 一種基于智慧運營平臺,將大數據技術和數據挖掘技術相結合
一種基于智慧運營平臺,將大數據技術和數據挖掘技術相結合
【摘要】? 為減少用戶流失,提高用戶保有率,文章介紹一種基于智慧運營平臺,將大數據技術和數據挖掘技術相結合,對電信客戶流失進行預測的模型。該模型利用大數據技術處理用戶離網前的海量數據信息,分析流失用戶特征,建立用戶流失預測,提前鎖定流失風險較高的用戶,有針對性地制定維挽策略,精準開展維系挽留活動,能夠有效降低用戶離網率。
引言
隨著移動通信成本逐步下降,移動用戶滲透率超過100%,新增市場趨于飽和,面對新增市場的激烈競爭,存量用戶的保有顯得越來越重要。一項調查數據表明,爭取1位新客戶的成本是保住1位老客戶的5倍。面對新的競爭形勢,運營商需要從傳統只重視增量發展模式向“增存并重”發展模式轉變。如何最大限度地降低客戶的流失并挽留客戶,成為決策者關注的話題。
客戶流失給運營商帶來了巨大損失,成功挽留一個即將流失的客戶比重新發展一個客戶節約大量成本。減少客戶流失的關鍵是提前預測潛在的流失客戶,采取相關措施提高客戶的滿意度,實現該預測的關鍵是數據挖 掘[1]和大數據技術。基于大數據技術的數據挖掘就是從海量的客戶資料、使用行為、消費行為、上網軌跡等信息中提取有用的信息進行組合關聯,準確判斷客戶流失的現狀或傾向,可以讓企業及時并有針對性的對客戶進行挽留[2];因此,利用大數據技術進行數據挖掘,預測客戶流失、減少客戶流失的發生成為電信行業研究的重點。
1國內外研究現狀
在數據挖掘方面,國外有很多案例和做法值得學習,比如:文獻[3]中運用決策樹、Logistic回歸、 人工神經網絡等算法建立了移動用戶流失預測模型。 Lightbridge[4]公司運用CART算法分析了新英格蘭的一 家移動服務商的數據并建立了客戶流失模型AT&T 公司很早就開始在大數據上的探索[5],2009年開始與 Teradata公司合作引進天睿公司的大數據解決方案。
在過去的幾十年中,中國企業都扮演著技術跟隨者的角色,現階段我國互聯網企業在數據挖掘、大數據處理以及人工智能、云計算等領域都有了巨大的發展。 比如文獻[6]中使用K-means聚類算法對電信客戶進行細分,在此基礎上探索了客戶細分在營銷中的實際應用。 文獻[7]中利用神經網絡算法建立用戶流失預測模型,分析用戶流失特征。文獻[8]中利用Spark平臺實現了多種神經網絡算法,對用戶流失問題提出了快速精確的模型。國內的電信企業雖然都建立了客戶流失預測、客戶 分群等模型,但大多都是基于數據挖掘軟件如SPSS、SAS等應用,使用的數據量有限,不能全面分析用戶流失行為。
2大數據平臺及技術
安徽聯通構建基于B域、O域和M域數據融合的大數據平臺——智慧運營平臺,實現數字化轉型及全業務流程的智慧運營。智慧運營平臺通過企業級大數據平臺 實現企業全量數據的接入及治理,當前包括Hadoop、 Universe、實時流處理三大資源池,共計140多個節 點,存儲容量3PB、2200核CPU、8T內存計算資源,實現資源動態管理;流處理平臺具備百萬級別消息并發 處理能力,支持1分鐘級別提供用戶位置能力(見圖1)。
智慧運營平臺接入BSS、CBSS、OSS、SEQ、上 網等全網多種數據源,利用BDI(Big Data Integration, 數據集成套件)和Flume進行離線數據及日志數據的抽取、轉換、加載等數據采集功能,實現高性能海量數 據處理和存儲。利用Hadoop、Universe、實時流處理三大資源池,有效支撐上層各種應用的開發和運行。利用基于大數據分析平臺構建的新一代智能數據挖掘系統 SmartMiner進行自動化數據挖掘,實現各種算法模型的訓練和預測。借助智慧運營平臺強大的大數據分析和處理能力,結合現網客戶運營的經驗,建立有效的用戶流失預測模型,實現用戶的流失預警、維系策略匹配、客戶反饋優化等一整套流程,能夠有效降低用戶流失。
3離網預測模型構建
3.1離網預測原理
