 街機游戲《街頭霸王 3》中進行模擬來訓練改進強化學習算法的工具包
街機游戲《街頭霸王 3》中進行模擬來訓練改進強化學習算法的工具包
從世界矚目的圍棋游戲 AlphaGo,近年來,強化學習在游戲領域里不斷取得十分引人注目的成績。自此之后,棋牌游戲、射擊游戲、電子競技游戲,如 Atari、超級馬里奧、星際爭霸到 DOTA 都不斷取得了突破和進展,成為熱門的研究領域。
突然襲來的回憶殺~
今天為大家介紹一個在街機游戲《街頭霸王 3》中進行模擬來訓練改進強化學習算法的工具包。不僅在 MAME 游戲模擬器中可以使用,這個 Python庫可以在絕大多數的街機游戲中都可以訓練你的算法。
下面營長就從安裝、設置到測試分步為大家介紹一下。
目前這個工具包支持在Linux系統,作為MAME的包裝器來使用。通過這個工具包,你可以定制算法逐步完成游戲過程,同時接收每一幀的數據和內部存儲器的地址值來跟蹤游戲狀態,以及發送與游戲交互的動作。
首先你需要準備的是:
操作系統:Linux
Python 版本:3.6+
▌安裝
你可以使用 pip來安裝該庫,運行下面的代碼:
▌《街頭霸王3》示例
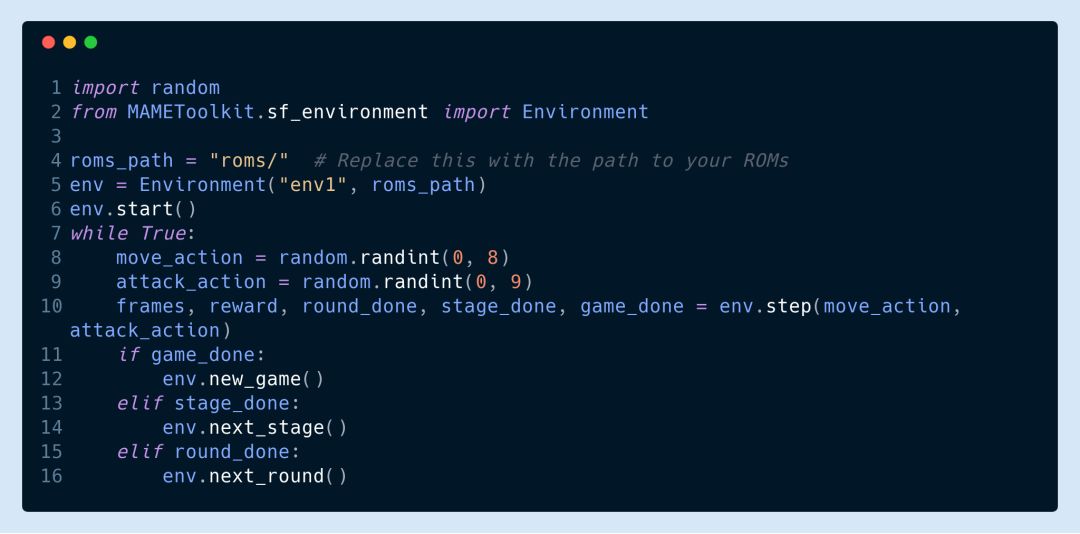
這個工具包目前已用于游戲《街頭霸王 3》(Street Fighter III Third Strike: Fight for the Future), 還可以用于MAME上的任何游戲。下面的代碼演示了如何在街頭霸王的環境下編寫一個隨機智能體。
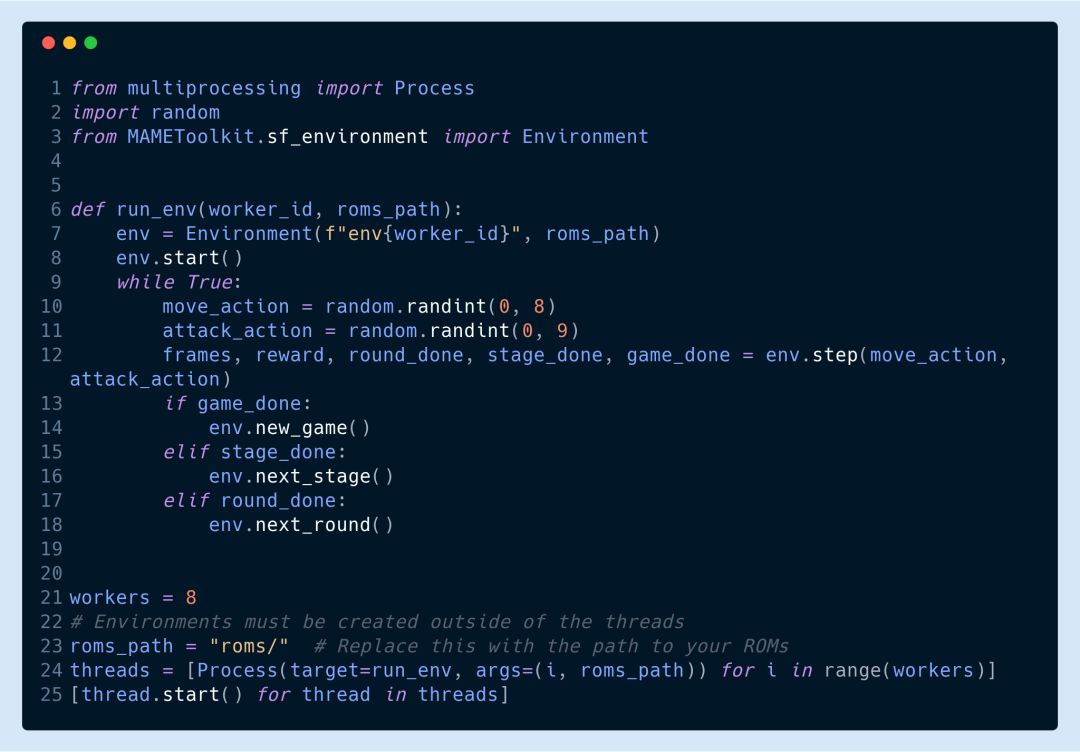
此外,這個工具包還支持hogwild訓練:
▌游戲環境設置
游戲 ID
在創建一個模擬環境之前,大家需要先加載游戲的 ROM,并獲取 MAME所使用的游戲 ID。比如,這個版本街頭霸王的游戲 ID是“sfiii3n”,你可以通過運行以下代碼來查看游戲ID:
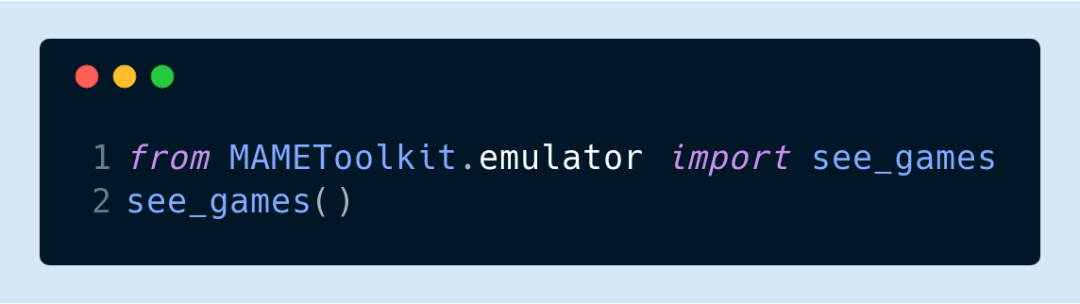
該命令會打開 MAME模擬器,你可以從游戲列表中選擇你所要的那款游戲。游戲的 ID通常位于標題后面的括號中。
內存地址
實際上該工具包與模擬器本身不需要太多的交互,只需要查找和內部狀態相關聯的內存地址,同時用所選取的環境對狀態進行跟蹤。你可以使用 MAME Cheat Debugger 來觀察隨著時間的變化,內存地址值發生了怎樣的改變。
可以使用以下命令運行Debugger:

