


編者按:上篇文章中,我們提到了如何高效地訓練ResNet。在今天的文章中,我們將對mini-batch的尺寸進行研究,同時要考慮遺忘性問題。
在上一篇文章中,我們得到了一個18層的ResNet網絡,測試精度達到94%需要341秒,并且經過進一步調整后,時間縮短至297秒。
目前,訓練使用的batch大小是128,batch更大,就支持更高效的計算,所以我們想試試當batch增大到512會發生什么。如果我們想估計之前的設置,就需要保證學習率和其他超參數都經過合適的調整。
具有mini-batch的隨機梯度下降幾乎是每次只訓練一個樣本,但不同的是,參數的更新會延遲到batch結束。在低學習率的限制下,你可以認為這種延遲是更高階的效應,只要梯度只在mini-batch上求和而不是計算平均數,批處理就不會改變任何一階的順序。我們還在每個batch之后應用了權重衰減,它會通過batch size中的一個因素增加,從而抵消需要處理的batch數量。如果梯度根據mini-batch被平均,那么學習速率應該增加到可以消除這一影響只留下權重衰減,因為權重衰減的更新對應著學習率的因子。
所以現在我們將batch size定為512開始訓練。訓練時間為256秒,將學習速率增加10%,在128的batch size下,3/5的訓練都能達到94%的測試精確度。如之前所料,在512的batch size下,驗證結果有更大的噪聲,這是因為批規范化的影響。
現在速度增加的很好,但是結果讓我們很吃驚
考慮到要用不同的mini-batch進行訓練,我們認為這一過程中我們忽略了兩點。首先,我們認為延遲更新,直到這一mini-batch結束都是更高階的影響,這在較低的學習率中是可行的。目前配置中的快速訓練速度很大程度上取決于高學習率的使用。在凸優化的背景下(或僅僅是二次方的梯度下降),我們可以在某一點設置學習速率,達到最大的訓練速度,在這一點處,二階效應開始平衡一階效應,并且一階步長產生的益處可以通過曲率效應抵消。假設我們處于這種狀態mini-batch導致的延遲更新應該產生相同的曲率懲罰,因為學習率的增加,訓練會變得不穩定。簡而言之,如果可以忽略高階效應,就說明訓練速度不夠快。
另外,我們發現訓練步驟只有一個,但事實上,訓練是一個很長的運行過程,要改變參數就需要好幾個步驟。所以,小的batch和大的batch訓練之間的二階差異可以隨著時間積累,導致訓練軌跡有很大不同。在之后的文章中我們會重新討論這一點。
所以,我們該如何在限制訓練速度的情況下,還可以提高batch size,同時不用維持曲率效應帶來的不穩定性?答案可能是其他因素在限制學習速率,而我們并沒有考慮到曲率效應。我們認為這一其他因素就是“災難性遺忘(Catastrophic Forgetting)”,這也是在較小batch中限制學習率的原因。
首先,我們要對這一概念進行解釋。這一術語通常用于,當一個模型在一個任務上訓練后,又應用到第二第三個模型上。但是學習之后的任務會導致性能下降,有時這種影響是災難性的。在我們的案例中,這些任務是來自同一個訓練集的不同部分,所以單單在一個epoch中就會發生遺忘現象。學習速率越高,訓練中參數所用的越多,在某一點時這會削弱模型吸收信息的能力,早期的batch就會更容易遺忘。
當我們提高batch size時,并沒有立即增加模型的穩定性。如果是曲率導致的,穩定性會利可增加。反之,如果是遺忘是主要原因,模型不會受batch size的影響。
之后,我們進行了實驗將曲率的效應和遺忘性區分開。曲率效應大多依賴于學習率,而遺忘主要受學習率和數據集大小的共同影響。我們繪制了在batch size為128時,訓練和測試損失的折線圖,訓練所用的是不同大小的子集。
可以看到,首先,訓練和測試損失都在學習速率為8的地方突然變得不穩定,這說明曲率影響在這里變得非常重要。相反,其他地方的訓練和測試損失都很平穩。
如我們所料,優化學習速率因子(由測試集損失測定)和全部的訓練數據集中的優化學習速率因子很接近。對于更小的數據集來說,優化學習速率因子更高。這也符合我們上面的假設:對于一個足夠小的數據及來說,遺忘就不再是問題了,學習速率才是問題。對于更大的數據集,在遺忘的影響下,優化點會更低。
同樣,在batch size為512的情況下,曲線圖也很有趣。由于batch size比上方的大了4倍,曲線出現不穩定情況的速度更快了,當學習速率為2時即出現。我們仍然希望,學習速率因子的優化值和損失與128時的相近,因為遺忘并不對batch size產生影響。以下是得到的結果:
我們設置batch size=128,然后用一定學習速率訓練,在前五個epoch中線性增加,之后達到固定的速率并繼續訓練25個epoch。我們在兩個數據集上進行了比較:a)50%的完全訓練集沒有經過數據增強;b)全部數據都經過增強的數據集。當模型在b上運行時,我們將它停止,重新計算最后幾個epoch的損失,這樣做的目的是比較模型在最近的數據上得到的損失和此前數據上計算出的損失。
以下是學習速率是原始訓練時4倍的結果:
以下是原始訓練是現在學習速率4倍的結果:
從第一組圖表中,我們發現,與高學習速率相對應,測試損失幾乎和模型在a、b上訓練時的結果一樣。這說明,訓練無法從b和a中提取信息。右邊的圖也證明了這一結果,最近訓練的batch表現出比此前的batch更低的損失,但是在半個epoch之內,損失又恢復到模型在從未見過的測試樣本上的水平。這說明,模型忘記了在同一個epoch中它此前看到的東西,這也說明這一學習速率限制了它能吸收到的信息。
第二組圖表表現出了相反的結果。全部經過數據增強的數據集導致了更低的測試損失,最近的訓練batch比此前表現得更好。
結語
上述結果表明,如果我們想訓練一個擁有較高學習速率的神經網絡,那么就要考慮兩點。對于目前的模型和數據集來說,在128的batch size下,我們不會受到遺忘的影響,要么可以找方法降低影響(例如用更大的、伴有稀疏更新的模型或者自然梯度下降),要么可以增大batch size。當batch size達到512時,曲率就開始影響結果,我們關注的重點應該轉移到曲率上來。
對于更大的數據集,例如ImageNet-1k,遺忘的影響會更嚴重。這就能解釋為什么在小的batch size、高學習率的訓練中加速會失敗。
在接下來的文章中,我們會加速批規范化,加入一些正則化,同時替換另一種基準。
-
數據集
+關注
關注
4文章
1224瀏覽量
25480 -
resnet
+關注
關注
0文章
13瀏覽量
3324
原文標題:如何訓練你的ResNet(二):Batch的大小、災難性遺忘將如何影響學習速率
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
影響閃存遺忘的主要因素

*** 災難性故障,求救,經驗分享
AD畫圖出現“災難性故障 (異常來自 HRESULT:0x8000FFFF (E_UNEXPECTED))”
理解Batch Normalization中Batch所代表具體含義的知識基礎
在沒有災難性遺忘的情況下,實現深度強化學習的偽排練

實現人工智能戰略性遺忘的三個方法
DeepMind最新研究通過函數正則化解決災難性遺忘

batch normalization時的一些缺陷
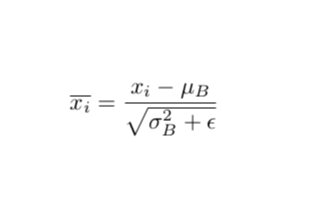





 工商網監
工商網監

評論