離網預測模型[9]主要是根據歷史數據特征,通過數據挖掘算法,建立預測模型,并將模型應用于現網用戶,預測出離網概率高的用戶。其主要包括數據準備、 模型訓練和驗證、離網預測三大部分[10]。如圖2所示,數據準備階段,根據出賬和充值規律定義離網規則,通過對電信業務和用戶行為的理解,從運營商各域數據里提取數據,并篩選離網預測特征字段,構建離網預測特征庫。模型訓練和驗證階段,選取數據挖掘算法,進行模型訓練、評估和調優,訓練出最佳模型。離網預測階段,將訓練的最佳模型應用于現網數據,實現準確的流失預測。進一步通過有效的維系手段,對預測流失用戶進行精準維系,減少用戶離網,提升在網用戶價值。
3.2隨機森林算法
傳統數據挖掘中進行流失預測多采用決策樹算法[11],它的特點有訓練時間復雜度低、預測的過程比較快、模型容易展示等。但是單決策樹容易過擬合,雖然可以通過剪 枝等方法減少這種情況的發生,但仍有不足。2001年Leo Breiman在決策樹的基礎上提出了隨機森林算法[12]。
隨機森林是由多個決策樹構成的森林,算法分類結果由這些決策樹投票得到,決策樹在生成過程中分別在行方向和列方向上添加隨機過程,行方向上構建決策樹 時采用有放回抽樣(bootstrapping)得到訓練數據,列方向上采用無放回隨機抽樣得到特征子集,并據此得到其 最優切分點。從圖3中可以看到,通過K次訓練,得到K棵不同的決策樹{T1,T2,…,TK},再將這些樹組合成一個分類模型系統,隨機森林是一個組合模型,內部仍然是基于決策樹,同單一的決策樹分類不同的是,隨機森林通過多個決策樹投票結果進行分類,算法不容易出現過度擬合問題。
3.3 數據準備
3.3.1 離網定義及數據需求
為了進一步提前鎖定離網傾向用戶,經過歷史數據的比對,結合用戶使用行為的分析,決定將過繳費期10天未繳費的用戶定義為流失用戶。根據傳統數據挖掘實現的離網預測案例的經驗,考慮到大數據系統的處理能力,通過對連續3個月內離網的用戶進行離網打標,增加離網用戶的樣本量,提高離網預測的準確率;通過對目標用戶中隔月后離網的用戶進行打標,預留1個月的 預測結果干預期,進行維系挽留。如圖4所示,采用連續7個月的歷史數據,對第N-6月的數據進行隔月后的連 續3個月(N-4月、N-3月、N-2月)離網用戶打標,取N-6 月、N-5月、N-4月連續3個月的正負樣本并集,解決了傳統打標負樣本量不足和維系干預期太短等問題。
3.3.2數據特征提取
根據業務經驗,選取與用戶流失可能存在相關性的所有屬性,進行數據審查,篩選存在相關性較大的特 征屬性。本次建模數據特征主要采用B域用戶通信及消 費行為等基本屬性、衍生屬性(匯總、比例、趨勢和波動)、挖掘屬性等,增加O域樣本數據,如上網行為、 終端屬性指標(換機、應用偏好、掉話率、上網協議響 應成功率等)。如表1所示,數據維度包括基礎信息維度、通信行為信息、賬務信息、消費行為變化維度、交往圈信息、呼叫異網維度、投訴維度、通信行為維度及上網軌跡、掉話率等。根據這些維度數據合并匯總成數據挖掘特征寬表,用于模型訓練和驗證。

3.4建立模型
流失客戶預測模型的建立,具體包括原始數據處理、特征寬表構建、模型訓練、模型評估和模型調優五個部分。如圖5所示,智慧運營平臺通過連接全網數 據的接口,獲取建模所需的BSS系統(業務支持系統)數 據和OSS系統(運營支持系統)數據。BSS系統是運營商 向用戶開展業務的主要IT組成部分,OSS系統是電信服務提供商用來管理通信網絡的主要系統。BSS數據包括 CRM(客戶關系)、Billing(賬單數據)、詳單數據及投訴數據,OSS數據包括分組交換數據(Package Switch, PS)、測量報告數據(Measurement Report,MR)和電路交換數據(Circuit Switch,CS)。其中PS數據描述了用戶連接網絡的情況,如上網速度、掉線率和移動搜索文本 信息;MR數據可以用來給用戶定位,獲取用戶運動軌跡;CS數據描述的是用戶的通話質量,如掉話率等。
我們將獲取的原始數據存儲到Hadoop分布式文 件系統中(HDFS),然后再利用Hive進行特征生成和處理工作。HDFS可以處理PB級別的超大文件,Hive可 以提供簡單的SQL查詢功能,并能將SQL語句轉化為 MapReduce任務分布式運行。
