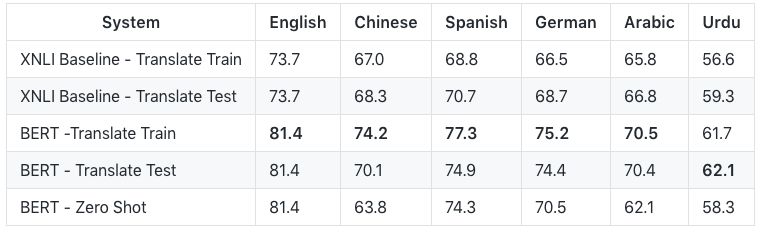
前兩行是XNLI baseline的結果,后三行是使用BERT的結果。
Translate Train表示MultiNLI的訓練集是從英語用機器翻譯成外語的。所以訓練和評估都是用外語完成的。遺憾的是,由于是用機器翻譯的數據進行訓練,因此無法量化較低的精度在多大程度上歸因于機器翻譯的質量,多大程度上歸因于預訓練模型的質量。
Translate Test表示XNLI測試集是從外語用機器翻譯成英語的。因此,訓練和評估都是用英語進行的。但是,由于測試評估是在機器翻譯的英語上進行的,因此準確性取決于機器翻譯系統的質量。
Zero Shot表示多語言BERT模型在英語MultiNLI上進行了微調,然后在外語XNLI測試集上進行了評估。在這種情況下,預訓練和微調的過程都不涉及機器翻譯。
請注意,英語的結果比MultiNLI baseline的84.2要差,因為這個訓練使用的是Multilingual BERT模型,而不是English-only的BERT模型。這意味著對于語料資源大的語言,多語言模型的表現不如單語言模型。但是,訓練和維護數十種單語言模型是不可行的。因此,如果你的目標是使用英語和中文以外的語言最大限度地提高性能,那么從我們的多語言模型開始,對你感興趣的語言數據進行額外的預訓練是有益的。
對于中文來說,用MultilingualBERT-Base和Chinese-onlyBERT-Base訓練的中文模型的結果比較如下:
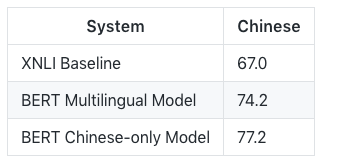
跟英語類似,單語言模型比多語言模型好3%。
Fine-tuning 示例
多語言模型不需要任何特殊考慮或更改API。我們在tokenization.py中更新了BasicTokenizer的實現以支持漢字的tokenization,但沒有更改 tokenization API。
為了測試新模型,我們修改了run_classifier.py以添加對XNLI數據集的支持。這是MultiNLI的15種語言版本,其中dev/test 集已經經過人工翻譯的,訓練集已經經過機器翻譯。
要運行 fine-tuning 代碼,請下載XNLI dev/test set和XNLI機器翻譯的訓練集,然后將兩個.zip文件解壓縮到目錄$XNLI_DIR中。
在XNLI上運行 fine-tuning。該語言被硬編碼為run_classifier.py(默認為中文),因此如果要運行其他語言,請修改XnliProcessor。
這是一個大型數據集,因此在GPU上訓練需要花費幾個小時(在Cloud TPU上大約需要30分鐘)。要快速運行實驗以進行調試,只需將num_train_epochs設置為較小的值(如0.1)即可。
export BERT_BASE_DIR=/path/to/bert/chinese_L-12_H-768_A-12 # or multilingual_L-12_H-768_A-12export XNLI_DIR=/path/to/xnli python run_classifier.py --task_name=XNLI --do_train=true --do_eval=true --data_dir=$XNLI_DIR --vocab_file=$BERT_BASE_DIR/vocab.txt --bert_config_file=$BERT_BASE_DIR/bert_config.json --init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt --max_seq_length=128 --train_batch_size=32 --learning_rate=5e-5 --num_train_epochs=2.0 --output_dir=/tmp/xnli_output/
使用 Chinese-only 模型,結果應該是這樣的:
***** Eval results ***** eval_accuracy = 0.774116 eval_loss = 0.83554 global_step = 24543 loss = 0.74603訓練細節
數據源和采樣
我們選擇的語言是維基百科上語料最大的前100種語言。將每種語言的整個Wikipedia轉儲數據(不包括用戶頁和討論頁)作為每種語言的訓練數據。
然而,對于特定語言,維基百科的語料大小差異很大,而在神經網絡模型中,低資源語言可能是“代表性不足”的(假設語言一定程度上在有限的模型容量中“競爭”)。
維基百科的語料大小也與該語言的使用者人數有關,而且我們也不想為了一種特定語言在很小的數據集上執行數千個epochs,造成過度擬合模型。
為了平衡這兩個因素,我們在訓練前數據創建(以及WordPiece詞匯創建)期間對數據進行了指數平滑加權。換句話說,假設一種語言的概率是P(L),例如P(English) = 0.21,表示在將所有維基百科總合在一起之后,21%的數據是英語的。我們通過某個因子S對每個概率求冪,然后重新規范化,并從這個分布中進行采樣。
在這個示例中,我們使S = 0.7。因此,像英語這樣的高資源語言會被抽樣不足,而像冰島語這樣的低資源語言會被過度采樣。比如說,在原始分布中,英語比冰島語采樣率高1000倍,但在平滑后,英語的采樣率只高100倍。
Tokenization
對于Tokenization,我們使用110k共享的WordPiece詞匯表。單詞計數的加權方式與數據相同,因此低資源語言的加權會增大。 我們故意不使用任何標記來表示輸入語言(以便zero-shot訓練可以工作)。
因為中文沒有空白字符,所以在使用WordPiece之前,我們在CJK Unicode范圍內的每個字符周圍添加了空格。這意味著中文被有效地符號化了。請注意,CJK Unicode block僅包含漢字字符,不包括朝鮮文/韓文或日語片假名/平假名,這些與其他語言一樣使用空格+ WordPiece進行標記化。
對于所有其他語言,我們應用與英語相同的方法:(a)字母小寫+重音刪除,(b)標點符號分割,(c)空白標記化。 我們知道口音標記在某些語言中具有重要意義,但認為減少有效詞匯的好處可以彌補這一點。一般來說,BERT強大的上下文模型應該能彌補刪除重音標記而引入的歧義。
支持的語言
多語言模型支持維基百科上語料量最大的前100種語言。
但我們不得不排除的唯一一種語言是泰語,因為它是唯一一種不使用空格來劃分單詞的語言(除了漢語),而且每個單詞的字符太多,不能使用基于字符的tokenization。
-
谷歌
+關注
關注
27文章
6164瀏覽量
105309 -
語言模型
+關注
關注
0文章
520瀏覽量
10268 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14880
原文標題:谷歌最強NLP模型BERT官方中文版來了!多語言模型支持100種語言
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ChatGPT 的多語言支持特點
科大訊飛發布訊飛星火4.0 Turbo大模型及星火多語言大模型
谷歌全新推出開放式視覺語言模型PaliGemma
使用OpenVINO 2024.4在算力魔方上部署Llama-3.2-1B-Instruct模型
Mistral AI與NVIDIA推出全新語言模型Mistral NeMo 12B
谷歌發布新型大語言模型Gemma 2
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
大語言模型(LLMs)如何處理多語言輸入問題


谷歌大型模型終于開放源代碼,遲到但重要的開源戰略

大語言模型背后的Transformer,與CNN和RNN有何不同






 工商網監
工商網監
評論