更多關于該調試工具的使用說明請參考此教程:
https://www.dorkbotpdx.org/blog/skinny/use_mames_debugger_to_reverse_engineer_and_extend_old_games
當你確定了所要跟蹤的內存地址后可以執行以下命令進行模擬:
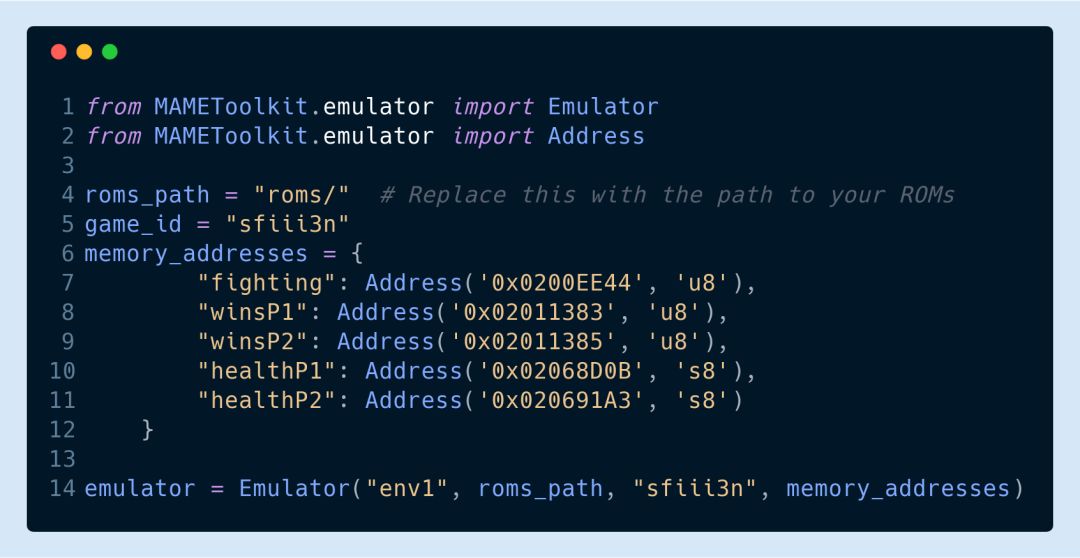
該命令會啟動模擬器,并在工具包導入到模擬器進程時暫停。
分步模擬
在工具包導入完成后,你可以使用 step 函數分步進行模擬:
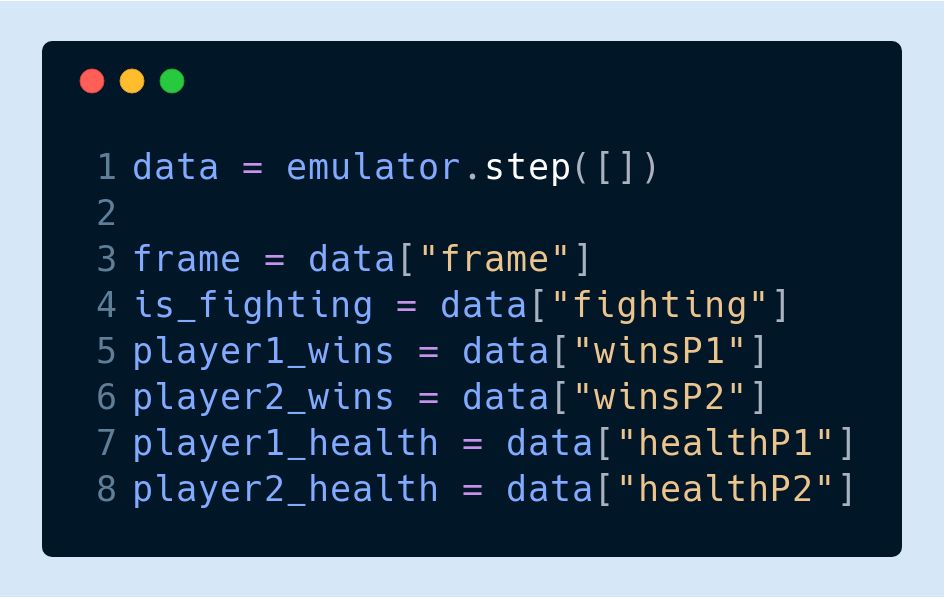
step 函數將以 Numpy 矩陣的形式返回 frame 和 data 的值,同時也會返回總時間步長的所有內存地址整數值。
發送輸入
如果要向仿真器輸入動作,你還需要確定游戲支持的輸入端口和字段。例如,在街頭霸王游戲中需要執行以下代碼進行投幣:

可以使用 list actions命令查看所支持的輸入端口,代碼如下:
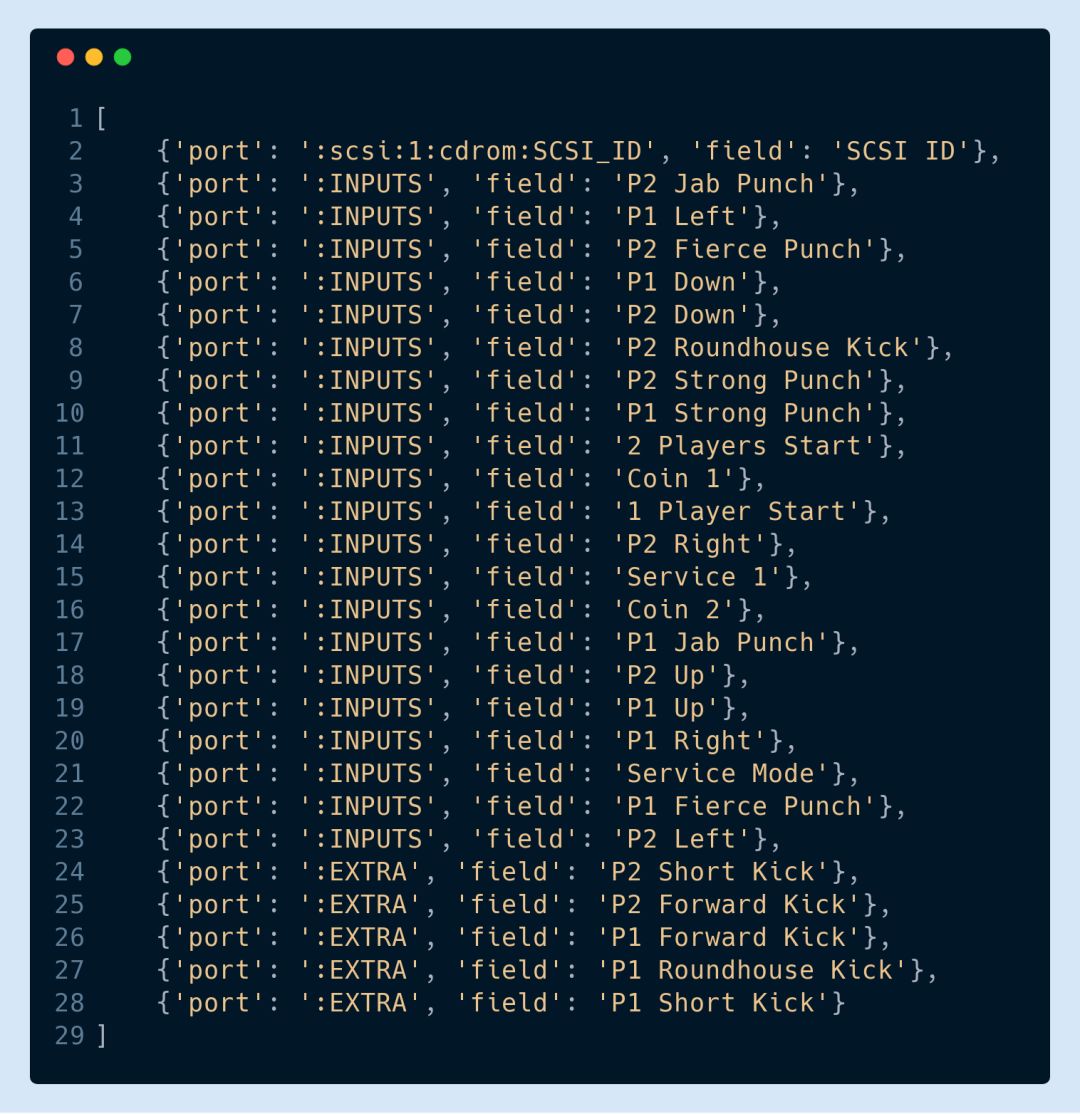
以下返回的列表就包含了街頭霸王游戲環境中可用于向 step 函數發送動作的所有端口和字段:
模擬器還有一個 frame_ratio參數,可以用來調整你的算法幀率。在默認設置下,NAME每秒能生成 60幀。當然,如果你覺得這樣太多了,你也能通過以下代碼將其改為每秒 20幀:

▌性能基準測試
目前該工具包的開發和測試已經在8核AMD FX-8300 3.3GHz CPU以及3GB GeForce GTX 1060 GPU上完成。在使用單個隨機智能體的情況下,街頭霸王游戲環境可以以正常游戲速度的600%+運行。而如果用8個隨機智能體進行hogwild訓練的話,街頭霸王游戲環境能以正常游戲速度的300%+運行。
▌簡單的 ConvNet 智能體
為了確保該工具包能夠訓練算法,我們還設置了一個包含 5 層 ConvNet 的架構,只需進行微調,你就能用它來進行測試。在街頭霸王的實驗中,這個算法能夠成功學習到游戲中的一些簡單技巧如:連招 (combo) 和 格擋 (blocking)。街頭霸王的游戲機制是由易到難設置了 10 個關卡,玩家在每個關卡都要與不同的對手對戰。剛開始時,智能體平均只能打到第二關,而當經過了 2200 次訓練后,它平均能打到第 5 關。學習率的設置是通過每一局中智能體所造成的凈傷害和所承受的傷害來計算的。
-
存儲器
+關注
關注
38文章
7553瀏覽量
164899 -
python
+關注
關注
56文章
4813瀏覽量
85301 -
強化學習
+關注
關注
4文章
269瀏覽量
11366
原文標題:用這個Python庫,訓練你的模型成為下一個街頭霸王!
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Facebook推出ReAgent AI強化學習工具包
樹莓派街機
深度強化學習實戰
什么是強化學習?純強化學習有意義嗎?強化學習有什么的致命缺陷?

NVIDIA遷移學習工具包 :用于特定領域深度學習模型快速訓練的高級SDK
谷歌AI發布足球游戲強化學習訓練環境“足球引擎”
基于PPO強化學習算法的AI應用案例
機器學習中的無模型強化學習算法及研究綜述

7個流行的強化學習算法及代碼實現
7個流行的強化學習算法及代碼實現

模擬矩陣在深度強化學習智能控制系統中的應用






 工商網監
工商網監
評論