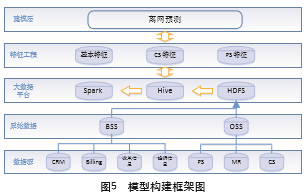
特征寬表生成后,我們利用Spark的高效計算能 力,在SmartMiner中選取隨機森林算法進行流失預測模型的訓練,經過訓練結果的多次驗證和評估,我們將 隨機森林設置為200顆樹,SQR采樣方法,樹的最大深 度為15層,葉子最小樣本數100個,最大分箱數32,進行模型建立。將分類器訓練出來的模型應用到現網數據,可以預測未來3個月有離網傾向的用戶,按照離網傾向的高低排名,鎖定維系挽留的目標客戶。
3.5模型評估
訓練模型的好壞可以通過對歷史流失數據的檢驗來驗證,模型評估參數一般包括準確率和覆蓋率,準確率越高、覆蓋率越大,模型效果越好,其中:準確率=預測流失準確的客戶數 / 預測為流失的客戶數;覆蓋率=預測流失準確的客戶數 / 實際流失的客戶數。
如圖6所示,我們根據建模訓練數據的規則,可以在第N月預測第N+2月、N+3月、N+4月的流失用戶, 第N+1月為我們的維系窗口期。
我們選取2016年1~6月數據進行訓練,對7~10月數據進行模型預測,如圖7所示,經過2016年9月至 2017年2月數據的驗證,可以得到7~10月的預測數據 TOP50000中查準率基本在80%,查全率40%。
4離網根因分析
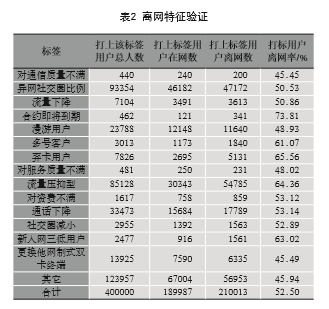
通過對離網用戶的特征屬性進行聚類分析,離網用戶大致原因可以分為:資費原因、合約感知原因、社會交往影響原因、終端換機原因、地域變更原因、服務質量原因、通信質量原因、棄卡原因、新入網質量原因及其他原因等。如表2所示,提取2016年11月數據預測2017年1~3月離網概率top400000用戶,對其離網情況進行驗證,其準確率達到52%以上。
5應用
5.1策略匹配
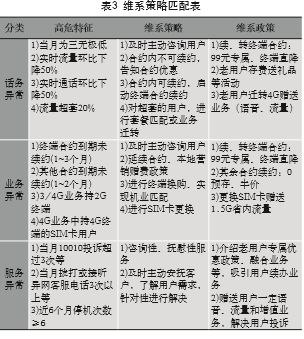
通過對流失用戶的根因分析,結合現有維系業務,將預測的離網用戶,根據業務特征進行分類,匹配相應策略指導市分VIP維系客戶經理進行外呼維系。如表3所示,將離網傾向較高的用戶分為話務異常、業務異常和服務異常三類,針對話務異常用戶,重點進行優惠活動介紹,增加用戶黏性;對于業務異常用戶,推薦合約 續約及更換SIM卡;對于服務異常用戶,進行及時安撫并給予一定贈送。
5.2維系效果
針對三星級以上用戶,我們利用在網維系系統進行了針對性的維系挽留。從2017年1月開始,我們將大數據系統預測出的離網傾向較高的高價值用戶通過在網維系系統下發到市分VIP客戶經理處,根據匹配的策略進行精準維系。如圖8所示,2015年9月至12月,高價值 用戶準離網率平均值為2.04%,全網準離網率為3.6%。 模型應用后,高價值離網率從2017年2月開始持續降低,如圖9所示,截至2017年7月下降到1.35%,平均準離網率為1.49%,相比應用前的2.04%下降了0.55%, 每月多挽留客戶8230戶,高價值戶均ARPU按90元計算,月均減少損失74萬元,年減少損失888萬元。
6總結
本文闡述了利用智慧運營大數據平臺,對流失客戶的特征進行的分析和研究,利用SmartMiner分析系統選取隨機森林算法,建立客戶流失預測模型,通過多次的訓練和優化,逐步提高流失預測模型的準確性。通過對離網用戶的根因分析,制定相應維系策略,匹配到相應的離網傾向用戶,在全網進行了系統化的精準維系,有效提升了用戶保有率。下一步將結合維系效果,繼續優化模型參數,完善訓練模型,進一步提升流失預測的準確率和覆蓋率,繼續研究用戶流失根因,根據離網根因匹配維系策略,進一步降低用戶流失,增強用戶黏性,提升客戶價值。
-
數字化
+關注
關注
8文章
8708瀏覽量
61726 -
數據挖掘
+關注
關注
1文章
406瀏覽量
24232 -
大數據
+關注
關注
64文章
8882瀏覽量
137397
原文標題:【集客經營】基于大數據技術的電信客戶流失預測模型 研究及應用
文章出處:【微信號:xiacoinfo,微信公眾號:資治通信】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論